文献:Planton, S., Al Roumi, F., Wang, L., & Dehaene, S. (2022). Compression of binary sound sequences in human working memory. bioRxiv, 2022-10. https://doi.org/10.1101/2022.10.15.512361
论文原文 ¶
1. 背景及本研究 ¶
序列处理,是人类几种活动的核心(Lashley, 1951),本研究作者认为以层级结构表征序列是源于语言的人类的独特的能力,因此人类也能表征一个类似语言的嵌套规则系统,即“思维语言”,例如把“xxYYxYxY”序列编码为“2组一对,2组交替”。
Al Roumi et al (2021)用脑磁图证明了在提出的LoT(language of thought)中假设的空间、序数和几何原始码可以从大脑活动中提取,本研究想探索 LoT是否也能解释人类的二元听觉序列的记忆。探寻非人动物是否能储存人类口语句意义不大,而给非人动物呈现具有最少二进制的声音序列探寻它们是否使用类似递归语言的格式在工作记忆中进行编码,或者是否局限于更合理的统计学习或组块(这种机制对于人类成人、儿童和多种动物在序列加工的多个方面具有重要作用)。然而,很少有研究将基于规则的预测的大脑机制与概率序列学习的大脑机制分开。本研究的目的是开发一种范式来测试“人类的内部模型是基于一种递归的思维语言”的假说。
