论文信息 ¶
Elise van Wonderen, & Nieuwland, M. S. (2023). Lexical prediction does not rationally adapt to prediction error: ERP evidence from pre-nominal articles. Journal of Memory and Language , 132, 104435–104435. https://doi.org/10.1016/j.jml.2023.104435
论文原文 ¶
关键词 ¶
预测效度;语篇理解;N400;
摘要 ¶
在语言理解的过程中,人们有时会预测即将到来的单词,但对于这种预测何时或在何种情况下发生仍存在争议: rational adaption假说认为,预测是随着预期效用而发展的:当预测经常得到证实(预测误差低)时,人们预测得更强烈。然后,到目前为止,支持这种观点的证据喜忧参半,并且这些证据只涉及测量对假定的预测名词的反应,而没有测量也可能被预测的名词前的冠词的反应。因此,目前关于荷兰语书面语篇理解的大样本(N=200)事件相关电位研究使用了众所周知的“名词前的预测效应”:与预期的冠词相比,对于意外性的冠词,增强了类似N400的ERPs。 研究者调查了当大多数呈现的故事包含可预测的冠名组合(75%可预测,25%不可预测)时,与大多数故事包含不可预测组合(25%可预测,75%不可预测)相比,名词前的预测效果是否更大。结果显示了在这两种情况下的名词前的预测效应,几乎没有证据表明这种影响依赖于可预测组合的百分比。此外,几乎没有证据表明这种依赖主要是在意想不到的中性文章(HET)中观察到的,这与理性适应假说不一致。与最近的演示(Nieuwland,2021a,b)一致,研究结果表明,语言预测并不像通常所说的那样“rational”或贝叶斯最优
引言 ¶
根据rational adaption假说,词汇预测是有成本也有收益的,人们通过调整预测以适应他们的预期效用来实现这种权衡:预测经常得到证实时会加强,而经常不确定时会减弱。 本文简要回顾了理论背景和经验证据,然后提出了一个关于荷兰小故事理解的ERP实验,以考察预测确认/不确认的概率是否影响词汇预测的已建立的ERP特征。 一些人认为:预测是推动递增的语言理解的一种不可或缺的机制,人们在所有表征水平上都不断预测和更新预测。 另一些怀疑者认为:预测并不是语言理解的基本组织原则,它本质上只是成功理解的副产品。 一些观点认为人们积极主动地预测,还有观点认为人们只是被动的预激活语义信息。 为了找到中间立场,Kuperberg&Jaeger(2016)建议,可以通过考虑其潜在的成本和收益来理解词汇预测的可变性质。正确的预测被认为有利于单词识别,而与没有预测相比,错误的预测会导致处理成本,这可能是因为它们需要抑制预测的单词。这些假定的成本可以帮助解释为什么只有在高度受限的上下文环境及当人们有足够的时间和可用的处理资源时,才能观察到词汇预测。当预测经常被否定而不是被证实时,人们可能会更少地参与预测 这种观点认为,词汇预测是基于理性贝叶斯原则的适应性概率过程的一个例子,人们利用其环境中的统计规律来指导行为。重要的是,rational adaption假说断言,人们根据先前遭遇估计的先验分布的可靠性来进行预测,例如,当强预测总是不被证实时,先验分布的可靠性很低,人们可以相应地削弱他们的预测,在预测成本高昂的假设下,在这种情况下,不生成任何最终被证明是徒劳的预测被认为是“理性的”,相反,当预测总是被证实时,先验的可靠性就高了,人们可能会相应地加强他们的预测。
目前研究 ¶
