文献Ding, N., Pan, X., Luo, C., Su, N., Zhang, W., & Zhang, J. (2018). Attention is required for knowledge-based sequential grouping: insights from the integration of syllables into words. Journal of Neuroscience, 38(5), 1178-1188. https://doi.org/10.1523/JNEUROSCI.2606-17.2017
论文原文 ¶
1. 研究背景 ¶
将序列分组为时间组块是大脑的基本功能 (Lashley, 1951;Gavornik and Bear, 2014),例如在语音理解中,语音序列的分组是分层级的,将音节组成词,词组成短语,短语组成句子等;同样在音乐感知中,音符按等级分为节拍和乐句,听觉顺序的分组是否需要注意力还存在争议 (Snyder et al., 2006; Shinn-Cunningham, 2008; Shinn-Cunningham et al., 2017)。一方面,假设序列分组需要自上而下的注意,特别是对于由多个听觉序列组成的复杂听觉场景。有证据表明,注意力很大程度上调节神经和行为对声音序列的反应(Carlyon et al., 2001; Fritz et al., 2007; Shamma et al., 2011; Lu et al., 2017)。另一方面,许多神经生理学研究表明,即使没有人注意到声音,大脑对声音的时间规律也很敏感(Naä¨ta¨nen et al., 2007; Sussman et al., 2007; Barascud et al., 2016),这表明对时间序列的原始分析可能是一个自动的过程(Fodor, 1983)。
序列分组不是一个单一的模块,这使序列分组如何受到注意力的影响更难讨论。序列分组机制包括自下而上的原始分组和自上而下的基于模式的分组 (Bregman, 1990)。