目前的研究主要是行为实验(Planton et al., 2021),并证明了人类对二进制声音序列的记忆(通过异常声音刺激监测)可以由修改后的几何语言预测,实验中包括6到16个不同长度的序列,并且MDL精确地预测了偏差刺激监测的表现,并比较了LoT与认知复杂度的竞争模型和信息压缩的预测能力(Aksentijevic & Gibson, 2012; Alexander & Carey, 1968; Delahaye & Zenil, 2012; Gauvrit et al., 2014; Glanzer & Clark, 1963; Psotka, 1975; Vitz & Todd, 1969),结果是LoT的预测能力最好。
本研究使用fMRI和MEG研究人类大脑中所提出的语言的大脑基础,将受试暴露在具有不同层级规律性的长度为16的二进制声音序列,同时在两个实验中用 fMRI 和 MEG 记录他们的大脑活动(如下图1所示)。
2. 材料和方法 ¶
2.1 受试 ¶
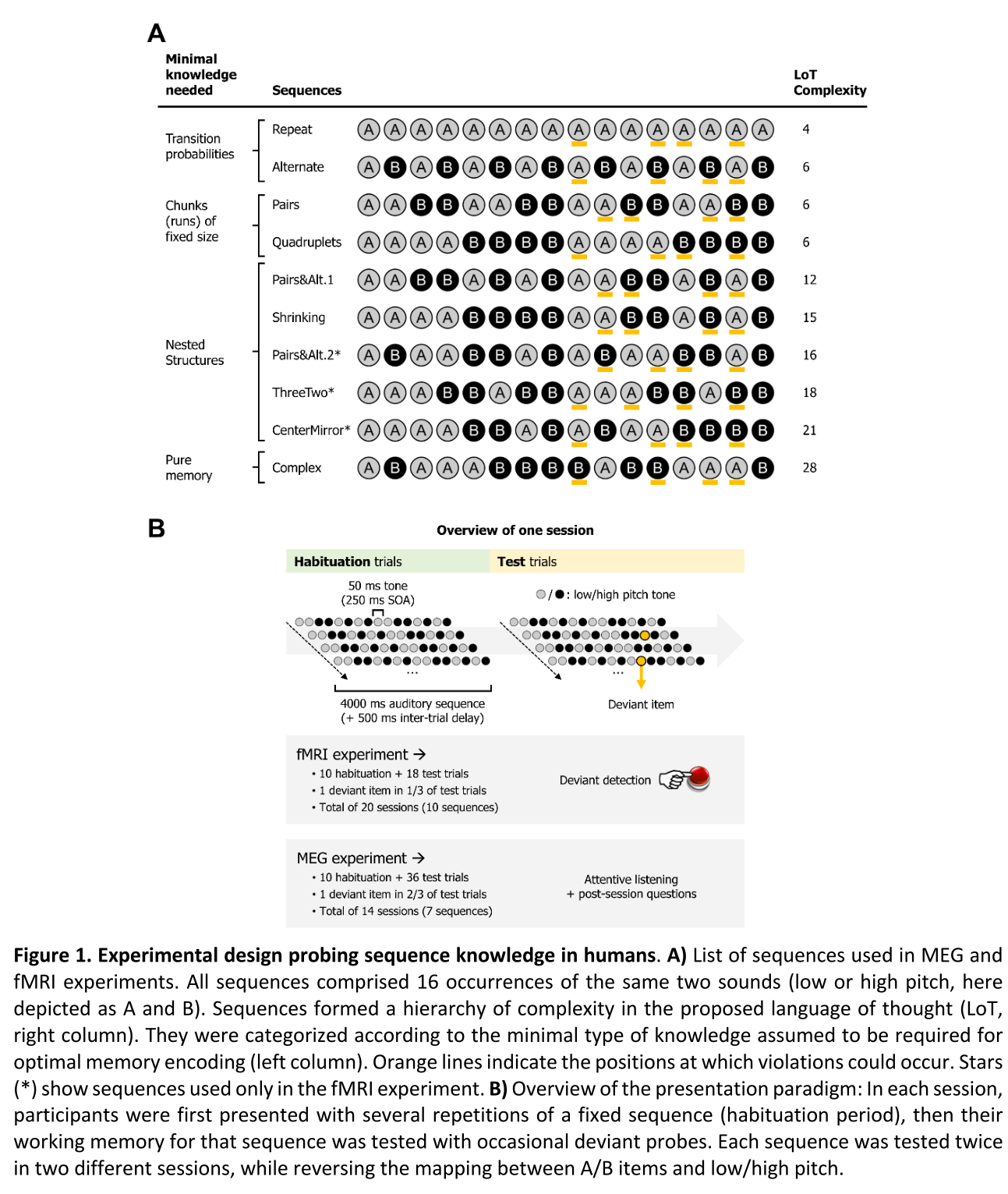
19名参与了MEG实验,23名参与了 fMRI实验,二进制听觉序列由16个高音和低音组成,每个音持续50ms,每个音固定间隔为250ms,共10个复杂程度不一的语音序列。
3. 结果 ¶
3.1 刺激设计 ¶
