文献:Frank, S. L., & Yang, J. (2018). Lexical representation explains cortical entrainment during speech comprehension. PloS one, 13(5), e0197304. https://doi.org/10.1371/journal.pone.0197304
论文原文 ¶
1. 研究背景及本研究 ¶
分层句法结构在句子理解过程中的确切作用存在着很大的争议,一些人认为完整的分层分析是理解过程的一部分,另一些人则认为更浅的甚至无分层的处理是常见的。Ding、Melloni、Zhang、Tian和Poeppel最近提出的证据表明,语音感知过程中的皮层诱导反映了简单句的等级结构的神经跟踪,这支持了句子分层处理的观点。这些研究中以固定频率给被试呈现四音节句子(句法分层结构如下),脑磁记录结果表明能够观察到对应单词,短语以及句子频率的峰值。丁鼐等人认为这些峰值反映了大脑对三层语言结构的追踪,而当给被试呈现无序的随机音节时,只能观察到4Hz的峰值。但当把实验材料改为1-3的短语结构时(例如,喝丨龙井茶)时,只能观察到1Hz和4Hz的峰值,没有2Hz,因为没有语言单位是以2Hz的频率出现。
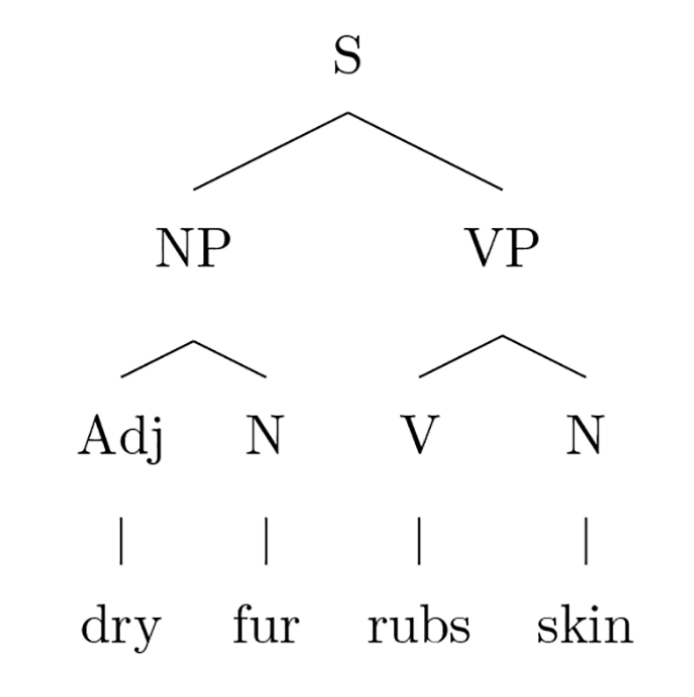
本研究的模型将丁鼐等人实验中的刺激表示为高维数值向量序列。这是由分布语义模型分配的(训练大量的英语或中文文本),这样两个词往往出现在相似的本地上下文接受相似的向量。因此,向量之间的相似性反映了所表示词的语义/句法属性之间的相似性。例如,无生命名词“fur”和“skin”会有类似的表示,它们会与有生命名词“rat”的向量有不同,而有生命名词“rat”又与动作动词“rubs”的向量截然不同。心理语言学家认为,有关语言分布的信息在一定程度上构成了词义知识的基础。语义分布在语义理论中的影响力很高,并广泛应用于计算语言学,在自然语言加工应用中产生了最先进的结果。词的向量表征解释了心理语言学的实验发现,并与皮层表征不无关系:它们已被证明可以解码单个单词理解或叙事阅读期间的神经活动,向量之间的距离可以预测书面语和口语理解期间的神经激活。本研究中不比较向量(距离)与神经激活,而是直接计算序列向量的功率谱。表征丁鼐等人不同条件下的刺激的向量序列导致的功率谱与人类被试的结果非常相似,因此皮层诱导的结果不一定是分层结构的监测或构建。
2. 方法 ¶
2.1 材料 ¶
材料使用的是丁鼐等人研究中的,其中有60个如上图1所示的英语四词(单音节词)。把中文的材料改为拼音,因为原实验是以听觉形式呈现的,相同的拼音对应很多不同的汉字,因此汉语口语和书面语两种呈现模式有很大差异。因此,分布语义模型只有应用于拼音形式,才能充分捕捉到口语刺激形式的词汇信息。
