论文信息 ¶
Zhang, W., Dong, J., Duan, X., Zhang, Y., Gao, X., Zhen, A., . . . Yan, H. (2023). Prediction of semantic features is modulated by global prediction reliability: Evidence from the N400 effect. Journal of Neurolinguistics, 65. doi:10.1016/j.jneuroling.2022.101109
论文原文 ¶
关键词 ¶
N400;prediction;语义相似度
摘要 ¶
词汇预测已经被证实了会受到全局语境(global context)的调节,但目前不清楚全局语境是否会对语义特征的语义有相似的调节作用。ERP研究也许会对这个问题很有帮助,因为N400效应在句子理解中对词汇预测和语义特征的预测都很敏感。当前研究操控了预测词和非预测的目标词之间的语义相似度。不同类型的filler(预测/不协调)被用来操纵全局预测可靠度(GPR)。ERP结果显示,在预测filler部分中,当预期外的目标词和预期词的语义相似度高的时候,N400被降低了。而这种联系在不一致filler部分是缺失的,在这种filler条件下被试会从预测即将到来的信息中受挫。这些结果显示,即将到来的词的语义特征的预测能够被全局语境调节。
引言 ¶
语言理解领域里,越来越多证据显示读者能够生成对即将到来的输入的预测。同时,最近研究显示,词汇预测能够被全局语境所调节。作者的研究就是为了检验对即将到来的词的语义特征的预测会不会也受到全局语境的调节。 在ERP研究里,N400通常代表了对预测单词的加速的词汇语义促进,一些研究的结果表明N400对词汇预测很敏感,并且读者能够使用句子语境来预测具体的单词。但是,这种N400和词汇预测的关系也可以用整合的观点来解释(预测的词可以更容易地和前面的语境整合)。相应的,词汇观点就认为N400效应反应的是促进的词汇接触。当前这个研究并不是为了解决哪个问题是正确的,作者将采用这种词汇观点来检查句子理解隐含的预测机制。 除了预测特定的词之外,读者能够预测一个词的语义特征,这种语义的预测也能够调节N400。例如,“情人节,他送了她一朵玫瑰/郁金香/棕榈树”,而“郁金香”相较于“棕榈树”的N400更低。这个结果就显示了预期词的语义特征的预激活能够促进实际遇到的词的词汇语义的加工。 在实际的沟通中,句子通常嵌入在有着不同统计策略的全局沟通语境中。因此,最近的研究旨在检查自上而下的预测的强度是否会被全局语境信息调控。例如,Dave et al.(2021),招募了年轻人和老年人,并让他们听不同的句子来理解。通过加入filler来调控全局预测可信度(GPR),结果显示N400效应对年轻人和老年人的词汇预测都十分敏感,但是只有年轻人群体的N400效应受到GPR调节。 总之,之前的研究已经显示了预测词的语义特征能够被预激活。同时,词汇的预测能够被GPR调节。因此,我们也可以猜测,GPR也能够调节目标词的语义特征的预测。作者的研究重心就在这里。
