论文信息 ¶
Van Petten, C. (2014). Examining the N400 semantic context effect item-by-item: relationship to corpus-based measures of word co-occurrence.* Int J Psychophysiol, 94*(3), 407-419. doi:10.1016/j.ijpsycho.2014.10.012
论文原文 ¶
关键词 ¶
语义相似性;N400; LSA;
摘要 ¶
随着数字文本的日益普及,出现了大量的计算方法,这些方法旨在将大型文本语料库中的单词共现模式转换为表示任意两个单词之间的“语义距离”的数字分数。这些方法的成功通常是通过它们预测人类相似性判断的准确程度来评估的。这篇文章里,作者考察了基于语料库的方法预测ERP的N400成分的幅度有多好。在单个项目的水平上分析了303个词对中的第二个词所诱发的ERP。三种基于语料库的测量方法(相互信息、分布相似性、潜在语义分析)与传统的自由关联强度测量方法进行了比较。在回归分析中,基于语料库的测量方法和自由关联测量分别解释了N400波幅的一些差异,这表明这些策略可能利用了词关系的不同方面。词义的具体性、词频、词义关联数和拼写相似度等词汇因素也解释了N400波幅在单个项目水平上的差异。
引言 ¶
理解语义记忆的组织结构是认知科学的基本目标之一。许多数据源和计算程序都被用来量化词表达的各个概念之间的关系。对数据源分类的一种方法是根据它们的生成性和接受性。生成方法包括自由联想提示单词,标准语言使用者提供的单词属性或特征列表以及专家词典编撰者提供的单词定义。而接受性方法包括对一对单词的相似度或关联度的判断,以及快速任务中的语义语境效应。第三类数据是基于一堆单词在文本中同时出现的频率,这种数据源同时含有生成性和接受性两个方面。 随着计算机能力不断增强,过去十年有了许多将这些不同来源的原始数据转换为数字分数的计算方法,这些分数表示任意两个单词之间的语义距离。 这些新的计算程序的成功通常通过其距离度量预测人类表现的好坏来评估,例如,基于文本语料库中的单词共现的程序是否可以预测人们将在自由联想任务中生成哪些单词,在词汇判断任务配对时,具有相似特征列表的单词是否也会产生较大的RT收益,专家定义中不同词的重叠是否可以预测人类对词对相似性的评分。然而这些评估缺乏对大脑活动的测量,尽管N400成分已经被证实对成对单词之间的语义关系十分敏感。 缺少研究的原因之一是,ERP依赖于对大量集合单词的平均大脑反应,因此实验条件通常被定义为范畴变量。相比之下,语义距离的计算度量本质上是连续的,因此它们最好和其他的连续度量相比较,即可以为单个词对导出的度量。而最近就有ERP和相关的研究,例如Laszlo(2011)发现,由每个单词引起的N400幅度的回归,成功地捕捉到了与每个单词与其他单词地拼写相似相关的差异。 作者在单个词的水平上考察了N400幅度和联想强度之间的相关性(即对线索A提供词B的标准参与者的百分比)。之前使用更传统的跨词集平均的ERP研究导致了一个强有力的预测,即N400的幅度和联想强度将在单个项目水平上呈负相关。然而,下文中作者讨论了自由联想规范的一些限制,这些限制表明了这种相关性可能是适度的。导言的其余部分简要描述了最近提出的作为语义距离的度量的方法,特别是基于文本中单词的共现的方法。
