文献:Yang, J., Cai, Q., & Tian, X. (2020). How do we segment text? Two-stage chunking operation in reading. Eneuro, 7(3). https://doi.org/10.1523%2FENEURO.0425-19.2020
论文原文 ¶
1. 研究背景及本研究 ¶
阅读可以说是人类独有的智能之一,但是我们如何处理复杂的书写句子仍是未知的,一个句子由许多字母或字符组成形成一个文本层级结构(字,词,短语),读者需要逐渐将一个复杂的句子分割成更小的块,映射到他们的心理词汇中,这个过程被称为text chunking(Reali and Christiansen, 2007; Gobet et al., 2016),有哪些小chunk,我们如何加工chunk
在心理语言学和计算机科学的阅读模型中,词及语素通常被假定为基本单位 (McClelland and Rumelhart, 1981a; Coltheart et al., 2001; Taft, 2013),但是眼球追踪研究表明,我们一次可以感知比一个单词更长的文本信息 (Rayner, 1998),这表明多次加工和此外加工是可行的,依靠更大的组块有效地减少了处理句子时的认知负荷:需要解释和整合的组块更少(Ellis, 2003; Krishnamurthy, 2003; Blache and Rauzy, 2012),并且成分的语义组合可以不同于整体意义(Goldberg,1995),例如习语的隐喻可以不同于较小成分字面意思。单词chunk和多词chunk的关系是怎样的?复合词的研究可能会提供有关线索,根据复合词加工的双轨制模型,同时加工整个词和它的组成部分,或者灵活选择加工每一级(Andrews et al., 2004; Koester et al., 2007; MacGregor and Shtyrov, 2013; Semenza and Luzzatti, 2014; Blache, 2015),研究假设所有熟悉的词块,不管是哪一级的,都可以被同时处理。更具体地说,语块的检测将是分块的第一步,并且在多个级别上的语块检测将同时发生,正如早期的词汇熟悉度检查在E-Z读者模型中所假设的那样(Reichle et al., 2003)。