当前研究 ¶
- 作者操纵了预测词(高完型填空概率)和意料外的目标词之间的语义相似度。而预测词的预测强度由两种不同类型的filler来操纵。需要注意的是,实验中的目标词总是不可预测的,但是它在语义上和句子语境是一致的。被试会对预测词和预期外的目标词进行语义相似度的评分。有两个block,每个里面50%的实验句和50%的filler,在可预测filler条件下,实验句是不可预测的,而filler句是高度预测的,因此GPR就是50%。在不可预测filler条件下,filler句在语义上不和谐,并且实验句仍然是不可预测的,因此GPR就是0%。 作者计算所有被试的每个实验句的项目的平均N400幅度。然后使用方差分析和相关分析来看每种filler条件下N400和语义相似度之间的关系。作者首先认为,当语义相似度增加,N400幅度应该会减小。更重要的是,被试可能会在GPR更大时更可能预测即将到来的词。因此,作者预测,N400和语义相似度之间的这种负相关可能会在较大的GPR时更强,例如,N400效应可能在预测filler block里面更强,而在不和谐的filler block里更低。
- 实验材料和方法:1.被试:18个华南师大学生,右利手,矫正视力。2.材料:包括了一套160个汉语句子的材料,其中80个实验句,80个filler。句末最后的两字词被操纵用以创建不同的句子类型。实验句是不可预测但语义合适的,40个filler是高度可预测的而另40个filler是语义上不和谐的。在完型填空测试里,对于可预测filler,关键词有着最高的完型填空概率0.8,而对于不和谐的filler完型填空概率只有0。同时,所有实验和filler句的语境限制都高于0.63(即完型填空概率最高的单词的概率)。四种句子类型(低语义相似度、高语义相似度,高预测filler,语义不和谐filler)之间的平均语境限制度没有显著差异。
同时,20个被试对实验句高完型填空概率的句子,对预测词和实际出现的词的语义相似度进行评分,以3.9分为分界线,高语义相似度组平均分5.1分(牡丹-玫瑰),低语义相似度平均分2分(星星-钞票),t检验显示出了显著的差别。同时收了20个被试来对句子的语义合理度进行评分,predictited filler评分是显著最高的,高语义相似度和低语义相似度的语义合理度没有显著的差别,这里使用的是方差分析和事后多重比较。
随后把句子分为4个block,2个是GPR=0.5,即所有filler都是预测词出现,另外2个block是GPR=0,即所有filler都是意外词出现。这些都在被试间做了些平衡。
整个实验的流程及结果图可以参考下图:
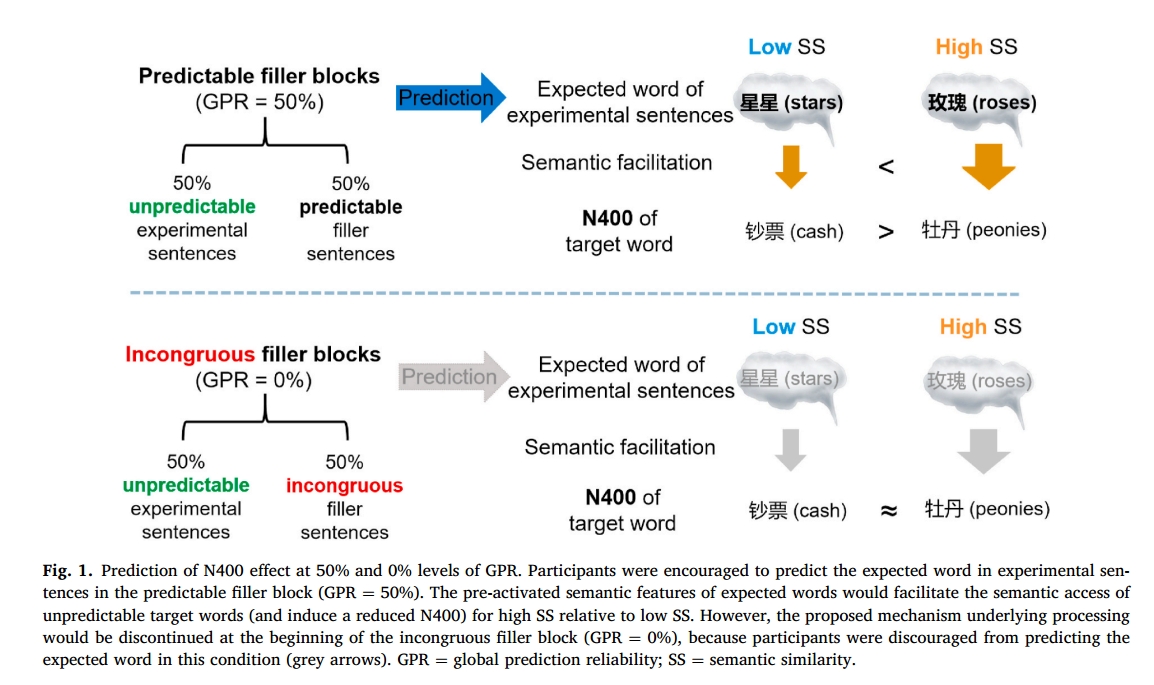
- 程序:作者每个词呈现400ms,刺激间隔200ms,在1200ms的空白之后,被试被要求给每个句子的语义合理度打分,满分为7分。被试需要集中注意力等。