- 自由联想 自由联想规范一直是词对关系强度的金标准,其强度表示为给定词A,提供词B的被试的百分比,让被试只给出脑海中产生的第一个词。ERP研究比较了强关联、弱关联、非关联的目标对的集合,研究均表明,强关联的目标词产生的N400最小,而弱关联的目标词次之,无关联的N400幅度最大。然而作者却没有复现出上述结果。这一失败表明,N400幅度和关联强度之间的关系有点嘈杂,因此很难区分相当接近的关联强度水平(例如作者的复现实验是6%vs12%),尽管更远的水平很容易区分(如12%vs24%)。有一种可能是:自由联想任务只提供了单词之间的概念联系的部分视图。 自由联想任务中的一些偏差已经得到了很好地证明,一个是名词应答占据了主导地位,而动词、形容词应答稀少,还有的倾向于应答词和提示词共享词性,比如short就会回答tall,而非short的物体。这些偏差都似乎违背了自然语言的使用,而自然语言的使用主要围绕着实体的动作、状态或属性展开。自由联想作为语义关系的衡量标准的其他限制来自于实验室程序附加的语用因素,最典型的任务是让被试提供一个回答,最多也仅限于两个/三个回答。这种过程可能会低估较弱的语义关系,理论上,每个被试想到的一个词——但是这个词是他的第二个或第四个想到的词——在最终的回答汇编里可能完全不会出现。最后一个限制就是自由联想数据库的限制,英语中单词联想的两个数据库对于实验室项目是非常大的,差不多有5000+词的应答。尽管如此,这些词汇量远小于普通读者的词汇量,研究人员不太可能在自由联想规范里找到他/她想要的每一个词。尽管限制很多,但是研究已经将联想强度和脑电活动联系在了一起,因此在当前的分析中,这些大常模的测量将作为目标词的N400幅度的一个预测因子被包含在内。
- 语料库测量:从共现到分布相似再到潜在语义因素 1.单词共现 数字文本的日益普及促进了一种不同类型的非实验室数据手机程序,该程序绕过了自由联想规范的大小限制。语料库语言学的基本计算是提取词的共现频率,例如词A和词B在某一文本范围内——紧邻的、在5个词的窗口内、在同一文档内等——共同出现的频率。对于量化人类语义记忆中的概念联系的尝试,必须采用某种校正方法,才能有意义地解释这两个单词对的共现频率,如果不矫正,那么常用词和其他任何词的共现频率一定比那些不常用的词高。Recchia(2009)使用了用共现频率除两个词的基本频率乘积的公式,发现了共现频率(使用十个句子的窗口)和人类对词对相似性的判断之间的平均相关性r=0.78. 在检查共现频率和已知的对基本词频敏感的相关度量之间的关系时,将基本使用频率和共现频率分开尤其重要(就像上面提到的这个)。比如有的研究显示出了共现频率和词/非词判断任务的反应时之间的负相关,但这个任务可能和词汇本身的出现频率有关。为了目前于N400波幅的比较,作者从4.5亿词的当代美国英语语料库中收集了5个词和9个词跨度的共现频率,并详细介绍了如何将基本的词汇频率的影响和共现频率分开。 2.分布的相似性 一些语言学家提出这样一种观点,即在相似的语境中出现的词在意义上必须是相关的,例如clear和transparent从未同时出现在同一文件中,但发现这两个词往往可以与see、cover、murky、vague等词一起出现,这些将提供clear和transparent本身相关的证据。Goodenough(1965)可能是第一个对这个观点进行检验的语言学家,他们发现,单词在重叠的语境中出现的程度预测了它们被判断为同义词的可能性。为了计算语境重叠他们使用了非常小的语料库:由实验室被试用词对中的一个成员(没有看到词对中另一个词是什么)写出的句子。 而现在产生了一大批模型用于计算分布相似性,这些模型基于更大的自然生成文本语料库,显然比上述Goodenough的语料库大得多。