组块过程中多级运算是如何展开的?被检测到后哪个级别有优先权?单词优势效应表明单词中的字母比非单词中的字母或独立的字母识别得更好(Reicher, 1969),这表明在阅读中单词比字母优先,同样,整体组块的优先处理可以减少整合的步骤,避免歧义,提高语言处理的效率(Ellis, 2003; Krishnamurthy, 2003; Blache and Rauzy, 2012),根据单词优势效应,研究假设整体组块优先于部分组块,在检测后的加工阶段首先启动。
本研究中使用汉语四字序列来探究阅读中的chunking操作,四字序列包括两个层级的chunk(2字的chunk和4字的chunk),包括四种类型的刺激(短语、习语、随机单词和随机字符)。在行为实验中,通过一项词汇决策任务,考察了阅读中整体组块和局部组块之间的相互作用。然后在EEG实验中考察多级组块操作中检测和识别阶段的时间动态。
2. 材料和方法 ¶
2.1 被试 ¶
16名汉语普通话母语者,平均年龄21岁。
2.2 刺激 ¶
所有的刺激都是四字序列,设计这些刺激是包含两个因素,第一个因素是四字序列包含两个层级的chunk(2字chunk和4字chunk);第二个因素是每个chunk的词性(真词或非词)。这两个因素完全交叉,产生四种类型的刺激(如下表1)。用大写字母表示组块大小,G表示global ,L表示local,用小写字母表示每个组块的词汇性(w表示word,n表示nonword),例如GnLw在整体水平上是由两个在局部水平上的两个word组成的四个字的nonword,而GwLn刺激条件代表中国“成语”。

GnLw刺激是通过随机配对两个不同的二字词产生的,GnLw和GwLw中的Lw遵循相同的标准。所以GwLw和GnLw之间唯一的区别是在global层级上词的性质,GnLn刺激是由字随机组合而成。所有刺激中使用的字符的对数频率范围为3.011至5.344,笔画数范围为4至13。
