文献:Kalenkovich, E., Shestakova, A., & Kazanina, N. (2022). Frequency tagging of syntactic structure or lexical properties; a registered MEG study. Cortex, 146, 24-38. https://doi.org/10.1016/j.cortex.2021.09.012
论文原文 ¶
与格通常表示动词的间接宾语,比如I give him an apple,这句话里him就是与格,是间接对象,apple是动作的直接对象。属格,表示名词修饰另外一个名词,表从属关系。
1. 研究背景及本研究 ¶
丁鼐等人(2016)的研究表明听者会自发的追踪句法成分,但是Frank和Yang(2018)通过使用完全依赖词汇语义信息构建的分布式语义向量模型模拟出了与丁鼐实验相同的结果。为了区分对同一结果两种完全不同的解释,本研究通过操控俄语其中一个词的词缀设计了两种句法上完全不同但词汇上相似的两类句子,基于词汇语义向量和基于句法结构表征对两类句法的预测的反应是不一致的,从而分离词汇语义和句法结构对神经追踪的影响。
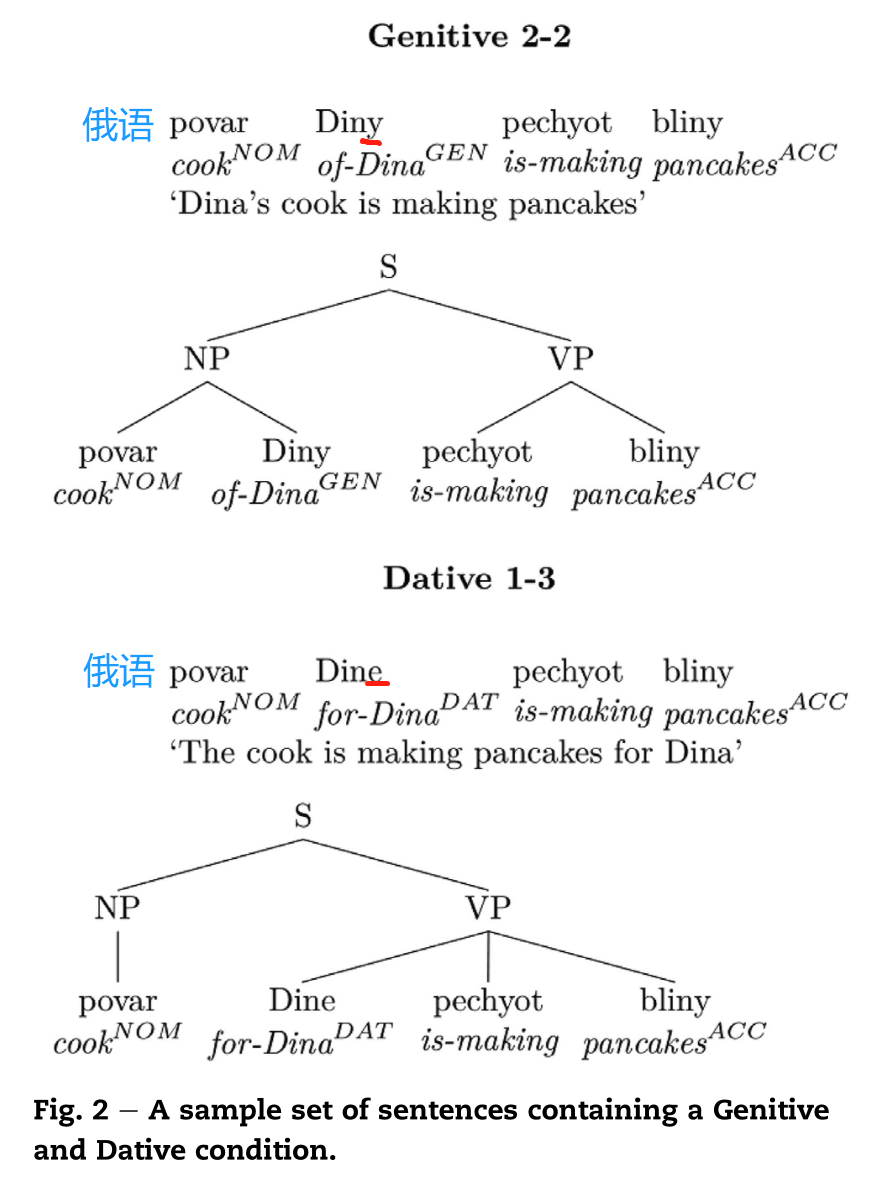
如下图1中俄语中最小区别的句子:“povar Diny pechot bliny”与“povar Dine pechot bliny”这两个句子只有其中一个单词的词缀(第二个单词的最后一个语素)不同。其中”Diny“表示“Dina的”(所属格),“Dine”表示“给Dina”(与格)。句子中第二个单词的格对整个句子的句法结构起着决定性影响,所属格条件下是“对称的”,因为它包含两个双词短语,比如NP“povar Diny”( Dina的厨师)和VP“pechot bliny”(正在做煎饼),因此下文把所属格称为“2-2”条件;把与格条件称为"1-3"条件,由一个词组成的NP和三个词1组成的VP。在所属格条件下,当被试一听到“Diny”立马就能与前面的词联系形成NP ([NP povar Diny]),在与格条件下,“Dine”不能与前面的povar连接形成NP,而是等待组成VP,即[NP povar] [VP Dine… ]。
2. 实验一:使用Frank和Yang (2018)的模型进行计算模拟 ¶