主要通过语料库形成一个矩阵,行和列代表了语料库中每个单词,交叉的空填上共现的频率,每个单词的行和列代表了单词的向量,如果两个单词的向量相似,那么这两个单词的分布相似。这种模型在模仿人类在强迫选择任务中的表现取得了一些成功,以及显示出了和联想强度的中等相关性,以及和单词之间的语义相似性等级的较高的相关性。 很少有人尝试通过词对之间的向量相似性来预测词识别任务中的在线表现。之前有过反应时的研究,发现向量相关性和第二个词的反应时(确定一个词对是相关的还是不相关的)显著相关。但结果可能受到基本词频的影响,通过控制了词频影响,shaul(2010)发现了向量相关性和反应时之间没有显著关系。 鉴于目前确定分布相似性是否可以预测N400影响的新颖性,这里没有尝试比较多个模型,普遍共识是模型的成功取决于初始共现数据的质量,这样,较大的语料库比较小的语料库更好,同时,高质量的文本比网站上抓取的未经编辑的文本更可取。作者使用的模型是基于300000篇维基百科文章的共现频率,包括2.67亿个词。 3.潜在的语义因素 计算语义距离的其他模型包括计算共现矩阵和比较词向量相似度之外的其他步骤。广义来说,通过奇异值分解(类似于因子分析)等方法,把语义空间压缩为比初始的共现矩阵中最初的行数和列数更小的一组因子。潜在语义分析LSA是最早的,最流行的这类模型。LSA使用了词到文档的共现矩阵,而不是词到词的共现,这与大多数其他基于语料库的方法的不同。这里的单独的文档每个250-350个字,语料库包含了教科书、文学作品、流行小说等。度量语义距离的LSA被报道在多项选择任务中选择最接近的同义词方面表现较好。LSA与人类对单词对相似度的评分之间的相关性较高。然而LSA计算的语义距离和语义语境对词处理的直接影响之间的关系很少有研究。许多研究发现,LSA测量没有显著的能力来预测词汇决定的反应时。 很少有人致力于考察语义语境的ERP与LSA度量之间的关系。Donaldson(2008)发现自由联想不相关但根据语义距离模型相关的词对引起的N400,与完全不相关的词对产生N400一样大。还有的研究都都比较摸棱两可,显示LSA可能会影响N400波幅。 心理语言学中使用的大多数或所有依赖测量除了与其他单词的语义关系外,还对单词的特征敏感,例如单词的使用频率、与其他单词的拼写相似性。因此,研究语义影响的一个实验策略是在各种其他词汇特征上尽可能地匹配,或者直接在不同的上下文中呈现相同的单词。而另一种不同的策略就是使用回归分析来梳理各种变量的影响。 目前研究的目标是研究N400波幅与连续测量的“语义距离”之间的关系,使用回归分析,不仅比较在语义距离上不同的项目,而且也比较多种词汇特征上也不同的项目。
方法 ¶
- 被试 32个被试,平均年龄23.8岁,英语母语。所有人接受了大学教育,排除3名被试。
- 刺激和程序 最初构建了320个词对作为句子加工研究的控制项,一半的词对被归类为语义不相关,因为他们在爱丁堡语料库中的联想强度为0。另一半的词对有着积极的联想强度。关联和非关联的词对共享提示词,例如arms-legs,arms-truck。所以每个被试看80对关联的词对,80对非关联的词对,80个词和非词组成的词对。词对中每个词呈现200ms,间隔550ms,试验之间间隔4.7s。被试通过按按钮的方式快速对第二项做出词汇决定。这里还给出了一个表,里面有各个目标词的特征以及关联强度。