自下而上的分组取决于感官特征之间的相似性(Micheyl et al., 2005; McDermott et al., 2011; Woods & McDermott, 2015),而自上而下基于模式的分组取决于先前的知识 (Hannemann et al., 2007; Jones and Freyman, 2012; Billig et al., 2013)。这两种分组机制在听力感知中具有重要作用。例如,在口语单词识别中,将声学特征整合到音位和音节依赖于音节内的声学连续性线索(Shinn-Cunningham et al., 2017),而将音节整合到单词中主要依赖于词汇知识,即哪些音节组合能构成有效的单词(Mattys et al., 2009; Cutler, 2012)。大多数先前的研究集中在注意如何调节基本顺序分组而很少有关于注意力如何影响基于模式的分组的研究。本研究用四个实验通过研究基于语言学知识把音节组合为词的神经加工过程填补了注意力对基于模式分组影响的研究。
2. 实验材料与方法 ¶
2.1 被试 ¶
共52名被试,平均年龄23岁,48%女性,每个实验包括14名被试,没有被试参与本研究两次以上的实验,都来自浙江大学,自我报告无听力损失与神经疾病。
2.2 词汇材料 ¶
研究使用了160个有生命名词和160个无生命名词,都是汉语双音节名词。有生命名词包括动物(40个),植物(40个),职业(48个,例如医生)和历史上的知名人物(32个,例如李白)。无生命名词包括无生命的物品(80个,例如茶杯,铅笔)和地点(80个,例如北京,浙江)。
2.3 刺激 ¶
a 等时音节序列 ¶
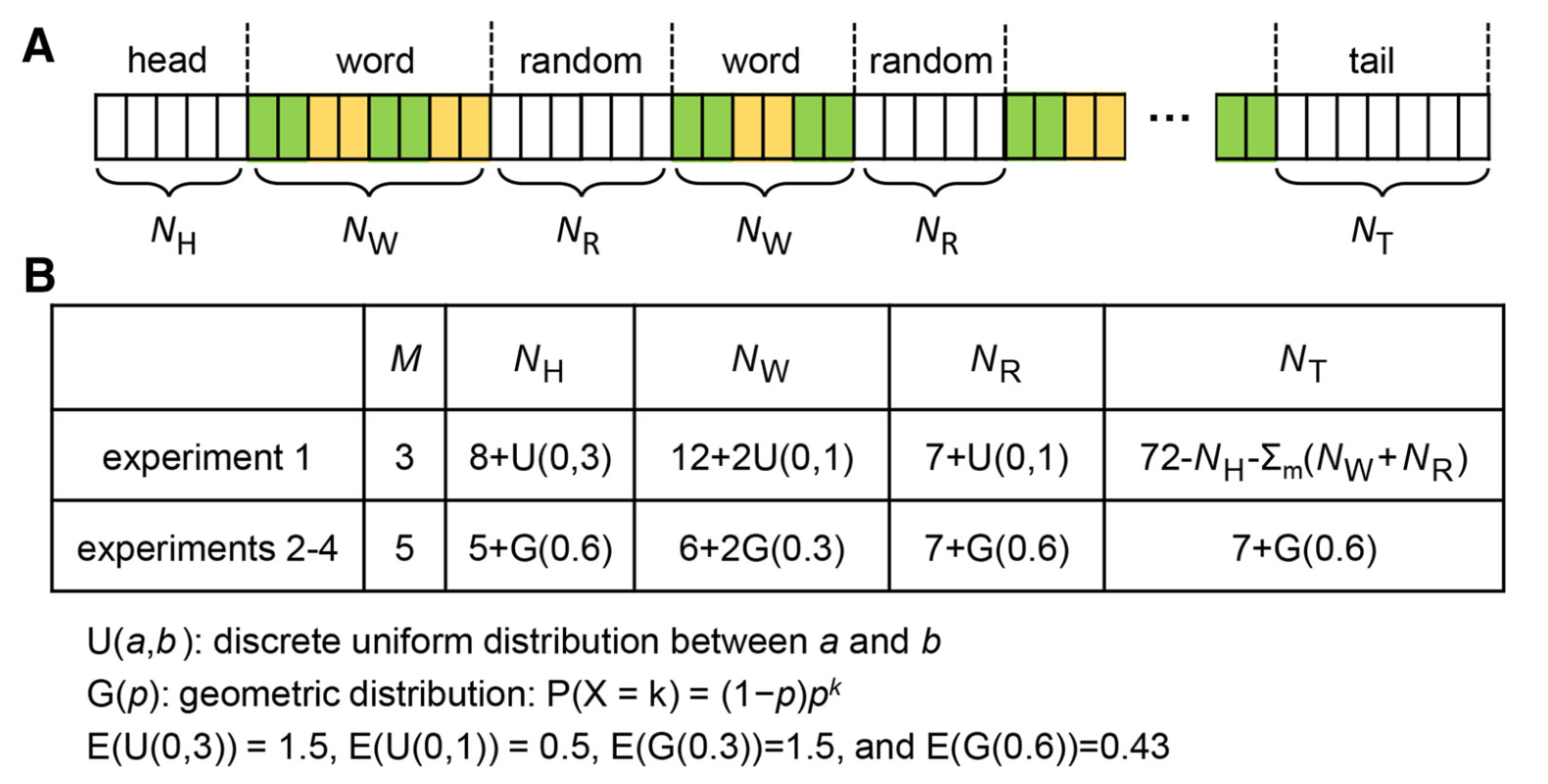
如下图1A所示,主要的刺激是等时音节序列,每个词呈现时间为250ms,音节序列由词state和随机state交替组成(如下图2A所示),每个state的音节数和每个刺激的词state数(即M)如图2B所示。每个序列的开始和结尾都有一段随机state,防止在音节序列还没呈现就注意了每个刺激的开始,1个trail中不会有重复的词,每个音节不会连续重复,不告诉被试1个trail中会有多少个词态。
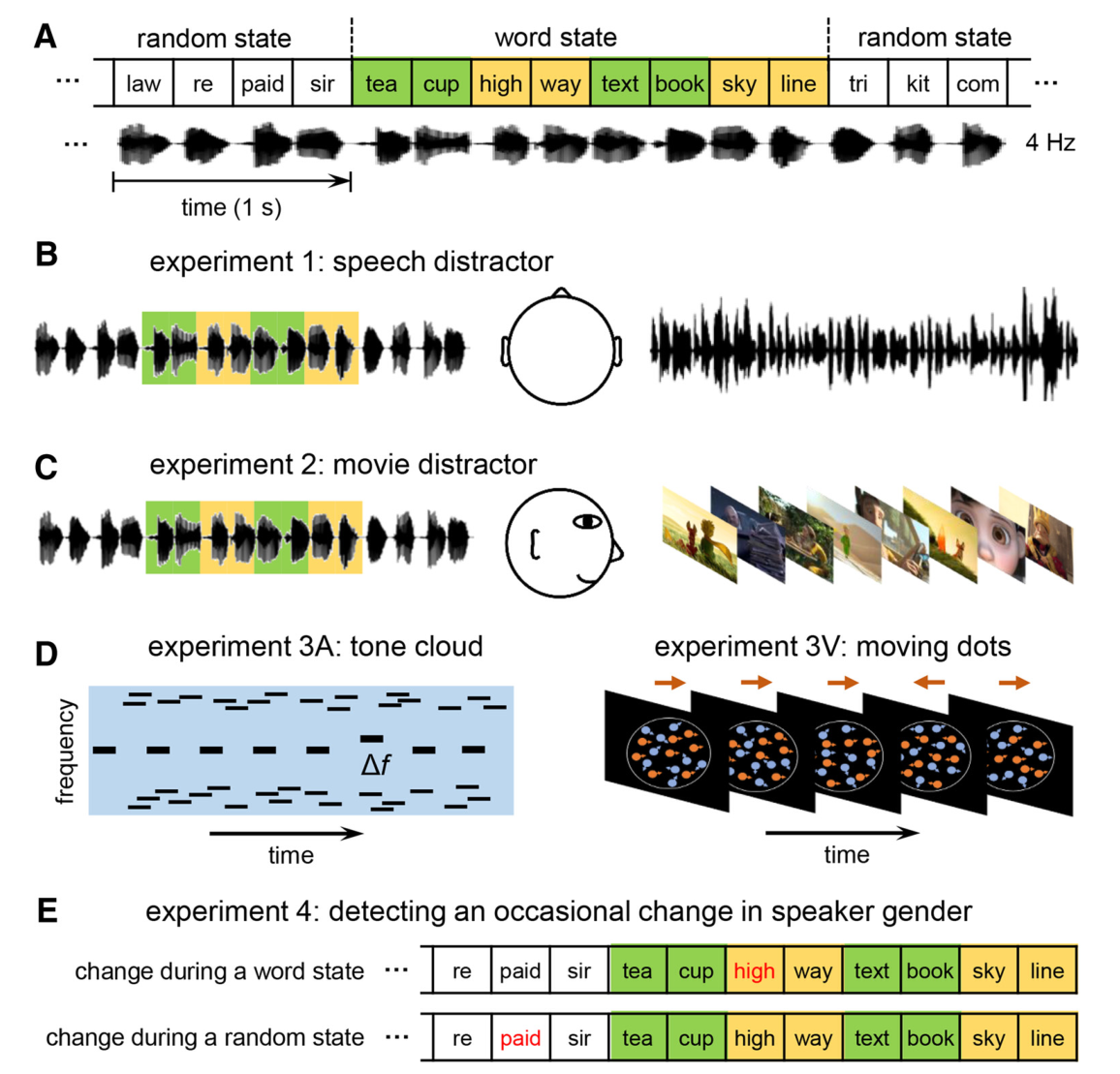
b 实验1中的口语干扰 ¶
