论文信息 ¶
Zhao, Z., Ding, J., Wang, J., Chen, Y., & Li, X. (2023). The flexibility and representational nature of phonological prediction in listening comprehension: Evidence from the visual world paradigm. Language and Cognition, 1-24. doi:10.1017/langcog.2023.38
论文原文 ¶
关键词 ¶
语音预测;视觉世界范式;眼动;语言理解
摘要 ¶
该研究使用视觉世界范式,以词呈现而非图片,来研究实时言语加工中的语音预测的灵活性和表征本质。汉语母语者听含有预测词的高限制的句子,同时注视屏幕上的关键词和干扰词。关键词有四种情况:1. 高度预测的词 2. 和高度预测词是同音异形的词 3. 声调和预测词一样的词(音段信息不一样)4. 无关词。被试在听到目标词之前,就更倾向于注视同音异形的词而非干扰词,预测的语音信息随后减弱,但在目标词出现前的附近再次被激活。重要的是,这种对同音异形词的注视偏向只存在于“发音判断任务”中,在“单词判断”任务中没有出现这种偏好。所有任务中都没有出现对声调一样的词的注视偏好。表明了语音预测能被从上而下的机制灵活地生成(也就是受任务的影响)。同时也表明了声调等语音特征没法被单独预测。
引言 ¶
关于预测的背景不再赘述。许多研究都表明了我们能够预测单词的语义,但是单词的语音形式我们到底能不能预测呢?从ERP研究来看,05年delong的那一篇the girl fly a/an是一个很强的证据,但是最近发现这个研究难以复现。而从眼动研究来看,最近很多研究显示了我们能够预测单词的语音信息。作者这里主要是想看语音的预测1. 到底有没有 2. 是不是灵活出现的(这里应该是对应着完全自动地预测)3. 声调能不能单独地被预测?因此作者设计了实验1和实验2来验证。
实验1a、b ¶
- 实验材料:主要是呈现这类句子:“为了把票据粘在一起,他们往往会使用那种—胶—-”,在这个句子里“胶”是预测词,作者设计了四种条件:1. 预测词VS无关词 2. 和预测词同音异形的词(例如“椒”)VS 无关词3. 和预测词声调一样的词(例如“粥”)VS无关词 4. 无关词VS无关词。在实验1a里,屏幕上就呈现上述一种情况的两个词,在句子播放完之后,是问题:“前面是否出现了某个词”这种词汇判断任务。在实验1b里,一模一样,只是问题变成了语音判断任务:“前面是否有和某个词语音重叠的词” 在正式实验开始之前,完型填空测试、语义相似度等都是提前检验了的。
- 被试:被试很多,找了50个,所以实验1a和b一共就是100个。实验程序也和一般的眼动程序没有什么区别。
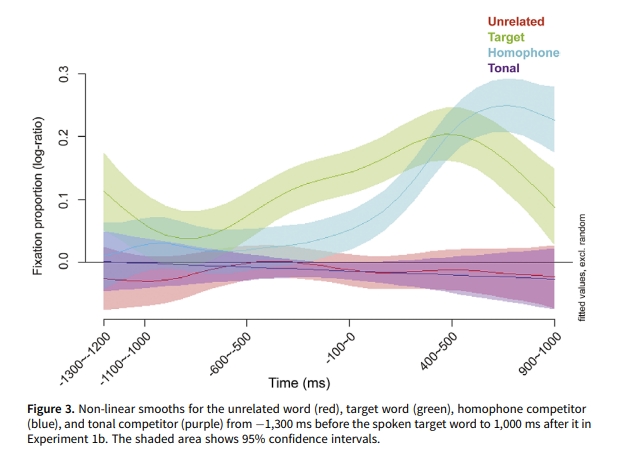
- 结果:在实验1a里,也就是词汇选择任务中,被试会在目标词出现之前就倾向于注视预测词,但是对于同音异形词、声调一致词,都没有显著的偏向,也就是说,在这种任务下,可能并没有语音的预激活。但是在实验1b里,也就是语音判断任务里,被试不仅在目标词出现之前就倾向于更多注视预测词,而且还更多地注视同音异形词(相对于无关词来说地),但是声调一样的词仍然没有更多地注视偏好。
其实,这就说明了我们能够在句子理解中预测词的语音形式,但是这是和我们的具体任务相关的,可能我们会根据语音预测的有用性来决定我们是否预测语音形式?同时,也说明了我们没办法单独地预测声调,只能把声调和其他的音段信息一起预测出来。(但是,一个疑问:有没有可能声调的预测也是和任务相关的?要是我造一个任务,让他们判断某个词的声调和前面的词的声调是否有重叠,能不能显示出对同声调的词的注视偏好呢?)
实验2 ¶
实验2和实验1b是一样的,但是为了搞清楚是不是个体差异起了作用,使得实验1a没有效应实验1b有效应,作者设计了实验2,实验2里同一被试,既要完成词汇选择任务,也要完成语音判断任务,各占一半,因此排除了个体差异的影响。结果也和实验1一模一样。
思考 ¶
这里的语音先出现了短时间,然后又消失了,随后在预测词即将出现的时候,又被再次激活了,这其实是和上周看的那篇RSA文章中讨论的部分有点类似的。是不是我们在句子呈现时很早就能预测语音了?只是预测之后一直保留着,等到快要呈现目标词之前被再次激活了呢? 这两篇文章其实都验证了我们能够预期具体的单词的形式,但是这似乎是受任务而定的?而不是说完全自动就能预测具体的形式?