- 具体的参数 基于项目的数据分析包括了已知或可能影响N400幅度和/或词汇判断时间的几个方面,以及他们与提示词关系的强度。1. 一个是词的使用频率,多项研究表明低频词比高频词产生更大的N400,而词汇判断更慢。使用频率表示为美国英语语料库中(每百万个)出现的自然log。2. 第二个是与其他单词的拼写相似度,因为与其他许多单词都相似的单词比会产生更大的N400和更快的反应时,与拼写没那么和其他单词相似的词相比。拼写相似性被定义为20个相邻单词之间的Levenshtein距离(即将一个单词转换为其他单词所需要的字母更改、添加和删除的平均次数,从而分数低表示和其他单词十分相似,分数高表明和其他单词不太相似)3. 有的研究显示双词频率也影响N400幅度,因此平均双词频率的自然对数也是从English Language Project里收集的。4. 许多研究表明,具有具体意义的词比具有抽象意义的词产生更大的N400和更快的词汇决定时间。具体程度评分来自于最近的一项大规模研究,被试对单词的评分从1(最不具体)到5。5. 一些研究显示有更多的关联词的单词也往往会导致更快的词汇决定时间,在这里关联词的数量主要定义为爱丁堡语料库中当这个词作为提示词时引发的不同单词的数量。6. 最后,词根形式的语素被编码为1,词形变化形式的编码为2。7. 还计算了每对提示词和目标词之间关系强度的五个测量值:FAS前向联想强度、BAS后向联想强度、共现频率PMI(采用了9个词的窗口,只有4个词共现频率为0,用0.01来替代,同时,需要把共现频率和基本频率区分开来,用了个数学公式排除了基本频率的影响,得出了PMI)、分布相似性(也就是单词之间的“语义距离”,距离不仅反映了两个词的接近程度,还反应了它们在相似的上下文中被发现的可能性,也就是先计算共现频率,然后再看一下共现矩阵里的向量来看分布的相似性)、潜在语义分析LSA(见引言)
- EEG方法 每个头皮部位在记录期间参考左侧乳突,而在数据分析之前重新参考左侧和右侧乳突的平均值。垂直、水平眼球电极来检测眼电,眼电、肌电或放大器阻断伪影的试验在平均之前被拒绝。
- 统计分析方法 测量了目标词开始后的250到450ms的N400潜伏期窗口内的平均幅度,以刺激前200ms为基线,从三个中线头皮部位(Fz、Cz、Pz)测量EEG的平均幅度,这些测量都是从每个被试的单个试验中得出的。 为了减少于单个被试相关的变异性(例如不同被试脑电大小不同),每个单次试验的幅度被转换为基于来与该被试的所有试验的z分数。然后,对于给定的目标词,将得到的z分数在被试里进行平均,整个单词集的总体平均z=0.负分数表示较大的N400,而正分数表示较小的N400。 词汇判断任务中偏离给定被试平均值两个标准差的反应时被丢弃,剩余的如上所述也转换为z分数。 统计程序是相关和回归。这种N400波幅和这些变量之间的线性关系很有趣,因为之前只有两个研究检查了这些关系。更令人关注的是,关系强度变量是否对N400幅度具有线性影响,如果有,哪些变量具有线性影响?
结果 ¶
- N400幅度 初步分析证实,当关系以传统的二进制方式编码前向关联强度为0或者大于0时,相关单词引起的N400比不相关单词引起的要小。其余的分析均采用的基于N400幅度的z分数变换,并且使用的是连续变量而不是二进制变量。
