论文信息 ¶
Michaelov, J. A., Coulson, S., & Bergen, B. K. (2023). So Cloze Yet So Far: N400 Amplitude Is Better Predicted by Distributional Information Than Human Predictability Judgements.* IEEE Transactions on Cognitive and Developmental Systems, 15*(3), 1033-1042. doi:10.1109/tcds.2022.3176783
论文原文 ¶
关键词 ¶
预测;N400
摘要 ¶
越容易预测的词越容易加工——它们读的更快并且引发与加工困难相关的更小的神经活动,最显著的就是N400。因此普遍认为预测即将到来的词是语言理解中的一个关键部分,N400幅度相关研究就是关于预测的重要研究。而在该研究,作者讨论了,大语言模型产生的语言预测和人类自身产生的语言预测,究竟哪一种更好地调控了N400幅度。人类和大语言模型产生的语言预测最大的区别就是,语言模型是完全基于前面的语言语境来产生预测,而人类可能还会依赖其他因素。作者选用了三种语言模型GPT3,Roberta,ALBERT,发现它们比人类预测更符合N400(?)。这可能表明了N400对于语言的统计比之前认为的还要更敏感。
引言 ¶
语言预测中有许多不同观点:1. 一种观点认为我们不会消耗资源来进行预测加工,因为任何给定语境,都有可能出现无限多的词,因此语言预测肯定错的时候比对的时候多得多,因此可能不会预测,这种观点把N400或者其他预测现象解释为了词的意义整合到语境里的难易程度。2. 而N400的研究越来越多,至少在一些实验里,研究者认为N400效应反应的不是整合的难易,而是反应预测了出现词还是没有。而这些实验主要就是通过完型填空概率来完成的。 最近用语言模型LM来调控完型填空概率,语言模型仅仅通过输入的文本数据训练,因此仅仅依靠语言的统计。因此人类的预测可能会基于各种语言内和语言外的知识,而LM基于它们训练的语料库来获得一个语境中词的分布概率。因此,靠LM我们有了一个纯靠语言输入来预测N400的幅度。另一方面我们也不知道让被试来做完型填空会有什么策略或者有什么神经活动。 当前研究的目的是为了测试句子上下文中单词N400幅度是否能够更好地被语言的统计预测,还是更好地被完型填空概率预测——即使在一些最有利于完型填空的条件下。如果发现了LM比完型填空概率更能够预测N400的幅度,就很可能是:N400能被语言统计驱动。 完型填空概率可能存在的问题: 之前一些研究已经发现完型填空概率能够比LM更好地预测反应时等行为学指标。然而,完型填空概率是基于人的判断的,而完型填空似乎对于理解在线人类理解并不是很有帮助,例如N400这种一瞬间出现的东西。