论文信息 ¶
Maris, E., & Oostenveld, R. (2007). Nonparametric statistical testing of EEG- and MEG-data. J Neurosci Methods, 164(1), 177-190. doi:10.1016/j.jneumeth.2007.03.024
论文原文 ¶
关键词 ¶
EEG/MEG统计分析
摘要 ¶
作者这篇文章主要介绍了EEG和MEG的非参数检验的一种方法,可以比较好地解决多重比较的问题(MCP)。我的理解就是:对于每个电极上的每个时间点都随机分配其标签,然后再次形成聚类,把形成的聚类的t值之和计算出来,这样重复1000次,然后把所有形成的聚类的统计量形成一个分布,来看我们的原始的标签的聚类位于这些聚类的哪个位置,是否在边缘从而来看显著不显著
引言 ¶
在M\EEG数据分析中常常面对多重比较问题,这种问题通常来源于感兴趣的效应通常以是用特别大量的电极\时间对来评估的,通常都是几千。因此就会出现问题,这种大量的比较就会使家系错误(FWER)的概率不可控。例如对每个采样点进行一次t检验,整体出现错误的可能性就会上升,因此如果进行这类参数检验,就需要进行矫正,例如bonferroni。因此为了解决这类问题,作者就提出了使用非参数检验的方法,这样可以避免家系错误。
方法 ¶
作者用句末词的语义一致性作为实验条件,分为合理和不合理两个条件。句末这个名词是否语义合理就会导致脑电上的区别。 作者拿了一个被试的脑电数据来分析,比较两个不同条件下的区别是否显著。作者将每个电极下的两个条件或者每个时间点下的两个条件作为一个sample。 当我们知道哪个电极和时间会观察到这类效应的时候,分析其实是很简单的,直接进行一次t检验和相应的p值就足够了。而当不知道这些信息的时候,那么进行很多次t检验不现实,因为我们很难控制多重比较问题。因此需要考虑其他的办法。 evoked response是一种指标,而相应的,神经振荡活动也是另一种指标,通常是把完整的数据切割成小的时间窗进行功率估计来计算出的。而和evoked response一样,神经振荡通常也需要先前的知识,所以作者着重介绍了非参数检验来解决诸多问题。 步骤如下:1. 把两个条件下所有的trial放在单个集合里。2. 随机抽取条件1的trial那么多的随机trial放进子集1,剩下的放进子集2.这个过程称为随机分区。 3. 计算这个随机分区的统计量。4. 重复2和3,并绘制出统计量的直方图。5. 根据观察到的统计量和直方图,计算出p值。6. 如果p值小于alpha水平,那么就说两种条件下显著不同。 这里插入一下permutation-cluster-test的步骤: 排列聚类检验(Permutation Cluster Test)的过程可以通俗地描述如下: 1.数据准备:首先,我们需要有两组或多组实验条件下的数据,例如,在神经科学研究中,可能是不同刺激条件下的脑电或磁共振成像数据。 2.计算测试统计量:对于每一个时间点(或空间位置),使用适当的统计方法(例如t检验)来比较不同条件下的数据。这将生成一系列的测试统计量,如t值。 3.阈值设定:选择一个阈值来确定哪些测试统计量是显著的。通常,这个阈值是基于特定的显著性水平(如0.05)设定的。 4.形成聚类:将相邻并且超过阈值的时间点(或空间位置)聚合成聚类。在时间序列数据中,这意味着连续的时间点可以形成一个聚类;在空间数据中,则是空间上相邻的点。 5.计算聚类级别的统计量:对每个聚类,计算一个聚类级别的统计量,通常是聚类内所有单独统计量(如t值)的总和或平均值。 6.排列检验:现在进行排列测试以获取基准分布。这涉及到多次随机重排条件标签,并对每次重排后的数据重复步骤2至5。这将为每个聚类生成一个基于随机排列的分布。 7.计算p值:对于原始数据中的每个聚类,计算其统计量在排列生成的分布中的位置,以得到一个p值。这个p值表示在没有实际差异的假设下(即,如果原始标签和排列标签没有区别),观察到至少这么极端聚类的概率。 8.结果判断:最后,比较每个聚类的p值与预定的显著性水平(如0.05)。如果p值小于这个显著性水平,那么我们拒绝零假设(即,认为该聚类表示实际的统计显著差异)。 从而根据p值拒绝原假设。这种就被称为排列检验。在作者的文中是需要计算1000次随机分区。这种非参数检验不依赖于数据自身的分布是否正态,也不依赖其他统计量。它能够解决多重比较问题。
结果 ¶
这是作者对单个电极每个采样点进行分析的结果,采用了不同的方法