1.1零级关联 表2显示了上述的指标与N400幅度和词汇决定时间这两个因变量之间的相关性。值得注意的是,衡量关联强度的五个指标之间存在着很强的相关性。这五个参数与N400波幅均呈显著正相关,前向联想强度、单词共现PMI和潜在语义分析LSA指标对N400波幅的预测能力略强于后向联想强度或分布相似性。而虽然前向联想强度和N400波幅的散点图显示出了线性关系,但是对于0关联强度的词来说,其分布范围也异常惊人,这可能表明,这种联系规范中的0分掩盖了联系强度的一些多样性(地板效应)。相比之下,基于语料库的几个衡量标准地板效应的可能性就小得多,因为大型语料库中,共现0次很少。 1.2偏相关 表显示,关联强度变量和其他剩下的这些词的特征变量有弱到中等的相关性。(这里貌似在求的偏相关?就是把各种词汇特征的变量的影响除去了,再来看剩下的那几个表示“语义距离”的因素和N400幅度的关系)。偏相关显示,这些五个语义测量仍然与N400波幅显著相关。事实上偏相关和零级相关没有实质性的差异,同时前向联想强度、PMI、LSA三个指标也没有明显的孰优孰劣。 1.3回归分析 上面的相关分析表明,N400波幅和这里研究的所有五个语义距离度量都是线性相关的,并且LSA度量是(不显著的)最强大的。然而,仍有可能各种度量正在捕获词对之间的语义关系的不同方面。回归被用来检验一组测量将导致比任何单一的语义关系强度的测量更大的预测力的可能性。N400波幅的z分数是因变量。这些预测变量是分层输入的,在第一步,先将词频、拼写相似度、二元词频等六个变量输入为一组,第二步才将关系强度的五个指标输入进去,α水平0.05。 结果显示,回归模型解释了N400波幅的大约31%的变化,描述目标词本身的词汇变量之间以及联系强度五个变量的分配几乎相等。 回归结果如下表,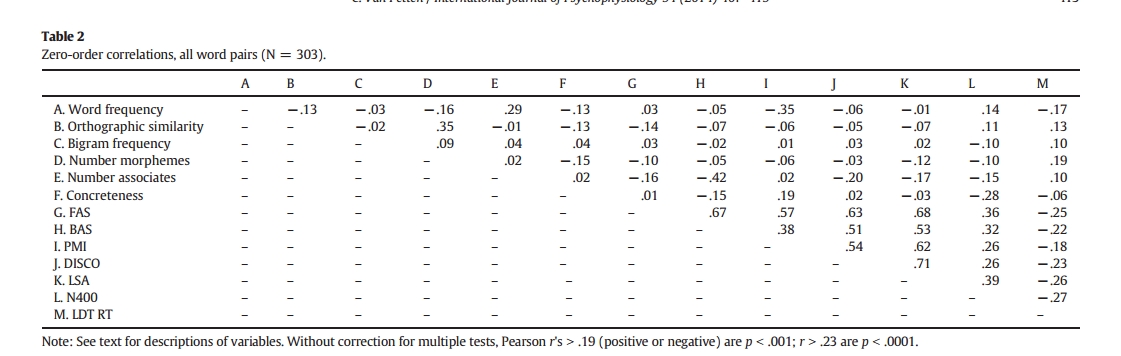
对于显示对最佳拟合回归具有统计显著贡献的词汇变量来说,所有的变量都与先前的工作预期的方向一致。详细如下:出现频率较低的单词与较大的N400幅度相关联,与大量其他英语单词在正字法上相似的单词以及具有较多的语义关联词的单词也是如此。在词汇变量中,词义的具体性是对N400幅度的最强预测因子,更具体的词具有更大的N400。LSA是第一个进入回归的变量,额外的差异由前向联想强度和共现频率PMI来解释,分布相似性和后向联想强度的α水平太高了,表明如果进入回归方程,增加预测力的可能性很小。 联想强度到目前为止一直都是ERP词对研究里唯一的语义强度的衡量标准,因此值得关注的是LSA\FAS\PMI模型在多大程度上比传统的FAS标准更好地预测N400波幅。所以又创建了一个语义联想强度因素中仅有FAS的模型,结果显示,联合模型明显比仅用FAS模型的预测效用更好。 1.4词汇决定时间 词汇判断任务中的反应时的分析方法与分析传统N400波幅的方法相同。按传统二进制方法编码为前向联想强度为0或大于0时,相关词比不想关的词更快地产生词汇判断。 相关分析显示,关系强度地五个标准都和反应时呈显著的负相关。偏相关也显示所有指标也和RT显著相关。 对于词汇决定RT的最佳回归模型,解释了RT15%的变化,在词汇自身变量中,只有词频是显著的预测因素。而LSA进入之后,解释了总变异的另外的5%。
讨论 ¶
1.关联强度和词汇决定反应时 许多其他研究采用关联强度存在/不存在的二进制编码,发现了相关词对中第二个单词引发更快的词汇判断和较小的N400。然而联想强度的分级影响在词汇决定RT中很少观察到(而N400和联想强度观察到了分级效应)。因此作者认为,语义语境对词汇决定时间的影响在很大程度上反映的是一种决定策略,在这种策略中,对目标词和线索词关系的检测——弱/强——表明字母串一定是一个词,从而允许快速的反映,这与当前结果一致。 当前研究中LSA强度对整个刺激集的词汇决定时间有显著的预测作用,但这一结果并不是决定性的。 