2.1 材料 ¶
总创建了64组如上图两种条件的句子,所有的句子都由四个双音节词组成,格式为Noun1(主格) + Noun2+Verb+Noun3(宾格),其中Noun2都是专有名词或普通名词(作为所属格或与格)。
2.2 模拟 ¶
严格遵循Frank和Yang (2018)的程序进行模拟,模拟了12名被试,每个被试都会把每种条件下的句子重新排列以组成一个60个句子长的序列,因此序列包含480个音节(60句子 * 4单词 * 2音节=480)。将每个480音节长的序列表示为分布式语义向量链,模仿在没有任何单词边界线索的情况下,以等时音节速率,在听觉上呈现相同音节序列的人脑所执行的单词分割过程。按照Frank和Yang (2018)的程序,480个音节长的序列(S1, S2,… ,S480) 的第一个音节会激活以S1音节为开头的一系列单词组群,接着呈现音节形成S1S2,激活的一系列组合会减少到以S1S2为开头的单词组群,一直重复改程序直到系列群组为空时。以英文candy melted( can-dy-mel-ted)为例,当呈现音节can时,会激活包括can, candy, candle, canton, candid, cantaloupe, candidate, candyfloss这一系列组群,一旦组合成can-dy,这一系列组群就会减少为candy ,candyfloss等这类词,当后面的音节继续呈现组成can-dy-mel串时会产生一个空的单词组群,然后分段划分过程就会从最后一个音节(mel)重新开始。
2.3 数据分析 ¶
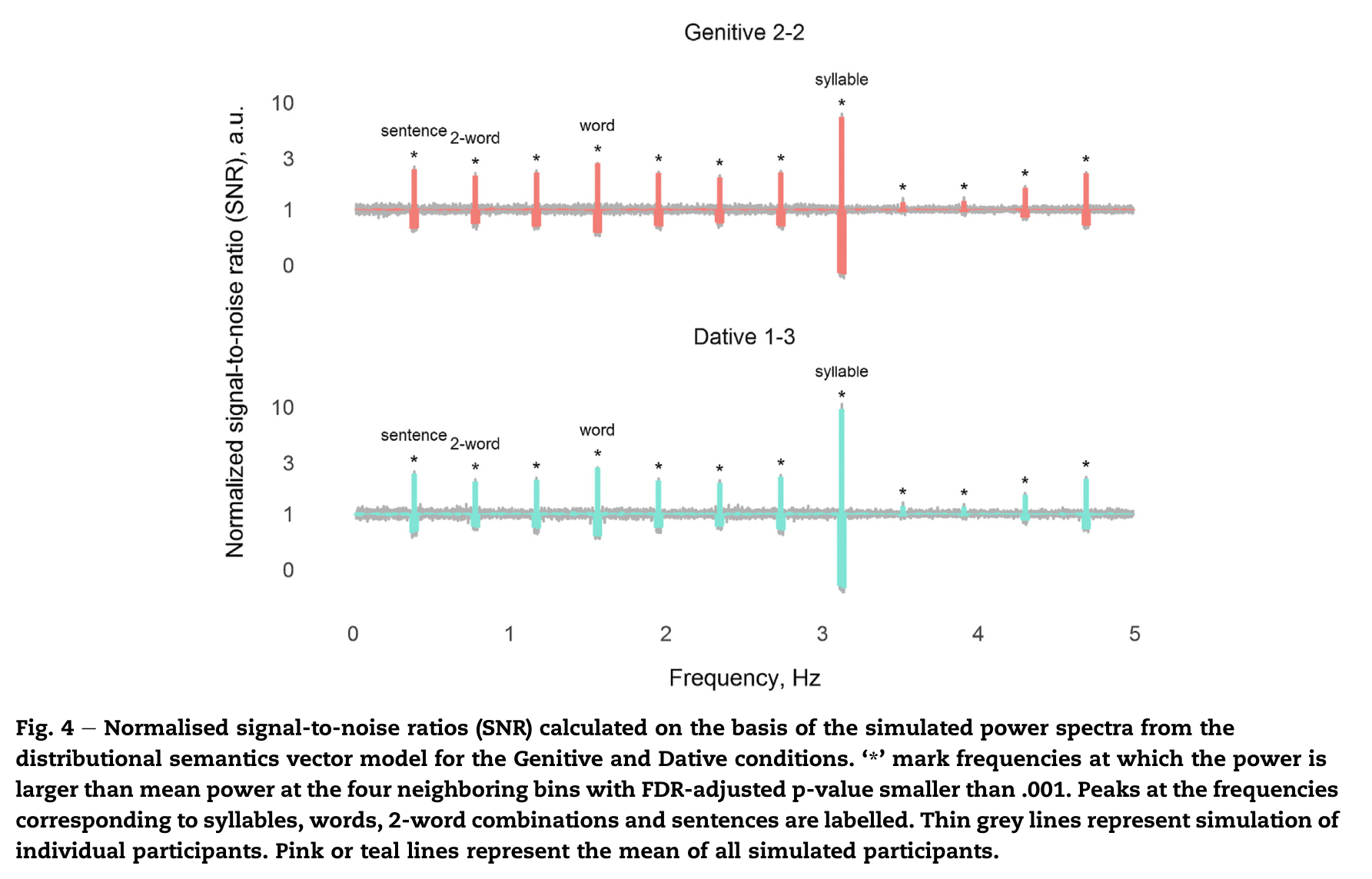
因为Noun2的所属格和与格形式对应的分布语义向量不同可能会影响峰值的幅度,所以研究根据单词频率的SNR对所有SNR进行了归一化,保持基线噪声SNR为1。下图2显示的是标准化信噪比后所属格2-2和与格1-3条件下的模拟功率谱,可以看到对应于音节、单词、二词和句子频率的峰值,所属格2-2条件下和与格1-3条件下的二词组合以及句子有类似的功率,但是从句法角度看所属格和与格在二词组合(0.78Hz)上会有差异。
3. 实验二:MEG实验 ¶
3.1 方法 ¶
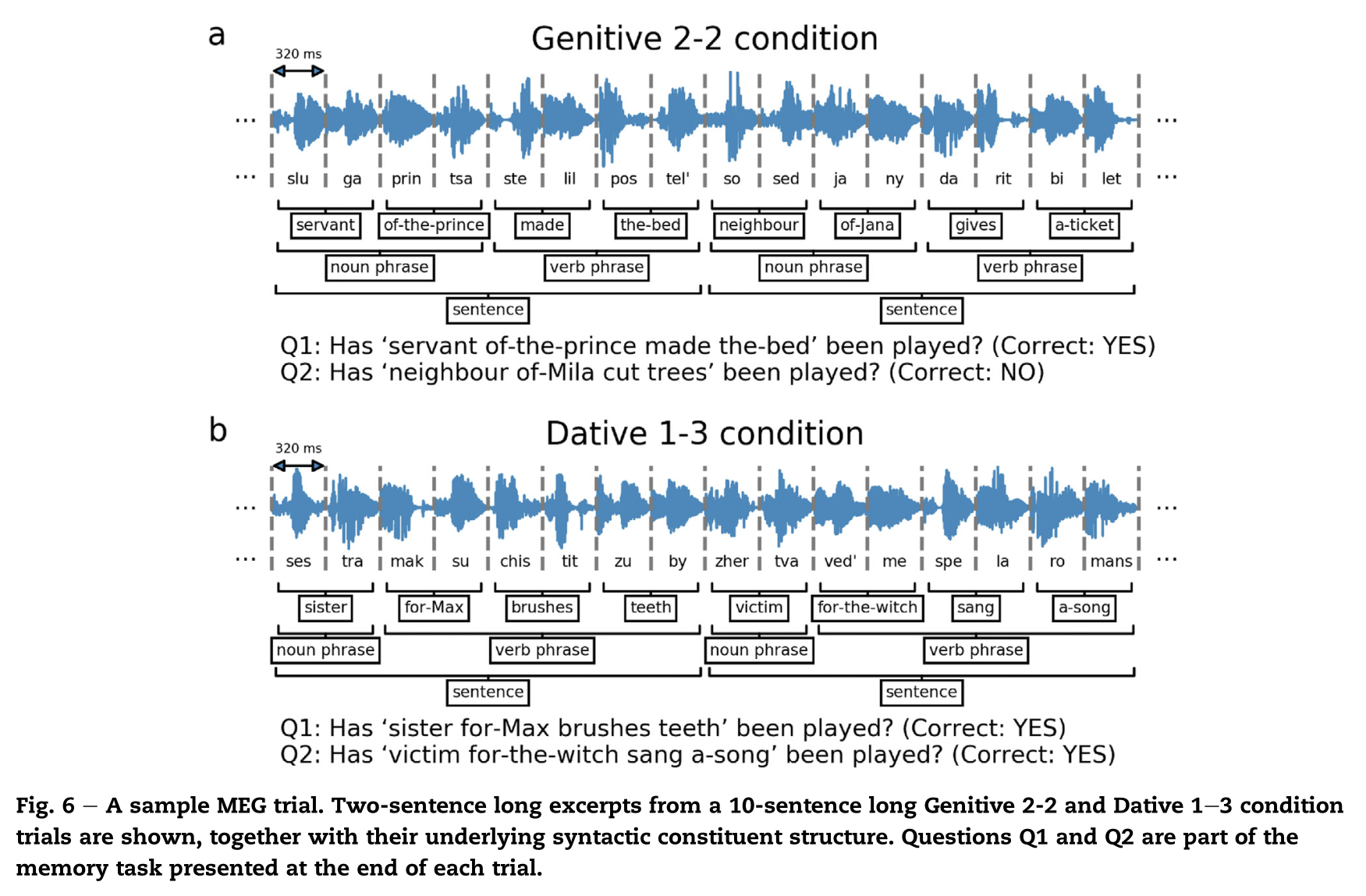