实验1在呈现音节序列的同时呈现一个干扰的口语段落,如图1B所示,关于哪个耳朵呈现每个刺激在不同的被试之间有一个平衡,干扰的口语段落普通话水平测试大纲,干扰的口语段落在音节序列呈现的前1s开始呈现,因此被试更不可能把注意力放在音节序列上。
c 实验3中的听觉和视觉干扰 ¶
如图1C所示,实验3分为听觉干扰和视觉干扰两种情况,听觉干扰由3 Hz的声调序列嵌入一个声调云中组成,每个声调持续75ms,3 Hz的声调序列具有固定的频率fT,其在对数频率标度中均匀分布在512和1024 Hz之间,声调云由每秒50个声调组成,声调云和3 Hz声调序列在频率上不重叠。在刺激中,声调云在3 Hz声调序列开始后0.5 s开始,会使被试在没有任何声学干扰的情况下听到3 Hz声调序列中的前两个声调。
2.4 实验流程 ¶
此研究包括4个实验,实验1至3根据被试的注意点分为2个block。
a 实验1 ¶
第一个block中被试注意力在口语段落上,并在每个trail后回答了理解问题,当实验人员记录好答案之后按键继续下一个实验,按键之后的1~2s呈现下一个trail。第二个block中被试必须专注于音节序列,并判断在序列结束后1 s是否出现了额外的词,并通过按键反应来表示是否出现了词,按键之后的1~2s内继续下一个trail。相同的50个trail以随机的顺序呈现在两个block中,在呈现刺激时,被试要闭上眼睛,每25个trail休息一次,为了防止被试之后随机序列中包含单词后注意力会不自觉地转移到随机序列中,因此每个被试都是先进行注意口语段落的block。
b 实验2 ¶
实验2分为听单词和看电影2个block,2个block的呈现顺序在不同的被试之间有一个平衡。在1听单词block中,每一个trail之后被试需要通过按键反应来表示他们听到的具有生命的词语多还是非生命名词多,共有60个trail,每15个trail休息一次。在看电影的block中,被试会看一段无声的带有中文字幕的小王子电影片段。当电影呈现后3min再呈现音节序列,60个音节序列以随机的顺序呈现,当60个所有的音节呈现完毕之后结束电影。被试在这两个block中都睁着眼睛。
c 实验3 ¶