刺激为固定长度为16项的层级序列,按照“思维语言”(Planton et al., 2021) 层级的复杂程度有系统的变化。首先有很多证据表明在序列输入时大脑同时编码例如过渡概率等的统计规律并用这些统计规律做预测 (e.g. Barascud et al., 2016; Bendixen et al., 2009; McDermott et al., 2013; Meyniel et al., 2016; Saffran et al., 1996),这也是各种非人类动物都能掌握的能力(e.g., Hauser et al., 2001; Meyer & Olson, 2011)。
其中前两个层级序列由重复(AAAA…) 和交替策略组成(ABABA…),就信息压缩角度而言,这种序列用LoT模型描述非常短,其中重复和交替也是更复杂序列操作的基础。
下一个层级中,研究测试了chunking能力,这是非人灵长类动物也可利用的另一种主要序列编码机制(Buiatti et al., 2009; Fujii & Graybiel, 2003; Saffran et al., 1996; Sakai et al., 2003; Uhrig et al., 2014),因此,包括成对序列(AABBAABB…)或4个为一对的序列(AAAABBBB…),从 LoT模型来看,它们依然具有高度可压缩性,但是已经具备了一定的层次性(chunks的循环),与上一等级的序列相比,受试还需要监测在新chunk出现之前的重复次数,因此可能会设计计数系统,可能涉及双侧顶内沟,特别是它们的水平和前段(Dehaene et al., 2003; Eger et al., 2009; Harvey et al., 2013; Kanayet et al., 2018)。