- 实验材料 被试阅读包含明确冠名组合的荷兰语的两句迷你故事,在目标冠词之前,每个迷你故事都强烈提示一个特定的冠词-名词组合作为最佳的延续,迷你故事要么包含预期的目标组合,要么包含意料之外的与不同性别名词的组合(这种组合并没有与上下文相悖)。研究的主要依赖指标是名词前的预测效应:预期的冠词和意料之外的冠词引起的ERP的差异。 创造240个两句话的迷你故事,它们可能会引导人们期待一个特定的、单数的定名词短语。为了确定新创建的故事是否确实对这些名词短语有足够的限制,我们以在线问卷的形式进行了完形填空测试。将目标冠名词组合从故事中去掉,让一些被试用首先想到的任何一个或多个单词来完成不完整的迷你故事。然后研究者确定了 240 个项目,其中冠词和名词完形填空都超过 75%,并且意外冠词或意外名词从未高于 15%。随后通过替换目标冠名词组合,来创造预期之外的条件。 每个被试阅读60个预期试验和60个意料之外的试验,同时阅读120个具有可预测冠名组合的filler迷你故事(共计75%的可预测刺激)或120个具有不可预测的冠名组合的filler迷你故事(共计75%的不可预测刺激),每个被试共计阅读240个故事。
- 研究预期 根据rational adaption假说:预测强度不仅取决于上下文的限制,还取决于从上下文建立的预测错误的可能性,因此,当呈现的材料主要包含的是不可预测项目时,名词前的预测效果可能会不存在或降低,反之,预测效果会增加。 另一种假设是:预测加工在不考虑潜在的预测误差时进行,因此预测的强度主要是语篇语境限制的功能,无论呈现的材料包含大多数可预测的项目还是不可预测的项目时,名词前预测效果可能是相似的。
- 程序 首先屏幕呈现十字,被试按键后在屏幕呈现故事的第一句(整句呈现),第二次按键后逐词呈现第二句(词呈现300ms接上300ms的白屏)。240个句子分为了8个block,每个大概持续8分钟。
- 结果
冠词部分:
对ERP特征的目视检查显示,无论是在填充句是可预测的还是不可预测的情况下,意外物品都比预期物品引发了300-500ms更多的负电压。
在300-500ms中,研究者证实了整个数据集中(b = -0.75 μV, SE = 0.10, 95 % CI [- 0.94, - 0.56],在全是预期内的填充句条件下(b =-0.85 μV, [-1.10, -0.59],在全是预期外的填充句条件下b = -0.65 μV, [- 0.92, - 0.40]都存在着预期的影响。尽管这种预期影响在预期内填充句条件下看上去在数值上更大,但没有统计学证据能够支持这种交互作用(b=0.20μV,SE=0.18,[-0.15,0.55])。然而,这种交互模式几乎完全是由对意料之外的冠词的回应引起的,相比于全是预期外的填充句的条件下,在全是预期内的填充句的条件下,意料之外的冠词“het”引起了更多的电压 (b = 0.21 μV, [-0.14, 0.55]),这与rational adaption理论相悖,该假说规定只改变可预测单词的加工。 名词部分: 图像及统计学数据都显示,意料之外的名词在两种填充句条件下都引起了N400,尽管这种影响较小,同时在500-700ms处还有post N400 positivity。同时统计学数据显示这两种填充句条件下N400电压非常相似。同时也没有证据显示500-700ms的PNP与填充句之间有交互作用,两种填充句条件下,500-700ms电压差距不大。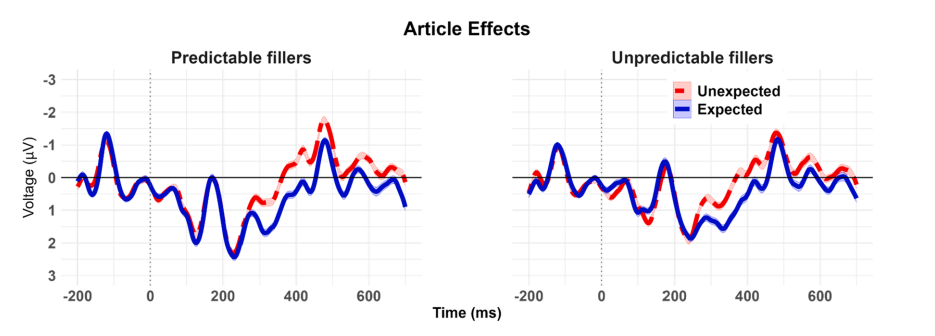
在没有合理适应的证据的情况下,我们只能得出结论,要么我们的参与者一开始没有估计出预测错误的可能性,要么他们估计得完全不准确,要么他们(大致)估计得正确,没有相应地调整他们的预测。
讨论 ¶