包括一个听觉干扰block和一个视觉干扰的block,两个block的顺序在不同的被试之间有一个平衡。在实验开始前告诉被试忽视即将听到一个与任务无关的语音信号,两个block中等时呈现的音节序列与实验2中的相同,在听力干扰的block中,听觉干扰和等时呈现的音节序列分别在两个耳朵呈现,听觉干扰的呈现比等时音节序列早2s,但与等时音节序列同时结束。要求被试监测偶然出现的嵌入在声调云中的3Hz的声调(如图1D所示)序列的偏差频率。在刺激的起始和结束的3s内都没有偏差刺激。两个偏差刺激呈现的间隔大于等于1s,60个trail中有30个trail包含一个偏差刺激,30个trail包含2个偏差刺激。
在视觉干扰block中,视觉干扰在等时音节序列呈现前的1s开始,在音节序列结束后的1s结束。被试要检测视觉呈现中连续运动反向的偶然逆转(如图1E所示)。运动方向的逆转持续350ms,两次逆转之间的时间大于等于2s。
d 实验4 ¶
实验4用到的刺激与实验2和3一样,另加了10个trail,这10个trail中的随机选择的音节序列的声音性别改变了。被试需要监测刺激中的性别改变。性别监测任务不需要进行词汇加工,如此设计的目的就是测试在没有明显任务要求的情况下是否会自动发生词汇监测任务。
3. 结果 ¶
实验1~3测试了当被试注意到一段口语、一部无声电影、一个没有语言内容的基本听觉/视觉刺激时神经构建多音节词是否有退化。这些干扰都转移了注意力,但它们的加工路径在不同程度上与等时音节序列的加工路径重叠。通过使用不同的干扰,可以梳理出由重叠加工路径引起的注意力和神经资源竞争的影响。实验4没有出现任何感官干扰,它测试了当听众注意基本听觉特征而不是词汇信息时,他们是否能够将音节组合成单词。
所有的实验都分析了由词state和随机state交替组成的等时音节序列(图1A)的稳态神经反应。在词state中相邻的两个音节能够组成一个双音节词,而随机state中的音节则以随机顺序排列。
第1个实验采用了双耳听的范式,被试的双耳分别同时呈现语音流(如图1B),其中一个是等时音节序列,另一个是被压缩的口语段落。共有2个block,其中1个block要求被试注意口语段落,并在1个trail结束之后回答相关的理解问题,平均正确率为84 ±2%;另1个block要求被试注意音节序列,并让被试指出在音节序列之后是否出现了一个额外的单词,正确率为77 ± 2%。