下一个层级则探测了更抽象的序列编码,需要嵌套结构,尽管非人动物能否表征这一层级,尤其是在训练之后是,尚存在争议(Ferrigno et al., 2020; Gentner et al., 2006; Jiang et al., 2018; van Heijningen et al., 2009),大部分人都认同,人类可以从这种序列学习中快速通达,并认为这是与许多相关认知领域相关的潜在的人类独有的特质(Dehaene et al., 2015; Fitch, 2004; Fitch & Martins, 2014; Hauser et al., 2002) 。研究使用复杂但可压缩的序列来探测,例如“AABBABABAABBABAB” (它的层级描述为[A²B²[AB]²]²,意译为“两对重复,四次交替”),不管序列的层级深度,当一个chunk需要重复时,LoT模型只需要多加一个bit就可以轻松描述这种嵌套结构(Amalric et al., 2017)。
作为对照,范式也包含最小可压缩序列以平衡过渡概率和最小chunking可能性(???),并选取了预计具有最大复杂性 (最高的 MDL)的序列,预计会挑战工作记忆的极限,由于序列复杂,研究预计大脑参与嵌套序列编码,但不再表现出进一步的激活增加或激活减小(Vogel & Machizawa, 2004),可以通过MDL的二次对比而不是纯线性回归模型来测试这种非线性趋势在最高复杂性水平的存在。