单词和非单词之间的区别进一步受到熟悉程度的控制。12名没有参与主要实验的参与者被要求对整个四个字或两个字的熟悉程度进行评估。评分范围从1到5,其中1代表不熟悉序列/非单词,5代表熟悉单词。从2到4的序列被移除,剩下的刺激要么是非常熟悉的单词,要么是非常陌生的非单词。每种条件下的80个刺激从库中随机选择并用于本研究。
2.3 行为实验流程 ¶
开始让被试盯着屏幕中央的+号,400ms之后+号消失然后呈现一串4字的序列一直到被试作出反应之后消失,在整个四个字符的字符串下或者在两个字符的字符串下呈现一条线,要求被试尽快按下键盘上的“F”或“J ”来对带下划线的字符串做出词汇决策,下划线为整个字符串(此后为global任务)或前两个或后两个字符(此后为local任务),最多有3秒钟的时间来回答。收集反应和反应时,被试的反应键是平衡的,trial之间的间隔为800 到 1000 ms。
四种刺激类型(GwLw、GwLn、GnLw和GnLn)与任务类型(global任务与local任务)完全交叉,产生八种condition,共包括320个trial,condition的顺序也进行了平衡。
所有被试回答准确率超过85%,平均准确率为92%,在分析之前把错误反应的trial删除。对反应时数据应用了重复测量三向方差分析(方差分析),包括global水平词汇性、local水平词汇性和任务因素,然后用t检验来检验特定假设。
2.4 EEG实验流程 ¶
同一组被试参加EEG实验,使用的刺激也与行为实验一样,但流程和任务不同。首先,每个字符串持续时间为300ms,要求被试阅读下划线部分的字符,但不做词汇决策任务,在global任务中使用了所有320个字符串,每个刺激类型80个,在local任务中重复一次。320个四个符号串包括在脑电图实验中作为视觉基线。符号串trial中的符号是从四个符号(□,△,◇和○)中随机抽样替换的,同时包括下划线的呈现也和字符串中的一样。其中一半随机trial用于global任务,另一半用于local任务。为了保证被试对刺激的注意力,随机插入了100ms的数字串,并要求参与者通过按键盘上的数字按钮来报告带下划线的数字。