有两组50个四音节的汉语句子,一组句子是类似于“老牛耕地”( “laoniu gengdi)的2-2结构的句子,另一组是类似于“蒸灌汤包”(“zhēng guàntāngbāo”)的1-3的句子;只包含动词或动词短语的音节串是从从[N V(P)]句中提取动词(短语)部分来构建的;打乱随机音节序列是通过随机重新分配音节到[N V(P)]句子,同时保留每个音节在句子中的位置来构建的。
2.2 代表词汇知识 ¶
① 分布语义 ¶
利用Skipgram分布语义模型(Mikolov et al., 2013)生成英汉词汇向量表示,即一种具有N个隐藏单元和输入/输出单元的前馈神经网络,每个单元代表一个词型,把这个神经网络暴露在大量的中文或英文文本中,它同时学习预测后面的五个词以及回溯前面的五个词。范式上彼此相关的单词一般出现在相似的上下文中,导致网络中相似的权重更新。因此,连接权重来表示单词,这样它们就捕获了被表示单词之间的聚合关系。也就是说经过训练后,一个单词由该单词输入单元发出的连接的n维权重向量表示,具有相似语法或语义属性的单词将具有类似的向量。在训练语料库中出现次数少于5次的单词被排除在外,以减少处理时间和内存需求,并且因为不常见单词的分布信息不太可靠。对于每种语言,通过运行Skipgram模型12次获得12个不同的向量集(即模拟12个参与者),隐层大小N从平均值300和标准差25的正态分布中随机抽取,然后四入到最接近的整数。
② 训练语料 ¶
为了得到英语单词的表示形式,该模型在ENCOW14网络语料库上进行训练;中文,模型使用中文维基百科全文语料库进行训练,使用Wikipedia Extractor(版本2.66)从下载的Wikipedia XML中提取经过清理的文本。中文的标准书写没有明确的词边界,但这是分布式语义模型所要求的。因此,使用 Jieba(0.38版本)将中文语料库被分割成单词,之后,把语料库转换为拼音,生成的语料库包含近89.8万篇文章,共有2.108亿个拼音词标记,200万种类型。
③ 代表不完整的词 ¶
汉语材料包括多音节词,其皮层诱导在音节率上至关重要,在模型中捕捉这一点需要每个音节位置的向量表示,但是分布式语义模型只生成表示完整单词的向量。音节级表示的构建时基于口语单词识别的队列模型:即音节序列S1,…,Sn(可能只包含一个音节)激活所有以该序列开头的单词,这串音节激活的序列叫做队列,这个词必须在维基百科语料库中出现至少5次,才被认为是队列的一部分。在音节位置n处的向量,表示序列S1,…,Sn,等于队列中单词的平均向量,也就是说,在每个词的词尾音节的表示等于该词的单个向量。当s1,…,sn不构成任何单词的开头时,队列变为空的,这时音节Sn开始一个新的队列。这种方法应用于句子序列和打乱的音节序列,因为它不依赖于单词边界的知识。