3.2 行为数据 ¶
在脑成像之后,让受试在听完音频序列后根据直觉从语法的角度上给视觉呈现的序列画括号,结果(图2A)表明受试分析序列和使用恰当的括号级别标注嵌套序列与预想一致。 为了评估LoT模型的解析和组织,分析了受试群体与LoT模型对序列括号数相关性,发现序列的重复、成对、4个为一组、压缩、成对&交替、3+2、中心对称以及复杂的都有很强的相关性,但没有交替,因为在LoT描述为“16个交替”,而受试群体解析为“8个AB对”,而后一种解析的复杂程度更好,所以这个偏差不影响序列结果。
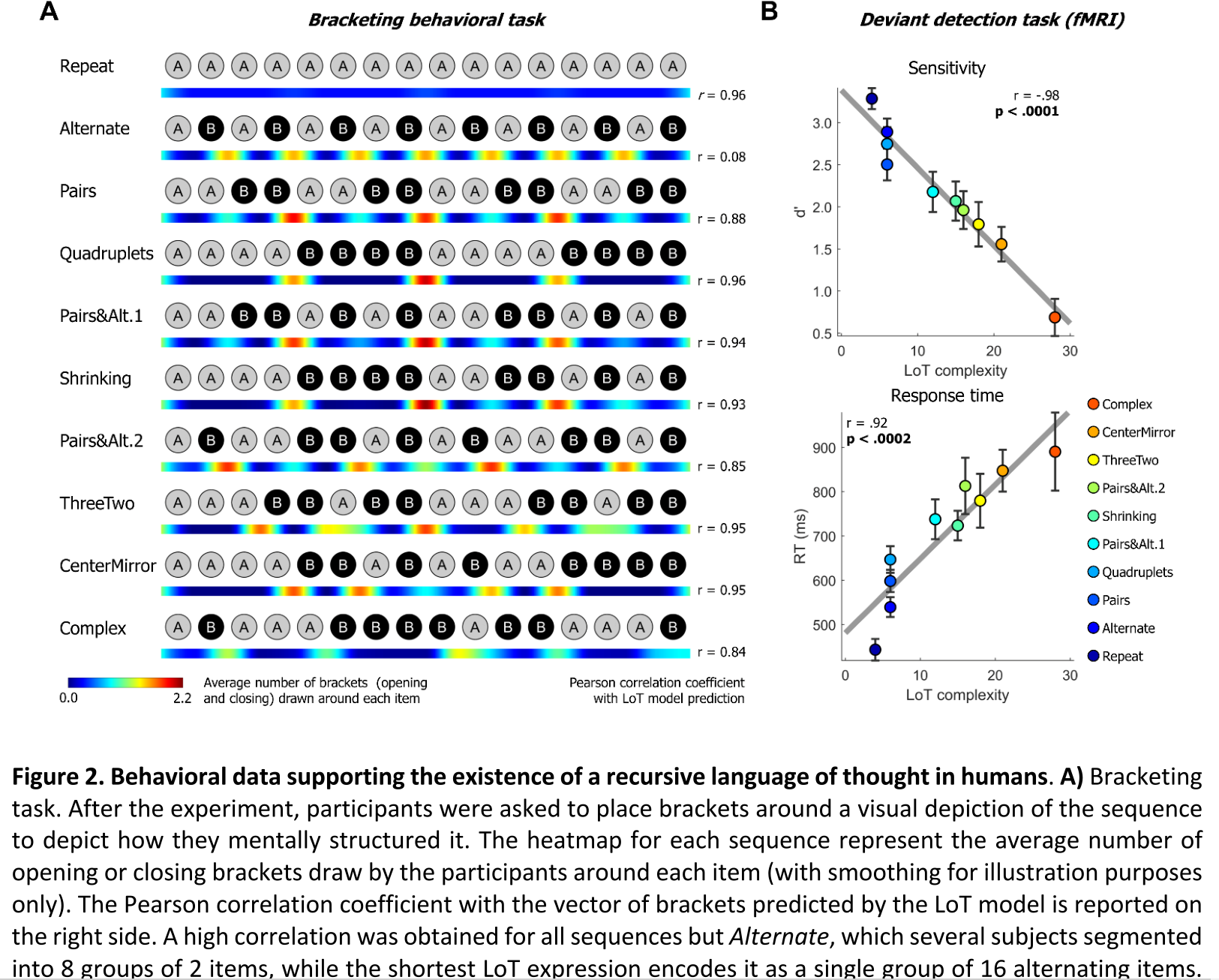
研究又评估了这些结果是否可以由统计学习解释,似然比测试结果显示给 LoT 线性回归中加入过度概率的测量使拟合优度略有提高。行为方面的结果重复了Planton et al. (2021) 的发现,即尤其是对于那些长的超过记忆容量的序列的违反监测(学习质量指数)和反应时(预测程度的潜在指数)可以被序列压缩的思维语言模型很好的预测。
3.3 fMRI 数据 ¶
1)复杂性对序列学习和跟踪的积极影响 ¶