(1)EEG数据采集和分析 ¶
采用32导,电极阻抗保持在10 kV以下,据采样频率为500 Hz,在线参考Cz点。EEGLAB对脑电数据进行预处理,数据经过带通滤波(0.1-30Hz),并且重新参考平均参考值,预处理分段为刺激呈现前的200ms和呈现后的800ms,去除伪迹,然后对每种情况下的时间点进行平均,并产生事件相关电位(ERPs)。
3. 结果 ¶
3.1 行为结果 ¶
反应时受三因素的影响,包括整体词汇性质、局部词汇性质和任务,global层级的词汇性质效应是显著的,表明被试辨别global层级的非词要比global层级的词要花费更长的时间;local层级的词汇性质效应也是显著的,表明被试辨别local层级的非词要比local层级的词要花费更长的时间。而任务的主效应是不显著的。这三种双向交互作用是显著的。
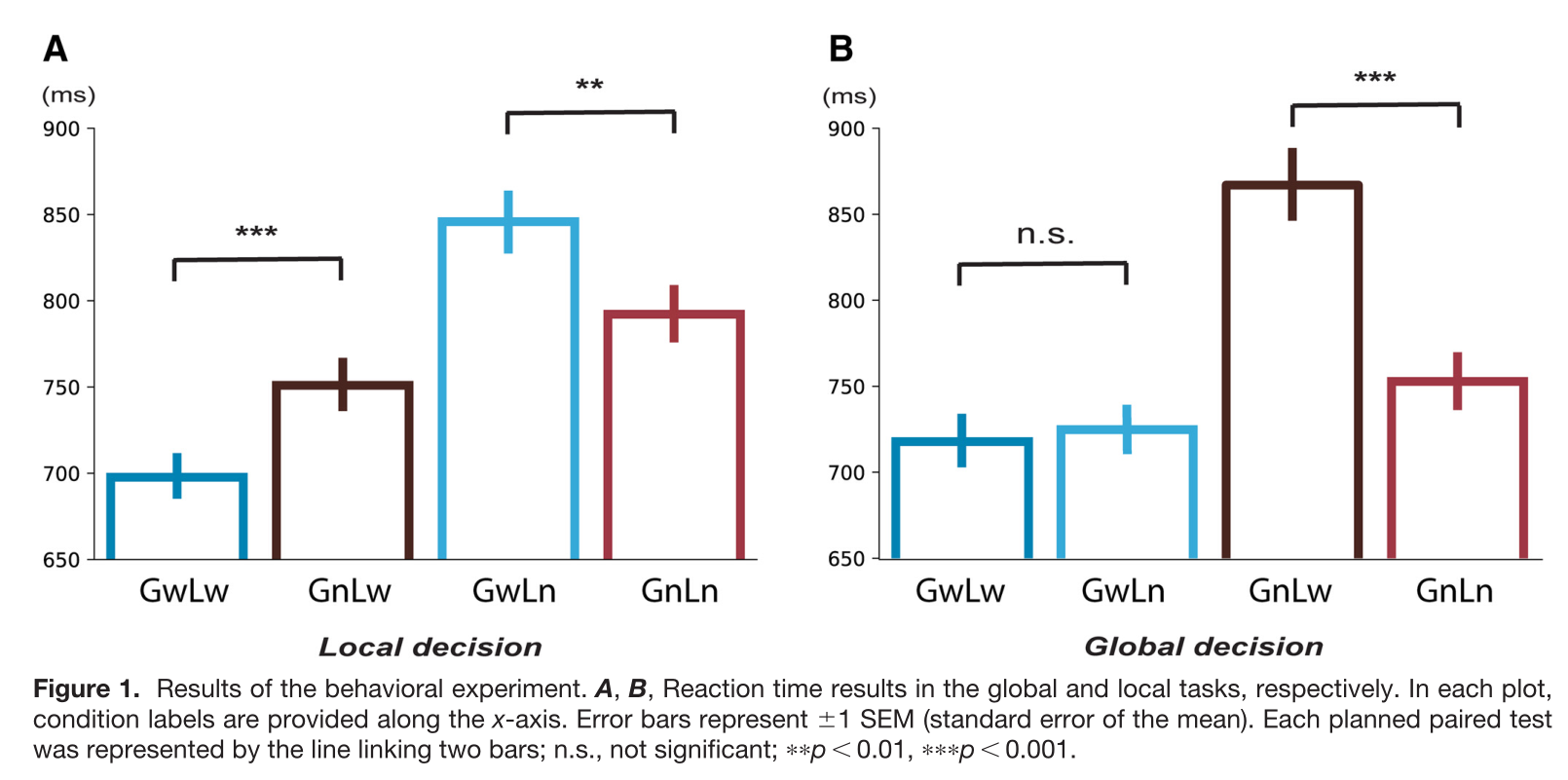
如下图1A所示,在local任务中,GnLw的反应时显著长于GwLw,表明在global水平上的非词显著地减慢了在local水平上的单词的词汇决策;在local任务中,GwLn的反应时间明显长于GnLn,表明在整体水平上的单词也减缓了在局部水平上的非单词的词汇决策。下图1BGwLw与GwLn之间的比较表明局部组块的词汇状态不影响整体组块的词汇决策。这些结果共同表明,global处理可能优先。
3.2 EEG结果 ¶
(1)聚类分析揭示chunking的不同阶段 ¶
在所有条件下,聚类分析揭示了清晰的时间剖面。下图2A中的黑线代表32个电极通道在不同条件下的平均ERP反应,红线代表所有条件下的RMS结果。下图2B表示的是四种条件下时间聚类拓扑结果,不同的颜色代表不同的聚类,同样的颜色代表同样的聚类,具有相同的特征,但出现时间有不同,不同的聚类的颜色温度代表相对于基线的排列等级。首先,在刺激开始后大约80 ms的基线期以及时期结束时(刺激呈现后的600 ms)观察到相同的簇;5种condition下在约80 ms时呈现了新的聚类,具有与N1/P2成分(视觉处理)相似的潜伏期。