2.3 随时间变化的词汇信息 ¶
模型中汉语和英语都使用了4Hz的频率,使V=(v1,…,vn)表示当前呈现的英文单词或中文音节序列的n维列向量,研究假设词汇信息不是在单词开始时(t = 0 ms)立即出现,而是在一段时间后出现,t的值在每个单词/音节表示时从平均μ = 40和宽度β = 50的均匀分布中随机采样。单词开始后t ms(0 ≤t ≤250)的可用词汇信息由列向量表示W(t)=(W1(t),…,Wn(t))。其中εi(t)为高斯噪声,均值为0,标准差σ = 0.5。因此,词汇信息向量w(t)开始只表示噪声,但在t ≥ τ时,v中的信息变为可用的。
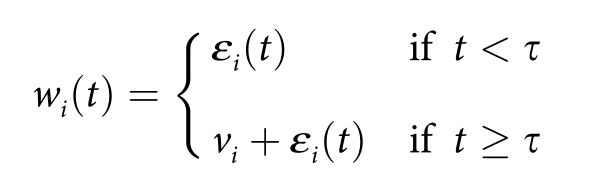
2.4 分析 ¶
按照丁鼐等人的方式,应用离散傅里叶变换来获得每个实验条件和每个模拟参与者的功率谱。矩阵W的单个行,每一行都代表字向量空间的一维时间过程,被转换到频域。接下来,对这些每维功率谱在N维上求平均,得到每个频率仓的功率。中文的频率仓宽度为1/9 Hz英文为1/11 Hz的英语,按照丁鼐等人的方法,使用带有错误发现率校正的单尾t检验来测试每个频率仓的功率是否显著超过前两个和后两个仓的平均值。通过Matlab在线计算、分析和绘制功率谱。
3. 结果 ¶
下图2展示了5种条件下的模型预测的功率谱与记录人类被试的MEG的结果,忽略尺度上的差异这两个结果相似度很高。其中模型对于英语4词句子(NP+VP)预测了单词(4Hz)、短语(2Hz)和句子(1Hz )呈现频率下的峰值。汉语四音节句子也和英语四词句子的结果很像,并且与丁鼐等人的实验结果类似。英语和汉语的4音节句子的模型预测结果与实际人类测得结果中都呈现了小的3Hz的峰值,尽管只有英语四音节句子中的3Hz峰值达到了显著性。这个3Hz的峰值很可能反映了1Hz的2次谐波,所以它们不能反应输入的任何特性。2Hz和4Hz的峰值并不仅仅作为谐波出现,因为当只出现汉语[N V(P)]句中的动词和动词短语时,即使这种情况下功率谱缺少1Hz的峰值,仍然存在2Hz和4Hz的峰值。模型预测1-3条件的结果中2Hz峰值确实大大的减小了,实际MEG结果在2Hz峰值处也无达到显著性。
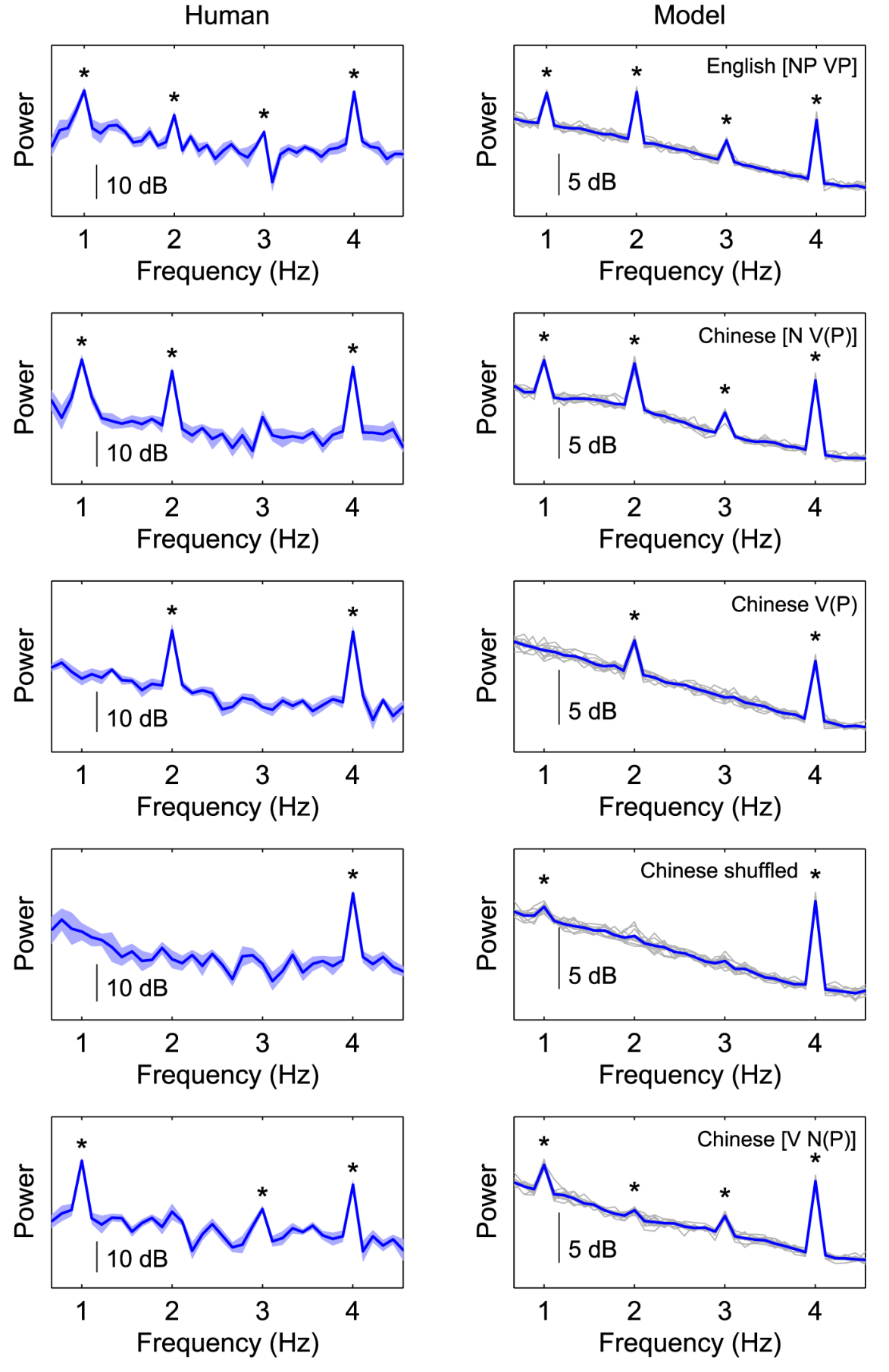
4. 讨论 ¶
与丁鼐等人的MEG结果类似,只有在随机打乱音节条件下,模型预测结果中呈现了非常小但具有统计学意义的1Hz峰值但人类结果中没有发现。这种差异的可能解释是模型对句子和打乱的音节的处理完全相同,相反被试在听打乱的单词序列时可能会放弃主动激活的单词。重要的是,与[N V(P)]句子条件相比,预测的1Hz峰值大大降低了,这表明音节的打乱对模型预测的影响与MEG功率谱的方向相同。
4.1 语义与句法结构对丁鼐研究结果的解释 ¶
