论文信息 ¶
Martin, C. D., Thierry, G., Kuipers, J.-R., Boutonnet, B., Foucart, A., & Costa, A. (2013). Bilinguals reading in their second language do not predict upcoming words as native readers do. Journal of Memory and Language, 69(4), 574-588.doi:10.1016/j.jml.2013.08.001
论文原文 ¶
关键词 ¶
预测;二语者;N400
摘要 ¶
阅读过程中,单语者总是积极预测即将到来的词,因此作者想看看二语者用第二语言阅读时,是否能够预测句尾的词。作者记录单语者和二语者在阅读句子时的ERP,这些句子要么是以预期词结束,要么是以意外词结束。而词汇预测由名词前冠词处的N400效应显示,N400越负,说明对句末词预测越少。相比于单语者,双语者未能在意外冠词处显示出更大的N400幅度。作者将这种结果解释为二语者在句子理解过程中没有积极地预测即将到来的词,这种在词汇预测上更差可能是语言加工阶段总体上更慢、准确率更低的结果。
引言 ¶
关于预测的介绍不再赘述。这里提出有研究表明,第二语言熟练度较低,会导致N400效应出现延迟,这表明了,用L2阅读时,语义加工会比用L1阅读更慢。因此作者想看二语者阅读时的词汇预测情况以及预测效应是如何影响语义加工的。 但N400实际上无法把主动的词汇预测机制和被动的整合区分开来,遇见了意外词,我们也并不知道究竟是哪种机制导致的N400更负。而关于语义加工实际上由两种过程调制:1. 当我们阅读词的时候,词就被加工和整合了,当句子开始呈现,读者逐级地构建关于语义的信息层面的表征,而句子中的词就基于这些表征被整合,一个词的意义越符合信息层面的表征,它的语义整合越容易。而根据被动共振假说,句子中的词会激活与其语义相似的网络,因此当某个词是这个语义网络的一部分时,这个词的加工就被促进了。2. 读者能够基于语境信息来生成对目标词的预测。上述三种解释在作者看来并不冲突。 这时候又介绍了经典的prenominal研究,表明了我们确实是在积极地预测。同时,这里也提到了重要地PNP,可能反映了抑制强烈预测所需要的花费。因此这种PNP也为主动的词汇预测提供了证据,同时作者在这里提到这种PNP对于研究读者是否尝试或者是否错误预测十分关键,作者的意思是:如果没有预测,甚至就没有PNP,这似乎是一个检验标准?PNP发生在当主动预测了预期词但是这个词却没有出现的情况下。 作者在这里提到,目标名词处的N400的幅度会受到被动整合和主动预测的同时影响。而在目标名词前冠词处的N400则只能被主动的词汇预测机制来解释。 其实之前还有用眼动研究L2的语义加工的,发现当词被插进高度限制的上下文中时,即使那些不太熟练的二语者,阅读也被促进了。但实际上我们并不知道这种促进是整合还是预测,因此作者想看看有没有促进的作用。
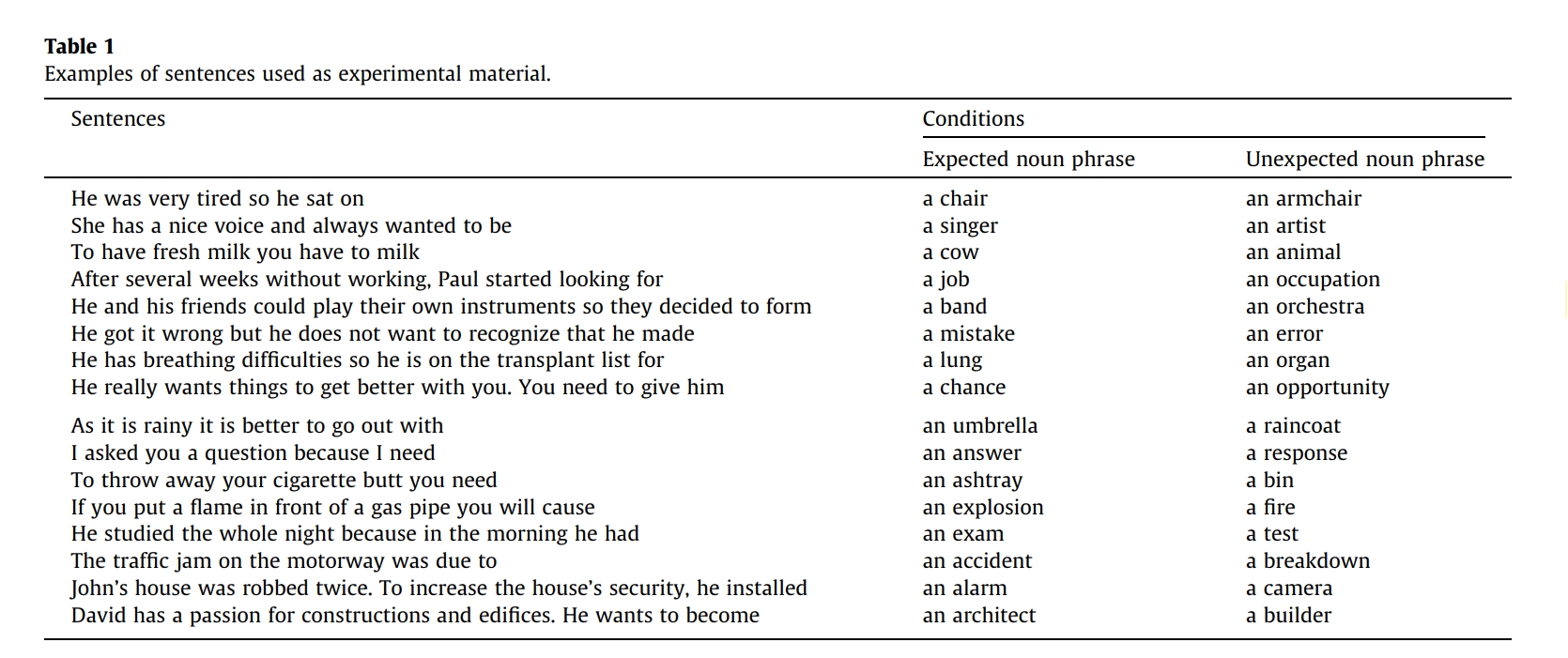
材料设计和实验 ¶