在200ms后观察到了不同的动态,symbol条件下第三个聚类出现的更早,此外,在symbol条件下,第三簇紧接着第六簇,在四个实验字符串条件下,第六簇直到500 ms才出现,在symbol条件下,早开始且持续时间长的第六组伴随着第一组和第二组的缺失,在其他条件下,第一组和第二组的缺失出现在320 ms左右,并持续到450 ms。
同时也观察到了后期反应的显著差异,GwLn有一个从150 ms开始的显著性集群,随后GwLw有一个从190 ms开始的显著性集群,GnLw直到230ms才有,这些在较晚阶段的潜伏期差异表明,词汇过程可能首先发生在global水平。
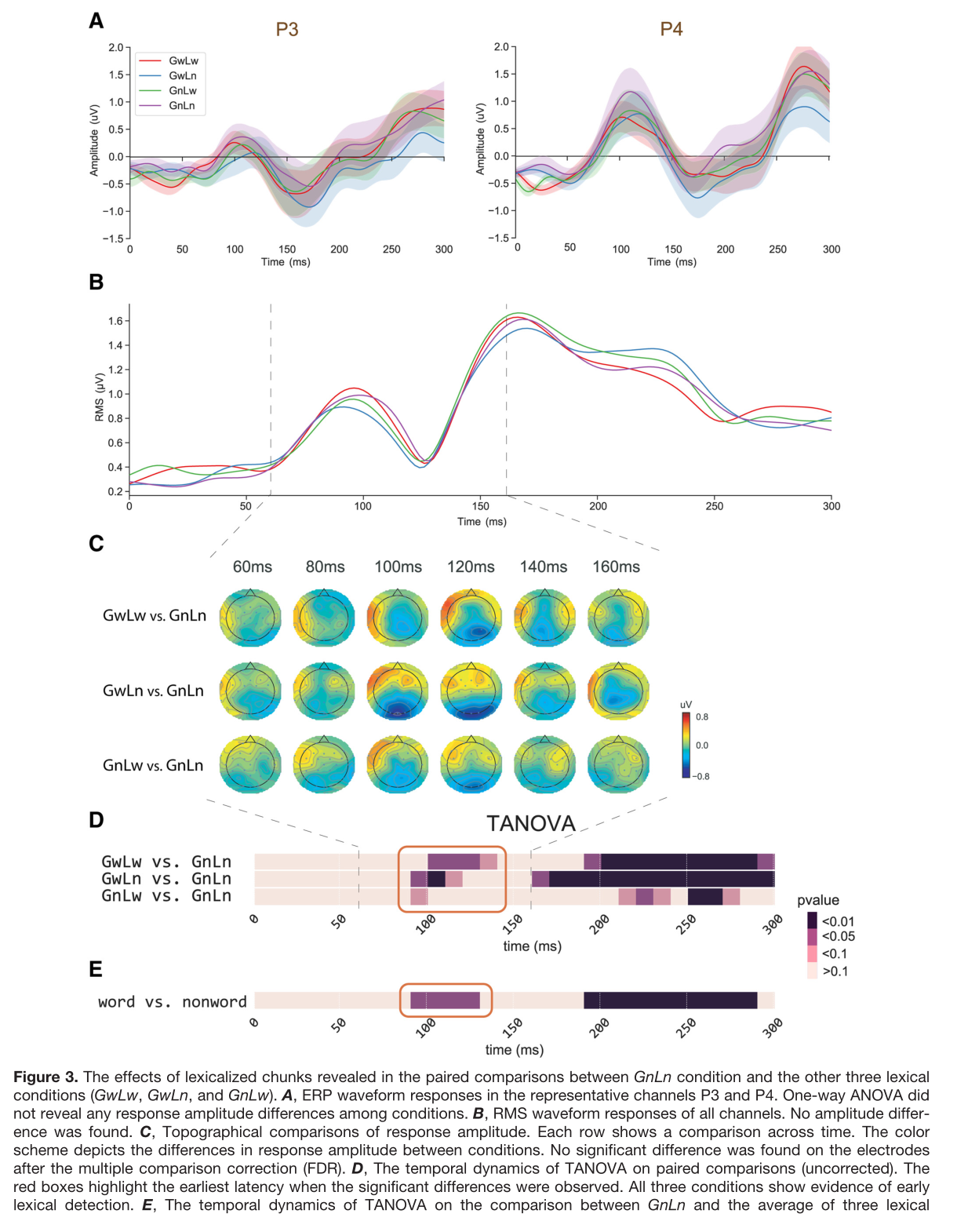
(2)不同层次的语块加工 ¶
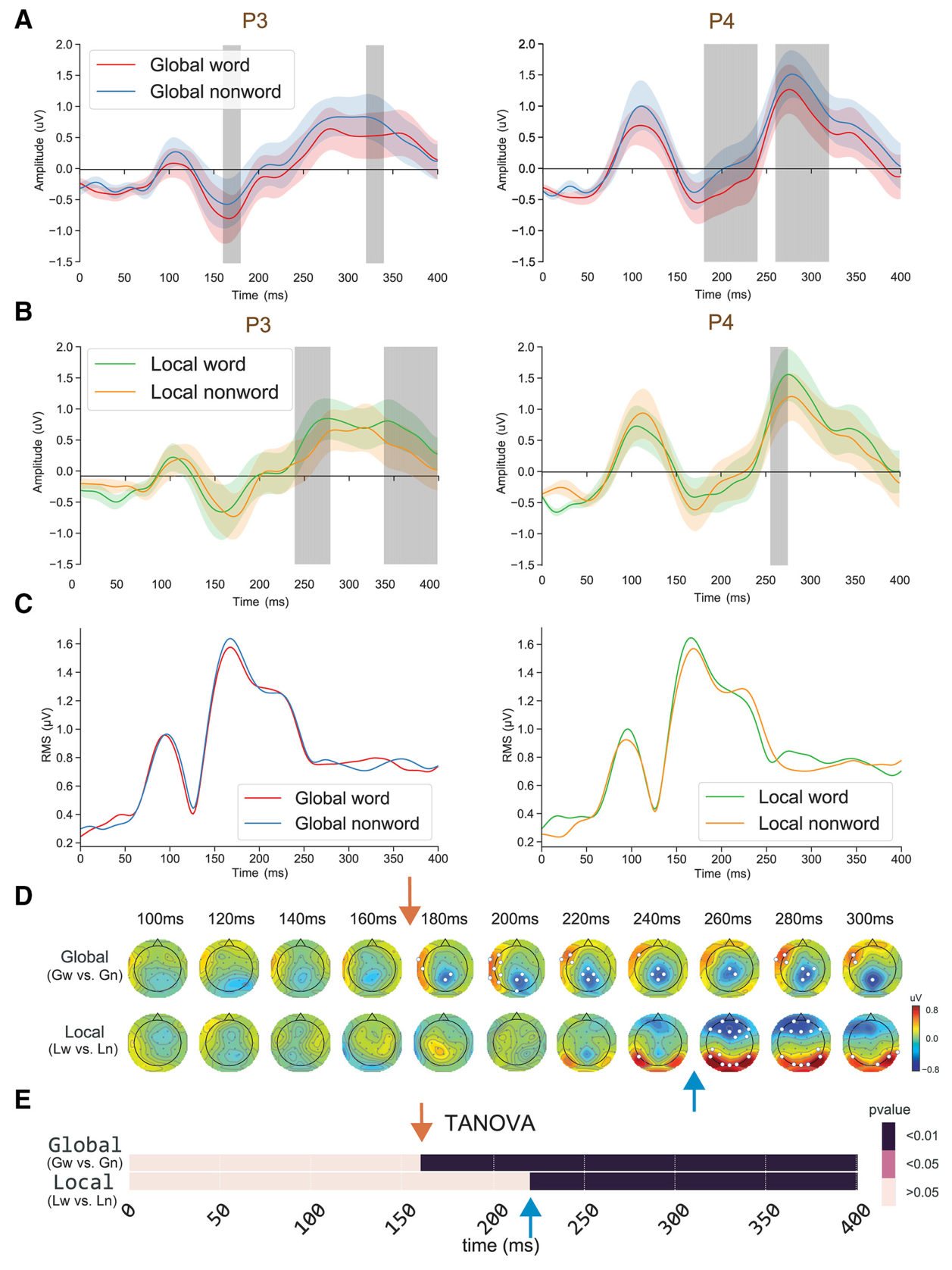
研究分别比较了global水平和local水平在P3和P4通道的word和nonword的ERP(图4A,B),以及所有渠道的RMS。发现词汇效应在global水平上早在160ms就出现了(灰色区域代表P<0.05),但local水平约在250ms出现。这个效应仅在选定的顶叶通道出现,在RMS中不存在,表明这些影响分布很窄,这与图4D中的分布结果一致。
4. 讨论 ¶
行为实验表明local词块的词性判断受global水平词性的影响,但反之则不然。这个结果表明在阅读过程中global层级词的过程的加工优先与local层级词的加工。此外,最早的脑电反应在词汇化和非词汇化组块之间表现出不同的模式,并且当在global水平上处理组块时,连续的脑电反应的潜伏期比在local水平上处理组块时更快。这些一致的行为和电生理结果表明,在阅读的早期阶段,两个不同的阶段相继运作,以检测潜在的语块,并在多个层次上对检测到的语块进行进一步处理。在语言学中,单词优势效应(Reicher,1969)是单词在识别字母时的一种优势,它表明在整体水平上对单词的处理与字母识别相互作用(McClelland and Rumelhart, 1981b)。本研究进一步证实了短语对词的影响,本研究把global优势扩展到了文本语言的层级结构中。