如预测,在序列学习阶段,在一个广泛的双边网络中,激活主要随着序列复杂性的增加而增加,该网络涉及补充运动区(SMA)、与Brodmann区44的背侧部分邻接的中央前回(preCG)、小脑(第六和第八小叶)、颞上回和颞中回(STG/MTG)以及前顶内沟区(IPS,靠近其与中央后回的连接处),这些区域与Wang et al. (2019)研究中类似语言的完全不同的视觉空间序列的序列学习中的激活区域有部分重合。
然后对比了测试阶段标准同样的trial(不包含偏差刺激),网络区域显示出积极的复杂性效应,即比学习阶段的激活更小,包括延伸到楔前叶、左侧背侧运动前区以及两个小脑区(右小叶IV、左小叶VIII)的双侧顶上皮层。
2)复杂性对异常反应的负面影响 ¶
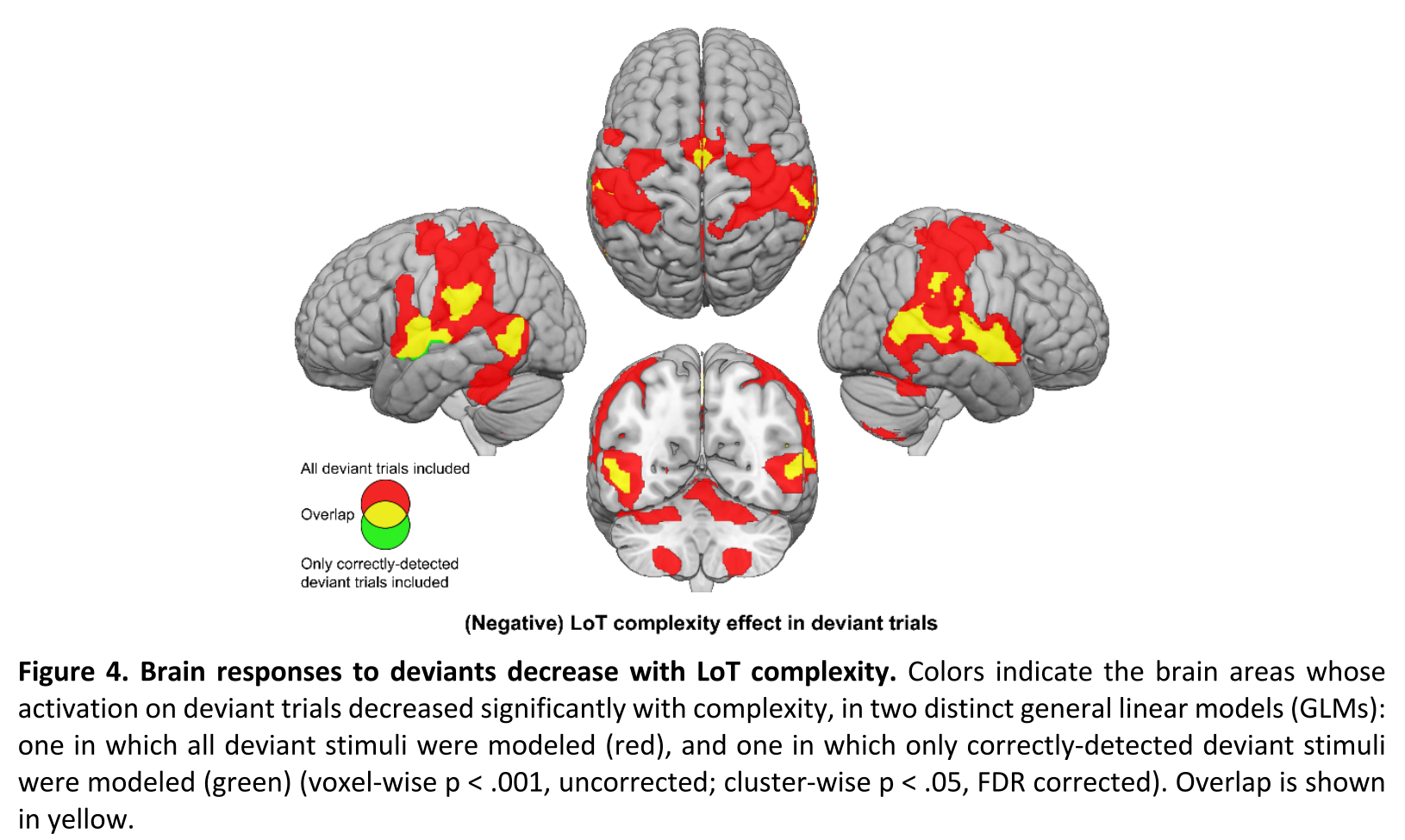
首先根据对所有异常刺激(无论是否检测到)的反应,评估整个大脑水平的LoT复杂性的影响,只在额上回(SFG)的内侧部分的一小簇中发现复杂性的正性效应,和预测一样,在更广泛的网络中发现了负性效应(即随着复杂性升高激活减少),但是这可能部分来源于运动效应,因为在更复杂的序列中手部操作对偏差刺激的反应的频率更低,然后研究又计算了只有受试做出正确反应的,结果仍然表现出LoT复杂性的负性影响,区域为之前的一部分如下图4所示。
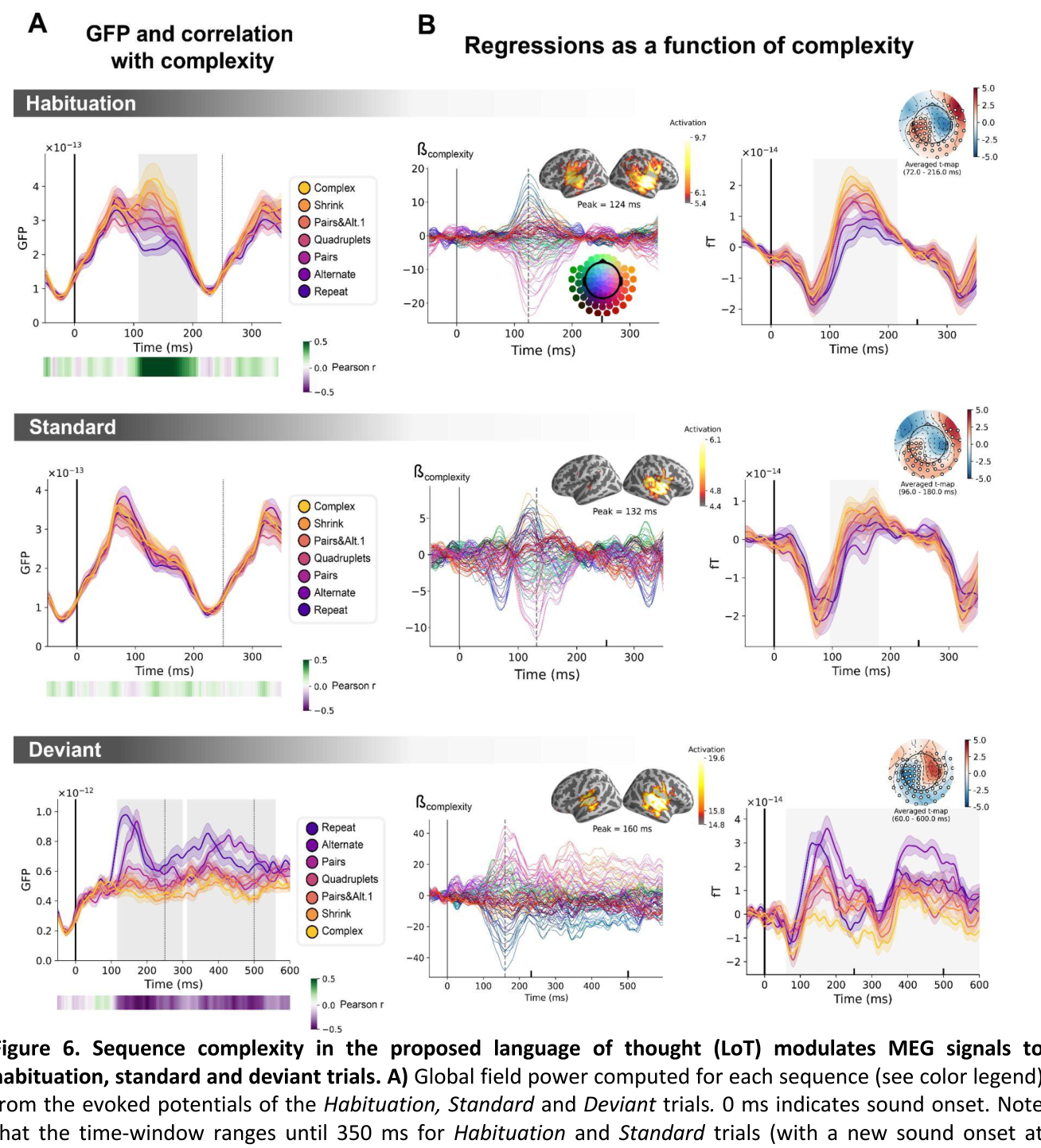
3.4 MEG结果 ¶
在MEG实验中,只让受试认真听声音序列而不用做任何按键反应,从而产生存粹的违规监测测试。结果如下,在习惯阶段,GFP(Global Field Power)随着序列复杂性的的增大而升高。