实验材料是实验一中用到的两种条件下的64组句子的语音,音节的持续时间控制为320ms,由11名无参加MEG实验的俄语母语者测试实验中用到的句子语音的质量以及能否被理解。对每一组句子都构建了三个测试问题,一个关键问题,两个控制问题。三个问题都用来测试句子的可理解性,关键问题用来测试对句子中关键名词(Noun2)的理解情况,筛选出了4组回答准确率低的句子,剩下60组刺激用作实验一和实验二中的刺激。

3.2 结果 ¶
a. 行为结果 ¶
31名数据中有4名被试的数据因正确答案小于56而被排除在外。
b. MEG数据 ¶
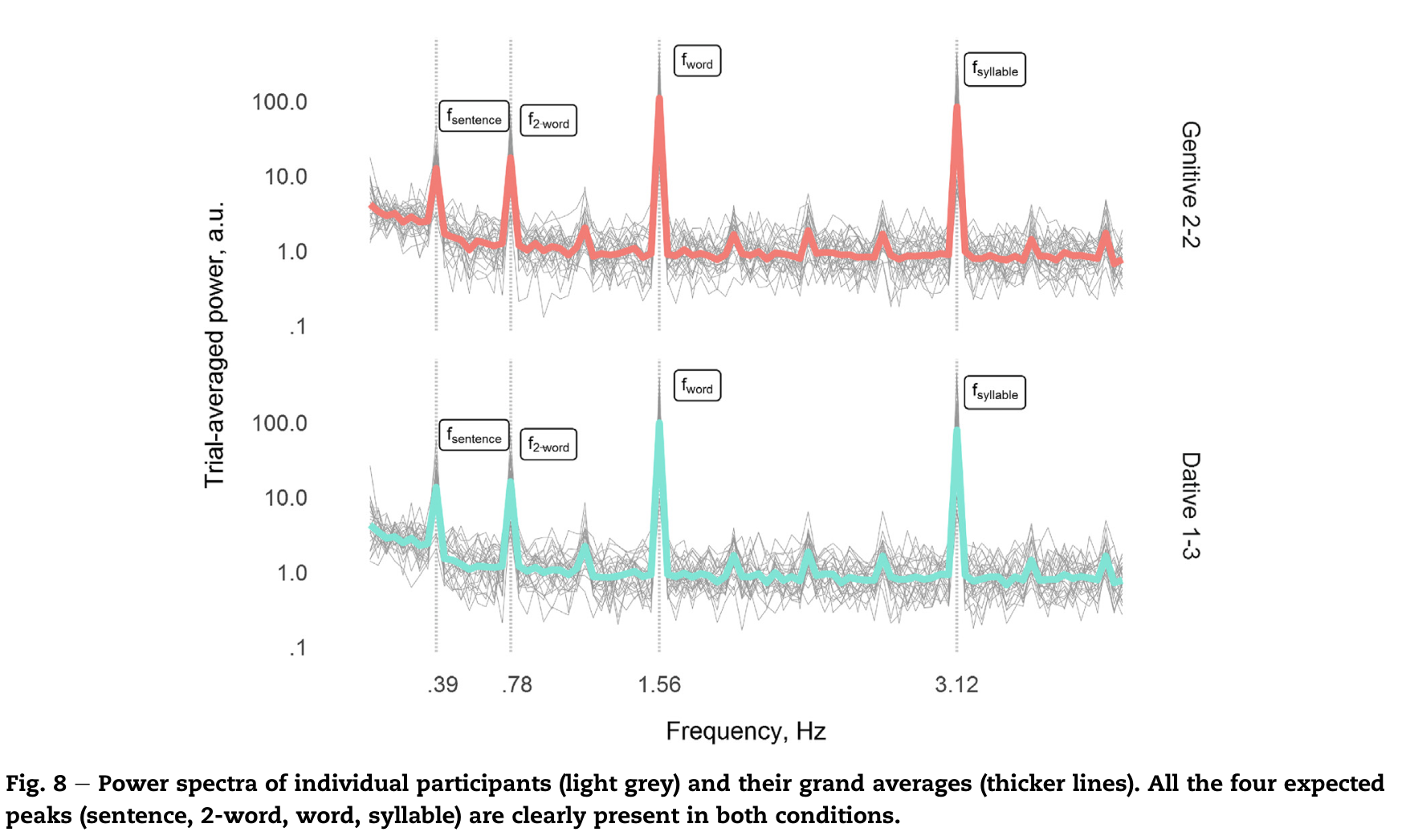
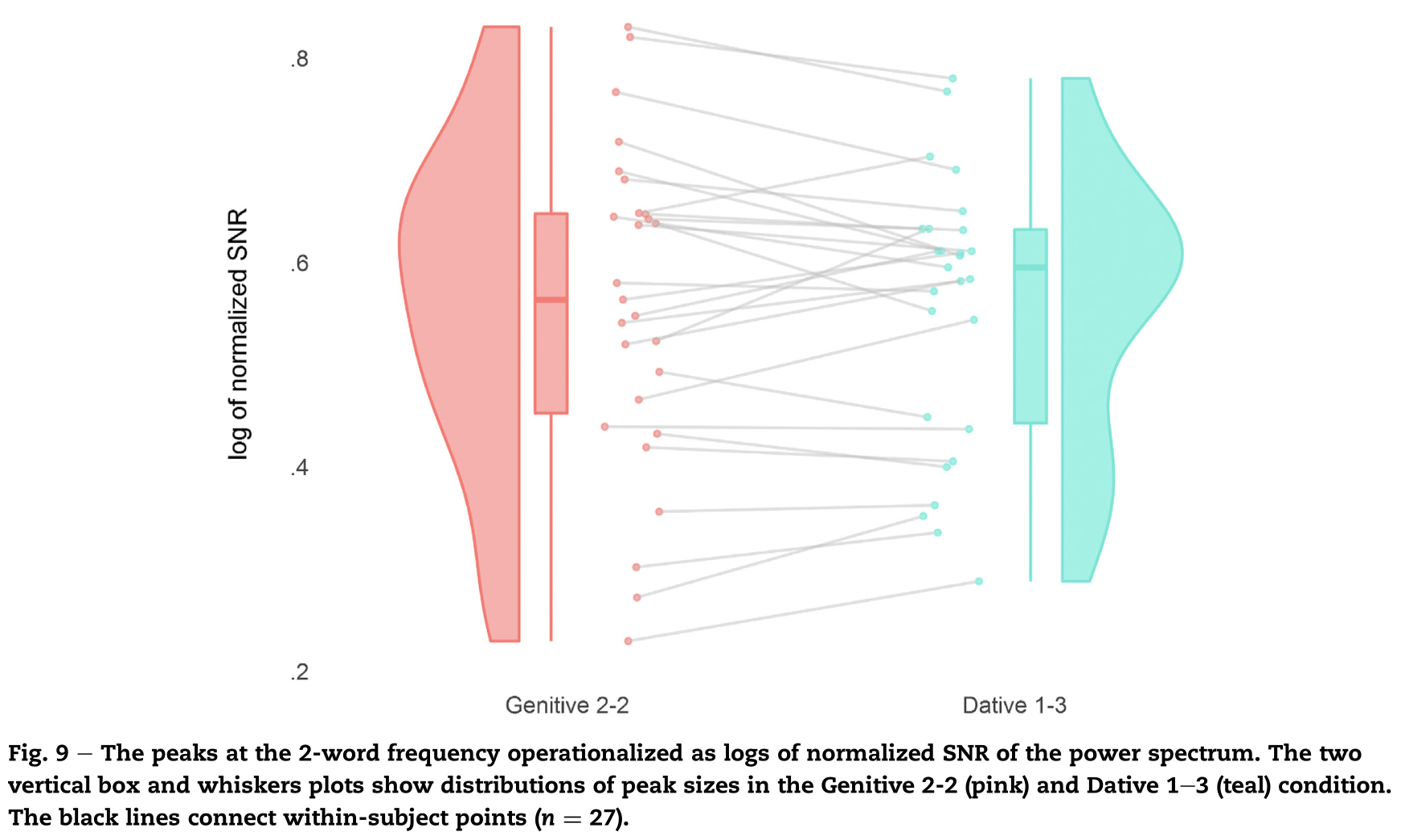
下图表示个体功率(灰线)以及总平均值,两种条件下都清晰地呈现了句子,二词组合,单词以及音节的峰谱。
4. 讨论 ¶
两种条件下都发现了对应句子,二词短语,单词以及音节频率的峰值,按照丁鼐等人2016年的解释来说,这些峰值反映了句子的句法结构,那么在本研究应该能够观察到所属格2-2条件下二词短语的峰值大于与格1-3条件下二词短语的峰值,但是结果显示这两种条件下的二词短语对应的峰值无差异。实际结果符合Frank和Yang (2018)提出的模型的预测结果,即所属格和与格条件下二词短语的峰值无差异。
Glushko、Poeppel和Steinhauer(2020)关注韵律在句子理解中的作用,并认为Ding等人(2016)的发现可能强烈反映了韵律因素。在本研究中与格1-3条件下是关键的控制条件,没有这条件就不知道2-2条件下对应二词组的峰值是否与短语有关。并且,可以认为最大的有意义的组块(2-2条件下的句子)不仅在相应的频率上产生峰值,而且在其谐波上也产生峰值。Ding et al.(2016)通过将2-2句法结构改为1-3句法结构,然后在二词组频率处没有观察到峰值,反驳了这一观点。Tavano等人(2021)采用以较慢的(句子)节奏的和声形式出现来区分短语级峰值:除2-2和1 -3结构之外他们还使用了2-3和3-2结构的句子,结果没有发现1-3和2-2条件下的二词峰值有差异。
因此,本研究结果与其他确证证据(Glushko et al., 2020; Tavano et al., 2021)不支持Ding等人(2016)句法结构的解释,这一研究和其他研究中使用的频率标记范式,并没有成功地分离句法结构,并受到其他,例如,韵律和词汇语义的影响。