作者认为的预测的指标:1.冠词处的N400 2.名词处的PNP。对于名词处的N400,它可能反应了预测+整合一起,所以不看。 材料包含四种条件: 1.目标词是元音开头,然后冠词是a/an,2.目标词是辅音开头,然后出现a/an。作者的预期是在冠词和名词部位都有N400效应,同时还预期在末尾名词部分有PNP效应。对于二语者,作者猜想可能不会像单语者那么有效地预测,有两种可能性:1.二语者预测得更慢,因为语言加工更加慢更困难,也就是说他们能预测具体词,但是太晚了以至于不能影响句子加工,因此在冠词处可能观察不到N400效应,但是名词部分仍有PNP。2.第二种认为,二语者的句子理解完全依赖于被动的整合机制,或者是被动的共振机制,在这两种情况下,关键词会基于工作记忆中储存的上下文信息被整合,而没有预测,根据这种解释,不会在名词和冠词上观察到任何预测效应,但名词上仍有N400,因为预测词始终比非预测词好整合,虽然预测效应不在了,但整合还在。 被试:19个英语母语者和19个西-英双语者(后习得英语)。 实验材料:包含了80个句子语境,其中40句,预测名词以元音开头,而意外词以辅音开头,另外40句,预测名词以辅音开头,而意外名词以元音开头,因此共160个句子,分为了两个list,每个被试只看一个list,比较重要的是,所有的句子都是语义和语法上合理的,句子末尾的词都没有语义违反,只有预测程度的区别。 同时,招募的二语者都已经生活在UK很久,所以不会有不知道a/an和后续名词搭配规则的情况,西语本身也有性的变换,这也保证了冠词处预测的发生。作者还检测了a/an和后续名词不搭配时,后续名词处有没有P600,发现是有的。 作者还用了每ms的配对样本t检验来看差异时间段,可以参考。
结果 ¶
而在名词位置,所有的效应都是显著的,因此又分了三个区域分别做ANOVA。1.前部区域,显著的预期和组别的主效应,交互作用显著,同时也只有L1有显著的预测效应,对于意外名词才有组别效应,而预期名词里L1和L2两组没有显著差异。2.中部区域,和前部区域差不多,但L1和L2都有预测效应,只是L1更大。3. 后部区域,和前面差不多,同时也是L1预测效应显著,L2轻微显著。 而对于名词处的PNP只发现了区域的主效应和区域×预测的交互作用,又分区域研究。对于前面,PNP的预测有显著主效应,也有显著交互作用,但是组别没有显著主效应,L1有PNP上的预测效应而L2没有(即意外的词PNP更大)。对于中间区域,没有显示出任何显著的效应。对于后面的区域,也没有显示出任何效应(难怪叫anterior negativity)。
讨论 ¶
作者这篇文章的主要目的就是看L2能不能像读L1一样,预测目标词。基于观察到的模式,作者认为二语者读二语的时候不能像L1一样积极地预测即将到来的词。同时对于意外冠词的N400幅度,L1是最大的,这也显示了当读者积极预测目标名词时所需的更多努力。 因此结论可能是:1.L2读者预测得更慢,因此在冠词处不足以观察到显著效应。但这种情况下名词处得PNP应该还在,为何没有?2.L2读者根本不预测,仅仅依靠被动整合,因此L2名词处也不会有PNP。 作者接下来讨论了N250和PNP这两个成分。在L2里有N400,因为仅仅是整合也会有N400。但没有出现N400的出现时间向前移动,同时两个条件N400幅度的差异也更加小,同时,没有出现PNP。作者解释了这些如何支持了L2的预测不如L1。