完型填空概率是基于大量人的最佳预测来计算的,一些不太可能出现的词只有大量的被试才能得到完型填空概率,而LM是一个分布概率。同时,也不太知道,理解和产出系统里的next-word probability是不是一样的。总之,没有先验原因来假定完型填空概率是N400下隐藏的预测的最佳可能的调控。 而对于LM来说,它们仅仅依靠输入规律来学习,基本不会学习语义,而N400幅度一般是由意义决定的,所以按预期来说,可能LM的表现会更差,但也有一些研究说LM能够获得语义知识,也就是说我们可能不需要直接的经验就能够学习词的指代之间的语义关系。 作者的这个实验选择的一个大型的N400研究,n=334,这个实验本身就是研究完型填空概率和N400的关系的,然后作者再使用LM来计算surprisal来建立回归。作者把材料里所有完型填空概率为0的情况都去掉了。作者会计算原始概率和surprisal,都来建模。
方法 ¶
原始实验,N400是用了Centro-parietal的感兴趣区的200-500ms(是不是太长了)的平均值(就只有6个电极),结果发现高完型填空概率的词比低完型填空概率的词引发更小的N400。完型填空概率用了30个被试来计算。原始实验收集了334个被试的脑电,一共25000多试次,把其中完型填空概率为0的试次去掉了。 采用了两种类型的语言模型:transformer(又分为自动回归语言模型如GPT3和标记语言模型)和循环神经网络RNN,然后使用和完型填空概率类似的方法问语言模型预测词的预测概率,然后通过公式计算surprisal。 然后在统计分析之前,LM的surprisal、原始完型填空概率、完型填空surprisal和每个试次的N400都通过z分数转换了。随后前面这些参数都用来预测z分数转换后的每个试次的N400。
结果和讨论 ¶
先采用的Akaike information criteria来做的,来比较完型填空概率和转换后的完型填空surprisal,显示cloze surprisal有完型填空概率模型两倍可能性是N400最好的模型,但好像统计效益并不显著。 为了看不同LM计算出来的suprprisal的解释程度,根据不同的LM建立了不同的模型,来看看哪些模型计算surprisal的主效应显著。 结果如下图,发现只有一个模型边缘显著,其他的全部显著。
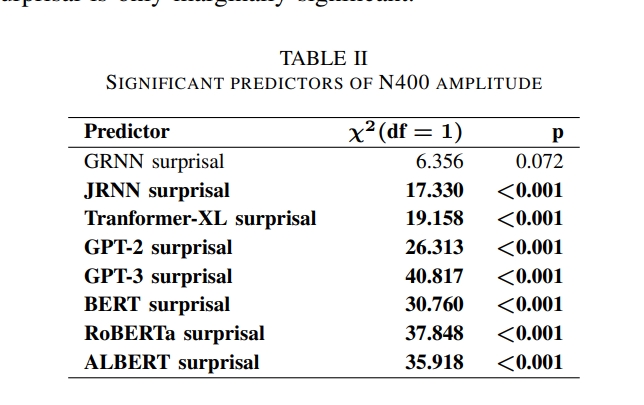
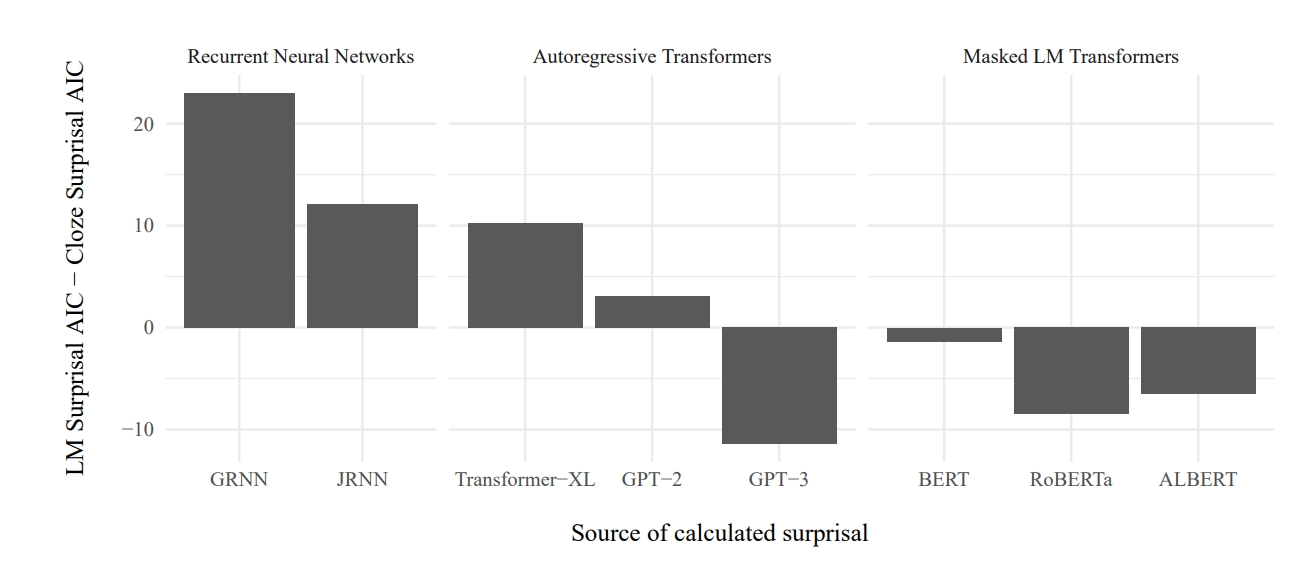
完型填空概率可能并不是金标准,例如,the pizza was too hot to eat/drink/cry,drink和cry都是0概率以及都是语义不合理,但是drink却比cryN400幅度小。 因此作者建议,以后也许可以使用上LM计算的surprisal。