- EEG:用的30个电极的帽子,在1000Hz采样率下采样,并用0.02-30Hz带通离线进行滤波,epoch是目标词出现后的1000ms,眼球和运动伪影的epoch被拒绝(+-80uV)。各种类型的拒绝率之间没有统计学上的差异。先计算了grand average的N400,是不是就是所有电极的平均,接下来由于有N400区域的假设,计算了感兴趣区的六个电极的平均N400(主要是中央-后部的区域,即中间的Cp和P电极)。使用重复测量方差分析来检验N400差异。 更重要的是,作者提取了每一个不可预测实验句的项目级别的N400幅度,作者关注这种项目级的N400是如何被语义相似度调节的。采用方差分析,将GPR水平和语义相似度作为两个因素做2×2的方差分析,另一方面,项目水平的N400振幅先用z分数归一化,然后相关分析来看N400幅度和语义相似度之间的关系。
结果 ¶
- 行为学数据:在两种GPR条件下,被试对高语义相似度和低语义相似度的句子的语义合理性评分都没有显示出显著的差异。
- 脑电数据:
为什么不把不同GPR的两种unpredictable targets分开放????这里图上非要揉在一起呈现呢?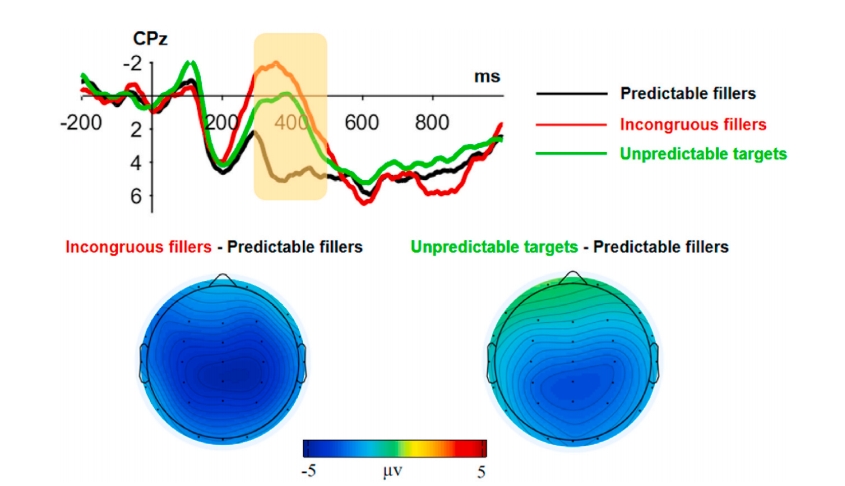
这个图展示了两种GPR条件下,低语义相似度和高语义相似度的N400(仅Cpz电极的,其他电极附录展示),同时根据地形图来看,在50%GPR水平下,与高SS相比,低SS表现出更负的N400效应,并且主要分布于中央-后部区域,而对于0%GPR条件下,N400效应不存在。 方差分析结果显示与0%GPR相比,50%GPR水平下,N400更负,更重要的是语义相似度和GPR的交互作用显著,简单的效应分析表明,50%GPR水平下,高SS比低SS的N400幅度更小,而在0%GPR水平下,高低SS相似度组间没有显著差异。 大概所有脑电都是先看可视化的N400图,再统计分析 同时,把SS作为连续变量,使用散点图来说明两级GPR的项目级N400与SS的相关性,结果显示,50%水平上,SS的增加,N400幅度减少,r=0.25, p<0.05,而0%水平上,SS和N400幅度无显著相关。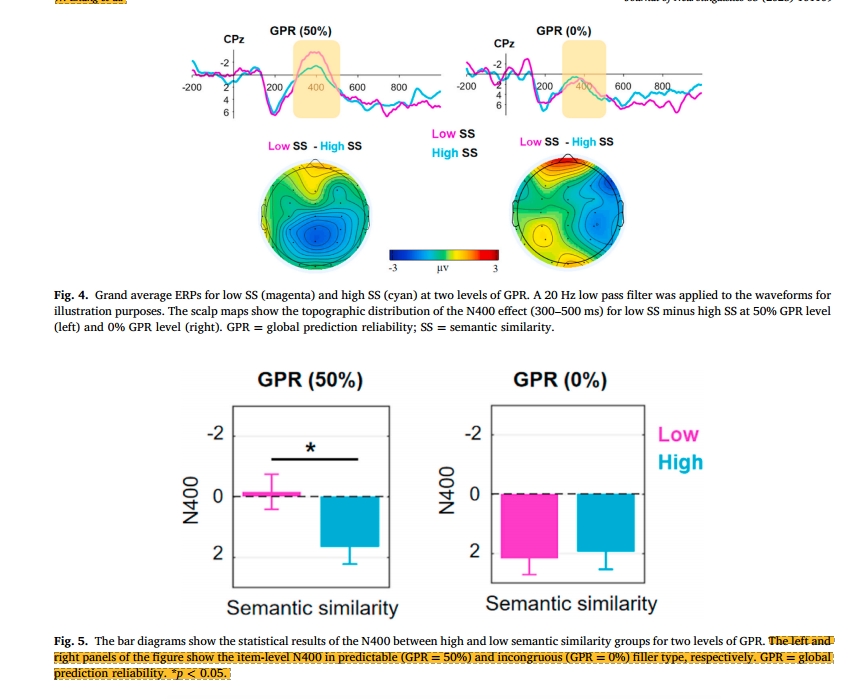
讨论 ¶
总之,研究发现语义特征的激活水平可能受到全局语境的调节。以往的研究都是在词汇水平上来看的,例如“李华起诉了司机并带去了——法庭——”以及“李华遇到了司机并带去了——法庭——”,这两种条件下的全局语境作用,而本研究直接从语义入手,而非预测词入手。结果反应了由于语义特征被预激活,使得对目标词的语义访问变得容易。 作者认为机制如下:在50%GPR水平下,由于被试被鼓励预测,预期词的语义特征被预测预激活,所有实验句子都是高约束。即使看到的是不可预测的目标词,而不是预期词,这种预激活的语义特征也有助于对不可预测的目标词的语义访问。在0%GPR水平下,被试从一开始就不被鼓励预测期望的单词,因此N400和语义相似度没有明显的关系。可能被试更倾向于被动地等待单词出现。总之就是直接证明了N400效应对语义特征的预测是敏感的,并且这种效应可以被GPR所调制,也就是说,理解者可以根据语境调节预测的语义信息。