该模型唯一的语言表征形式是由分布语义向量构成的。尽管这些是从字串中学习的,但并没有显性的编码词序列信息(比如过渡概率),因此不能用来预测(例如一个名词后面很有可能跟一个动词)。
词向量通过向量之间的相似性反映词之间的聚合关系来表示词汇属性:即拥有更多共同的句法或词汇属性由更相似的向量编码。因此,如果某些词汇属性在刺激序列中以固定的频率出现,这将反映为模型的向量时间序列中重复出现的近似数值模式。因此,如果某些词汇属性在刺激序列中以固定的频率出现,这将反映为模型的向量时间序列中重复出现的近似数值模式。比如在丁鼐使用的英语四词句子中,每个句子中都包含一个及物动词指动作,以固定的频率出现,另外两个词都是名词,一般都指实体。因为语义和句法相似的词都由相似的向量表表示,与此实验条件相对应的向量序列显示,谱功率峰值正好出现在双词短语和四词句子的出现频率上。这并不依赖任何等级结构或过程。但是,一个词是名词还是动词(或者,就语义而言:指一个实体或动作)取决于它在句子中的作用。比如在刺激句“fat rat sensed fear”中单独看单词”fat“应该是一个名词而不是形容词,单词”fear“应该是动词而不是名词。向量不能区分这些词的不同含义,单词”fat“只有一种向量表示。尽管如此,刺激词的属性明显有足够的重复来解释脑磁图的结果。当每个单词用一个向量来表示时,研究得到的结果在质量上是相似的,这个向量只标识了它最频繁的句法类别,也就是说,独立于单词在句子中的作用。
该模型显示了如何可以在不依赖等级结构或综合过程的情况下解释丁鼐等人的皮层诱导结果,但是这并不排除等级结构对皮层诱导的存在,甚至不排除Ding等人的结果实际上反映了等级语法的处理。实际上最近已经证明,在英语材料的一个分层句子处理模型预测了类似的功率谱(Martin & Doumas,2017)。语音信号中的单词、短语或句子的属性能否解释皮层诱导,可能可以通过对英语刺激序列的“随机单词”序列进行测试来确定,该英语刺激序列是保持所有动词和形容词不变,但用来自不同语法类别的随机单词替换所有名词。因此如果1Hz的峰值依赖于四单词的句子,则在这种打破句子结构的条件下不可见。相反在词汇属性模型预测中依然可见1Hz的峰值,因为动词和形容词依然以固定的频率出现。
因此不一定要层级句法结构才能解释丁鼐等人皮层诱导的结果,只用词汇语义属性就足够了。与层级结构解释相比词汇属性解释具有简化的优势。这是因为构建一个句子的层次结构需要有关单词可能的句法类别的信息(例如,一个单词是否可以是名词、动词或形容词);或者从语义上讲:理解一个句子至少需要一些语义的知识。因此解释皮层诱导结果时,考虑词汇属性是必要的。
3.2 词向量作为皮层表征 ¶
向量表征并不表示皮层表征,相反,模型和大脑之间的关系是高阶的:向量序列中模式的节律性重复与MEG信号中因感知向量所代表的刺激而产生的模式相对应。