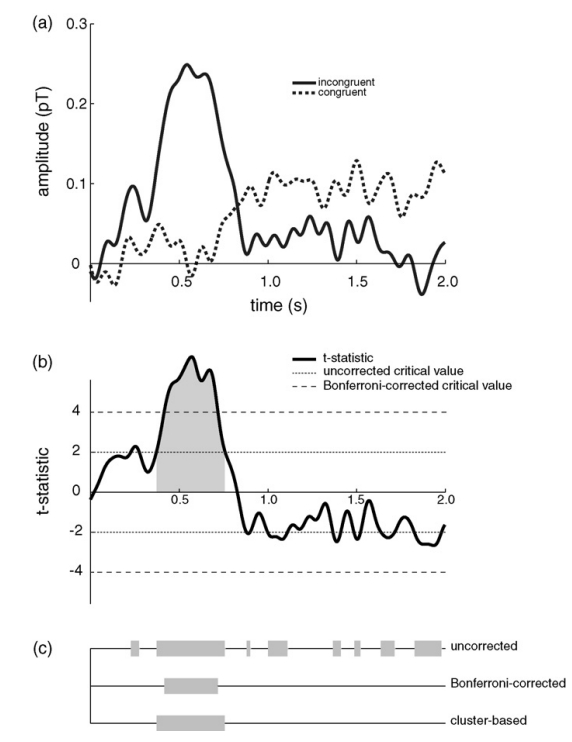
选择所有t值大于某个阈值的样本点。这个阈值可能基于t值在零假设下的抽样分布,也可能不基于,但这不影响非参数检验的有效性。
基于时间邻近性将选中的样本点聚合成连续的集合,即聚类。
计算每个聚类的聚类级别统计量,通常是聚类内所有t值的总和。
从所有聚类中选出聚类级统计量最大的一个。
接下来,非参数检验的关键步骤在于使用这个最大的聚类级统计量进行排列测试。具体来说:
将两种试验条件的数据合并,然后随机分配到两个新的子集中,以此方式创建大量的随机数据集。 在每个随机数据集上重复之前的聚类过程,计算新的聚类级统计量。 创建这些随机聚类统计量的分布,并将原始数据中最大的聚类级统计量与这个分布进行比较,以计算出一个p值。 这个p值表示在没有实际效应的情况下(即在零假设为真的情况下),观察到一个等于或更极端(即更大或更小,取决于检验的方向)的聚类级统计量的概率。
如果这个p值低于预定的显著性水平(例如,0.05),则可以拒绝零假设,从而认为在两种试验条件之间的MEG信号中存在统计上显著的差异
拿这个图来说,根据第一列看,有8个clusters,而根据permutation cluster test来看,只有这一个cluster的p值小于0.025(双尾)。
而这些上面的都是单电极的情况,在多个电极的情况下,多重比较问题更显著,例如如果有151个电极和600个采样点,那么就有90600个t值,矫正后p太太小了,而相反的cluster-based permutation test就很敏感了。而多个电极的cluster test和单电极的实际上差不多,唯一区别就是cluster不再是时间上的相邻,而是基于时间和空间上的相邻。 后续就是讲的神经振荡部分的内容了。
对多个被试进行的非参数检验 ¶
需要把每个subject的各条件的trial平均,然后相较于单被试的非参数检验,多被试的就是根据特定被试的trial平均来做的。 对于被试内研究: 每位被试对每个实验条件都有一个特定的平均值(subject-specific average)。假设只有两个实验条件,那么对于第r个被试,其特定的平均值可以表示为一对 (Dr1, Dr2),其中Dr1代表在第一种实验条件下观察到的数据,Dr2代表在第二种实验条件下观察到的数据。
在计算基于聚类的检验统计量时,样本特定的统计值是从成对样本(依赖样本)公式得出,而不是在被试间研究(between-subjects study)中使用的独立样本t值。计算的其他部分则相同。
排列分布的构建在被试内研究与被试间研究有所不同。在被试内研究中,不是随机置换被试(使它们与不同的实验条件相关联),而是在每个被试内随机置换特定的平均值 (Dr1, Dr2)。此外,这种随机排列对每个被试都是独立进行的。对于n个被试,这导致了一个排列分布,其中包含2^n个可能的值,这些值在零假设下都是等可能的。
然后,通过将观察到的检验统计量与这个排列分布进行比较来获得p值。这样,如果有n个被试,就会有2^n种可能的排列组合。
在被试内MEEG研究的兴趣假设是关于不同实验条件下被试特定平均值的概率分布。排列检验的零假设涉及这个联合分布是可交换的,即f(Dr1, Dr2) = f(Dr2, Dr1)。这意味着如果两个实验条件的边际分布f(Dr1)和f(Dr2)不相等,则违反了零假设。 在多被试MEEG研究的排列检验中,关键的操作是针对每一组特定的(传感器,时间)样本来执行测试。这个过程涉及以下主要步骤:
选取样本:首先,对于每一对实验条件,比如语义一致和语义不一致的句子结尾,在每个时间点上计算每个传感器的效应大小(例如,通过t值)。这意味着你会针对每个传感器和每个时间点测量条件之间的差异。
形成聚类:然后,基于空间和时间的邻近性,选取超过某个阈值的样本(即传感器,时间点),并将它们聚合成聚类。在这个过程中,如果两个(传感器,时间)样本在空间上接近(例如,两个传感器的距离小于4厘米)并且在时间上相连,则它们可以被归入同一个聚类。
聚类统计量:对于每个识别出的聚类,计算一个聚类级别的统计量,例如,该聚类内所有样本的t值之和。
蒙特卡洛p值:通过在空假设下随机置换样本标签来生成聚类统计量的分布,并比较实际观察到的聚类统计量与这个随机分布,以计算每个聚类的蒙特卡洛p值。 所以对于每个电极上的每个时间点都随机分配其标签,然后再次形成聚类,把形成的聚类的t值之和计算出来,这样重复1000次,然后把所有形成的聚类的统计量形成一个分布,来看我们的原始的标签的聚类位于这些聚类的哪个位置,是否在边缘从而来看显著不显著