论文信息 ¶
Wang, L., Brothers, T., Jensen, O., & Kuperberg, G. R. (2023). Dissociating the pre-activation of word meaning and form during sentence comprehension: Evidence from EEG representational similarity analysis.* Psychon Bull Rev.* doi:10.3758/s13423-023-02385-0
论文原文 ¶
关键词 ¶
预测;预激活;形式;意义;同形异义词
摘要 ¶
语言理解过程中,每个即将到来的单词的加工根据它的可预测性而被促进加工。作者主要探讨,我们是否能够在自下而上的输入到来之前预测即将到来的语言信息,如果能,这种预测是只局限于语义,还是说我们也能够预测单词的形式(orthography/phonology)。作者主要通过EEG里的RSA方法来分析,看看预测(银行bank——河岸bank)这种形式相关的词的句子,还有预测(银行bank-贷款loan)这种语义相关的词的句子,还有完全无关的词的句子,他们的表征相似度如何。作者发现,语义相关的对,以及形式相关的对,比完全无关的对,产生了更多的相似的神经模式。这就直接为语义预测和形式预测提供了神经证据。更重要的是,这种语义的预激活似乎出现在形式的预激活之前,表明了自上而下的从语言层级的低层次到高层次的预测传播。
引言 ¶
预测的背景不用多说了,但是有一个主要的问题悬而未决,那就是我们的预测是只局限在语义信息上,还是说我们能够预测单词的形式呢?以往有N400的研究似乎表明了我们可以预测单词的具体形式,例如the girl fly a/an这种prenomina研究,但是1. 难以复现 2. 没有直接研究预测的进程,研究的是预测之后对单词的促进加工,这太间接了。 所以作者打算使用表征相似性分析RSA,直接分析在目标词出现之前的神经活动的相似性,来看看我们预测语义相关的词时、和预测形式相关的词时,和预测完全无关的词时神经活动相似性如何。
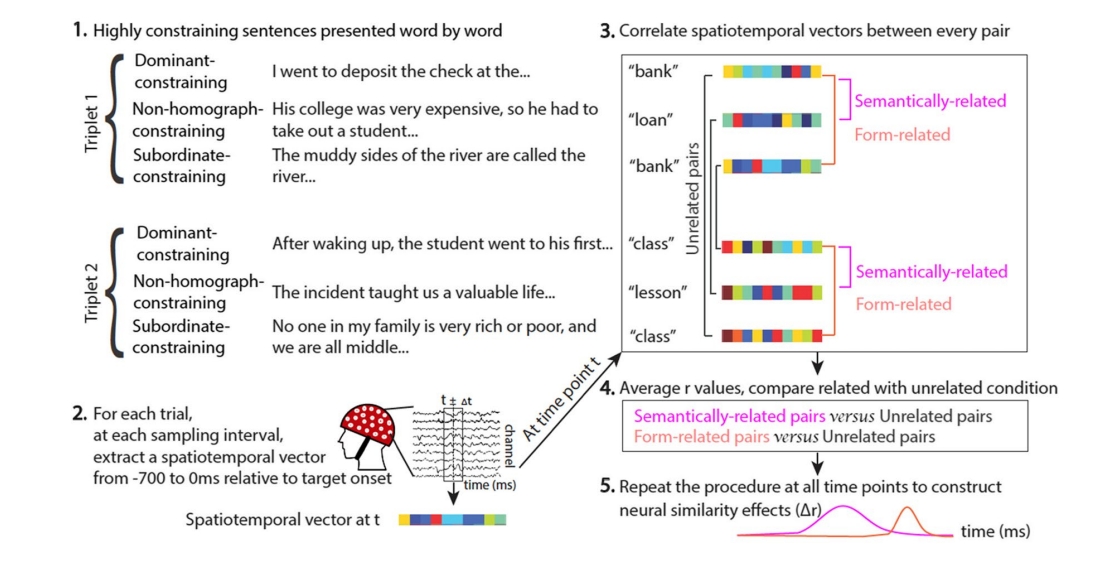
材料 ¶
实验材料和过程如下图所示,比较清楚,同时作者考虑了很多可能会影响RSA的因素,包括即将出现的词的语义相似度,句子中分析处的词的语义相似度,句子结构相似度可能引起的变化,甚至是上下文的单词数量等,作者都通过选一定的数据或者通过数据库排除,其中还使用了GPT-3数据库来看单词的出现概率等(这个具体是怎么看的?我还不清楚)
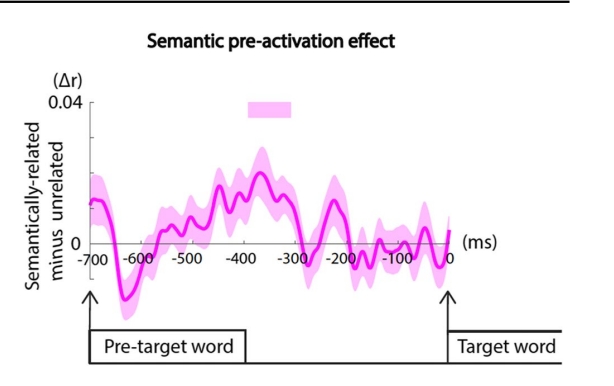
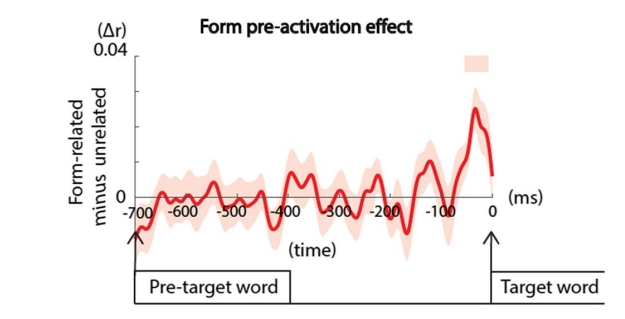
结果 ¶
如下图所示,对于语义相关组与无关组的比较,以及形式相关组和无关组的比较,均如下图:
讨论 ¶
结果显而易见:先进行语义的预测,最后一个词结束300ms左右,再由语义自上而下进行形式的预测,预测词出现前的50ms左右,两者都进行并且中间有时间的间隔。 虽然有些人认为,我们也可能先进行形式预测,只是时间短,通过这种研究显示不出来,而在预测单词即将出现时,这种反应才会被reignite。 那么其实接下来的研究方向其实应该十分明确了,那就是不断地改变呈现的最后那个单词的呈现时间来看看RSA甚至可以看看N400的区别(我认为)。(打印出来看的故记录较少)