2.N400幅度:词汇变量 一些研究证实了单词特征对N400幅度的影响。目前作者使用连续变量的结果证实了之前的报告。一个比较确凿的发现是,具有更加具体含义的单词的N400更大。这种“具体性效应”被认为反映了对更多语义信息的提取,与抽象词语相比,对具体词语的感知细节更大。虽然具体/抽象,之前总是被编码成二进制,但目前结果表明它可以被认为是连续的,就像其他词汇特征一样。其他比较确凿的发现是,具有更多语义关联词的单词的N400更大,以及与其他单词有更大的拼写相似度的单词的N400也更大。这两种影响都被归因为相同的原因,即读者词汇中更多的词被部分激活。最终,回归分析还显示使用频率较低的单词的N400较大。 之前有人的词汇自身变量的N400研究也是类似的,但是也有两个差异,就是结果显示1.bigram frequency在之前的实验显著,而这里不显著,并且之前的研究没有显示出词的具体性对N400幅度的实质性影响。可能这些差异是由于刺激材料的组成不同,作者这里使用的很大的实词集,而之前学者使用的较小的实词集。 3.N400幅度:关联强度 单个词的分析也证实了N400波幅与先前研究钟自由联想任务所评估的先前语义语境的强度之间的平行关系。在某些方面,词对研究的一般程序类似于自由联想任务。目前研究的关注正是评估基于语料库的语义距离的测量与大脑电活动钟语义语境直接影响之间的关系。相关分析表明PMI和LSA在预测N400波幅方面大致相当于自由联想强度。这对研究人员有一定实用价值,因为它们可以为那些没经过自由联想测试的词来使用。 然而,回归分析显示,自由联想,单词共现和LSA相结合对N400波幅的预测最有效。这一结果可能表明,这三种测量方法捕捉到了概念结构的一些不同方面,所有的这些方面都会迅速影响大脑活动。作者提到,自由联想反应在某种程度上偏向于相似的关系,例如范畴相关的单词(狮子-老虎),共现统计PMI更适合捕捉主题关系,例如参与者、动作和对象(飞行员-飞机),LSA虽然初始输入也是共现频率,但后续加入了其他因素,结果可能介于自由联想和出现频率之间。与其他指标相比,LSA强度和N400波幅之间的联系略强,可能反映了对相似性和主题关系的更平衡的敏感性。 作者又把具有反义关系的27对单词提出来分析,比较了FAS\LSA和PMI,转换为了z分数,FAS的平均z分数最大,LSA的次之,PMI最小,LSA又占据了中间立场,这与自由联想和单词共现对语义相似性的敏感度很不同的论点是一致的。未来研究应该更有意识地改变词对之间语义关系的类型,以便根据词对关系的性质来确定N400幅度是否与其他度量更紧密地相关。 总之,这里考察地词汇和语义关系变量能够解释单个单词N400波幅地大约三分之一的差异。信噪比增强后,也许能获得更高的R2,但想必也会有一定的未知上限。 LSA和PMI指标在预测脑电活动方面的成功表明,应该可以通过ERP方法评估和比较其他基于语料库的指标。有鉴于此,人们必须思考可能能从这些指标种获得什么,例如,词共现频率应用于实际的问题,谷歌搜索时词能够自动补全就是基于共现,当然这种基于共现的实际应用有时也会出错,这是很正常的。 同样的,词对之间关系强度的测量都是于特定词语使用情况相符或不符的平均值,特定的语境可以对抗平均情况下很强的词对关系,例如默认下,胡椒和盐是高度相关的,但当特定的语境是清理结冰的人行道,相关性就会小很多。这类说法就支持词汇语义模型,该模型将单词的含义视为一组语义特征。当前结果支持了这样一种观点,即单词的统计模式共现对揭开这类组织可能有用,但是这一数据来源可能会得到自由联想规范的有益补充。