当前研究未能揭示语篇理解过程中的词汇预测会受到总体预测成功率的影响,研究者的确观察到了很强的名词前的预测效应(即冠词引起的N400),但结果不支持可预测/不可预测填充句对命名前预测效应的调制,贝叶斯因子分析支持零假设。 尽管在数值上看,在预期内填充句的条件下比预期外填充句条件下u更大,但这种模式并不符合rational adaption假说,因为填充句的影响主要反应在冠词het中,而冠词de的N400在两种填充句条件下没有大的变化。而随冠词后出现的名词的N400效应比冠词小,但也没能显示出rational adaption的证据。 研究者得出的结论是,被试要么没有根据预测成功的(估计的)概率合理地调整他们的预测,要么对预测成功的估计不准确,要么根本没有估计。 语料库数据表明de和het在词汇频率和习得方面存在差异,de的出现频率是het的2到3倍,发展研究也表明儿童和二语者在学会het之前使用de,这些表明de是典型的,而het是非典型的(marked)为什么de的名词前的预测效应小于het(即预期外的de引起的N400小于预期外的het引起的N400)? 假设1:由于过度泛化/概括,理解者可能对de的错误使用降低了敏感性导致N400小 假设2:被试预期频率较高的冠词出现,但由于het是一个频率较低的冠词,因此预期外的het特别具有破坏性。 假设3:de可以放在所有复试名词前,如果预测词组是het book,当出现de时,被试可能认为是de books,det可以放在所有小称的名词前,如果预测词组是de apple,出现冠词het时,被试可能认为是het small apple,可能前者比后者更容易适应。 那么为什么观察到的效果可能取决于填充句的类别呢? 解释1:在预期外的填充句条件下,参与者对于意料之外的het相对没那么敏感,因为重复对有标记的物品的影响比对未标记的物品更大。 解释2:被试变得更善于适应对预期外的het的小称解释。
有意思的一点 ¶
同行评审中有一个concern这样认为:研究的操作不够强,无法引起适应,因为研究的目标词嵌入了两句话的故事之中,因此目标词不在关注的焦点,以往的研究都是用单句话,把目标词放在句末,并且由于有两句话,因此上下文可能会包含更多其他的冠词和名词,从而影响预测。 这提出了一个更根本的理论问题:如果人们理性地调整他们的预测,他们如何知道what to adapt to? 根据语言理解的预测解释来看,听者总是在不同程度的表征水平上预测即将到来的信息,因此预测误差是高度可变的,并且随着时间的推移起伏不定的,因此只有在理解者选择要适应哪些预测误差信号的情况下,rational adaption才似乎是可行的,这可能就是目标词的位置带来的影响,如果目标词一直在结尾,那么句子的结尾可能会作为提示,让理解者只适应与最后一个词相关的预测错误,也许只有在人们特别注意这些词的情况下,才会调整他们对句末单词的预测。 虽然这可能适用于那些目标很容易被参与者推断甚至明确告知的实验(如目标词全部在词尾),但这显然提出了一个问题,即理性适应到底有多有用(多广泛) Even if speakers in real world conversations produce many predictable or unpredictable words, they are unlikely to do so for a fixed sentence position or for predominantly sentence-final words 因此,在一个更丰富的迷你故事中嵌入目标词是一个特点,而不是一个缺陷,因为它使我们能够研究rational adaption的可推广性
总结 ¶
研究者观察到,无论预测否定刺激的比例如何,都会产生名词前预测效应。此外,支持这一比例影响的证据很少,主要是在出乎意料的中性文章(“het”)中观察到的,这与预测的理性适应假设不一致(Kuperberg&Jaeger,2016;Yan等人,2017)。研究者得出的结论是,被试主要基于话语上下文约束产生预测,而不考虑预期效用和预测误差。研究对人们是否估计了他们预测的可靠性并相应地调整了他们的预测提出了质疑。语言预测可能不如通常所说的“理性”或贝叶斯最优。