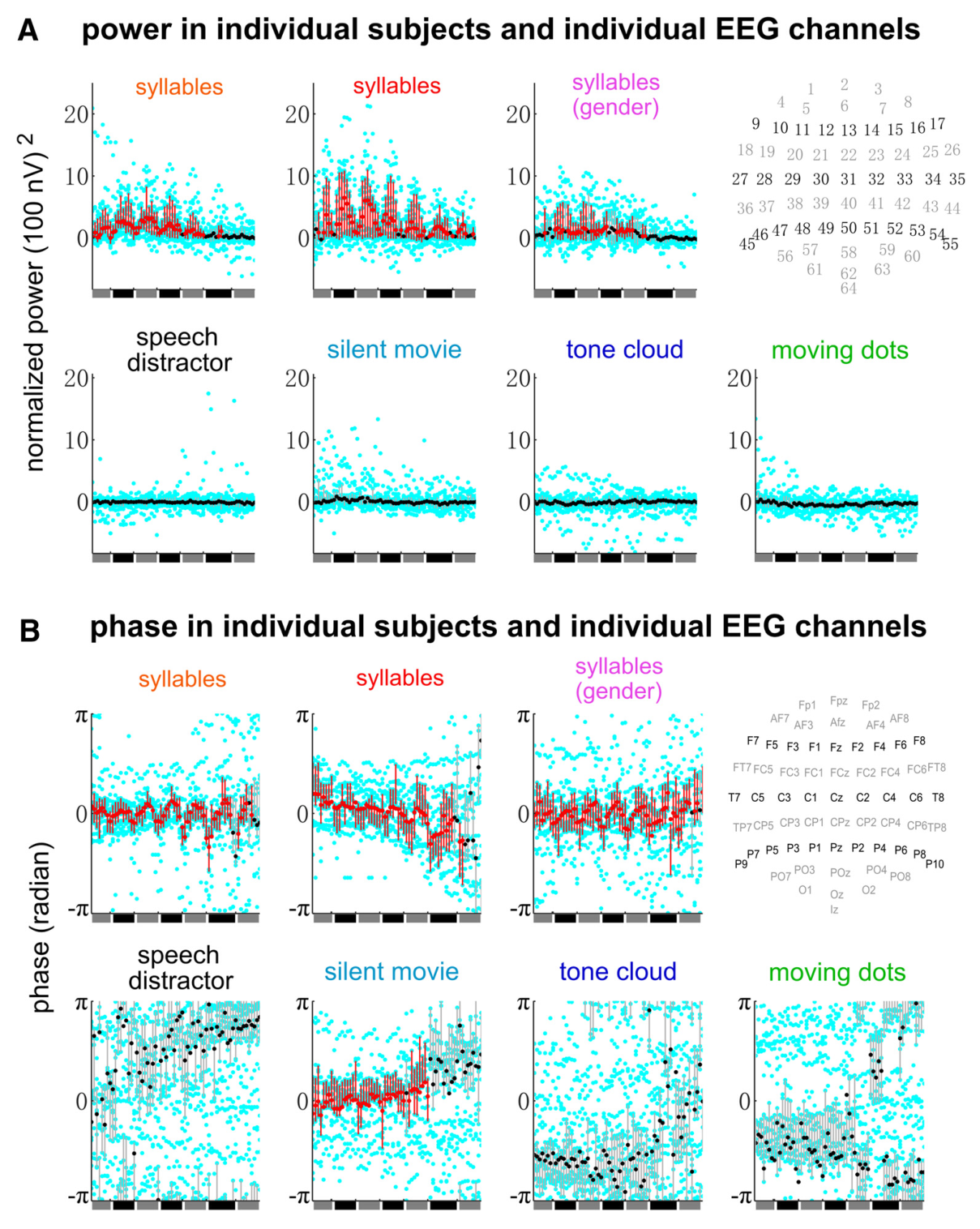
平均EEG反应谱如图3A所示,当注意力在等时音节序列上时,可以观察到音节速率和词速率的波峰,图3A反应地形图可以看到每个反应峰值具有较广的空间分布,并且集中在通道FCz附近。当注意力在口语段落上时,只能观察到音节速率的波峰,而词速率对应的神经反应不再明显强于相邻频率区间和音节频率的平均反应。但是,单词速率反应的幅度被调制了95%,而音节速率反应的幅度仅被调制了46%(图4.1)。这些结果表明,选择性注意对语言学上定义的时间组块(即单词)的神经表征的影响比对听觉事件(即音节)的神经表征的影响大得多。
在实验1中,对语音干扰的加工与对单词的加工高度重叠,因此不清楚是自上而下的注意力还是其他神经资源竞争导致对单词加工的影响。为了解决这个问题,实验2使用了一个交叉模式的干扰反转自上而下的注意,在实验2中给被试双耳呈现与实验1同样的音节序列,被试听语音或看带字幕的无声电影。当听语音的时候,在每个trail之后需要被试判断听到的生命名词多还是非生命名词多。实验2的EEG反应波谱如图3B所示,当注意力在等时音节序列上时,能观察到词速率对应的波峰。当被试看电影时,也能观察的明显的单词速率的波峰。与注意力相关的反应幅度变化在单词速率下为83%,但在音节速率下仅为11%。这些结果表明,即使没有任何竞争的听觉输入,单词水平的神经表征仍然受到注意力的强烈调节。虽然无声电影是被动听力实验中使用的经典干扰物,但它不会带来沉重的处理负荷,也不能保证被试始终专注于电影。此外电音字幕的加工可能与口语单词的加工部分重叠,在实验3中,让被试参与一项不需要任何语言处理的具有挑战性的视觉或听觉任务,并测试一项具有挑战性的感觉任务(模态内或跨模态)是否足以阻止音节组合成单词。
实验3中的听力任务为双耳范式,听力干扰物是以3 Hz重复的声调序列,要求被试监测声调序列中的频率偏差,并报告每个trail中偏差频率(N=0, 1, or 2),在视觉任务中,被试看到青色和橙色的点在屏幕上移动,随机选择的颜色的点显示部分连贯的运动,有时连贯的运动方向会暂时逆转,被试必须报告每个trail中这种逆转发生了多少次(N=0, 1, or 2)。被试听觉和视觉的正确率分别是81±10%和81±12%。
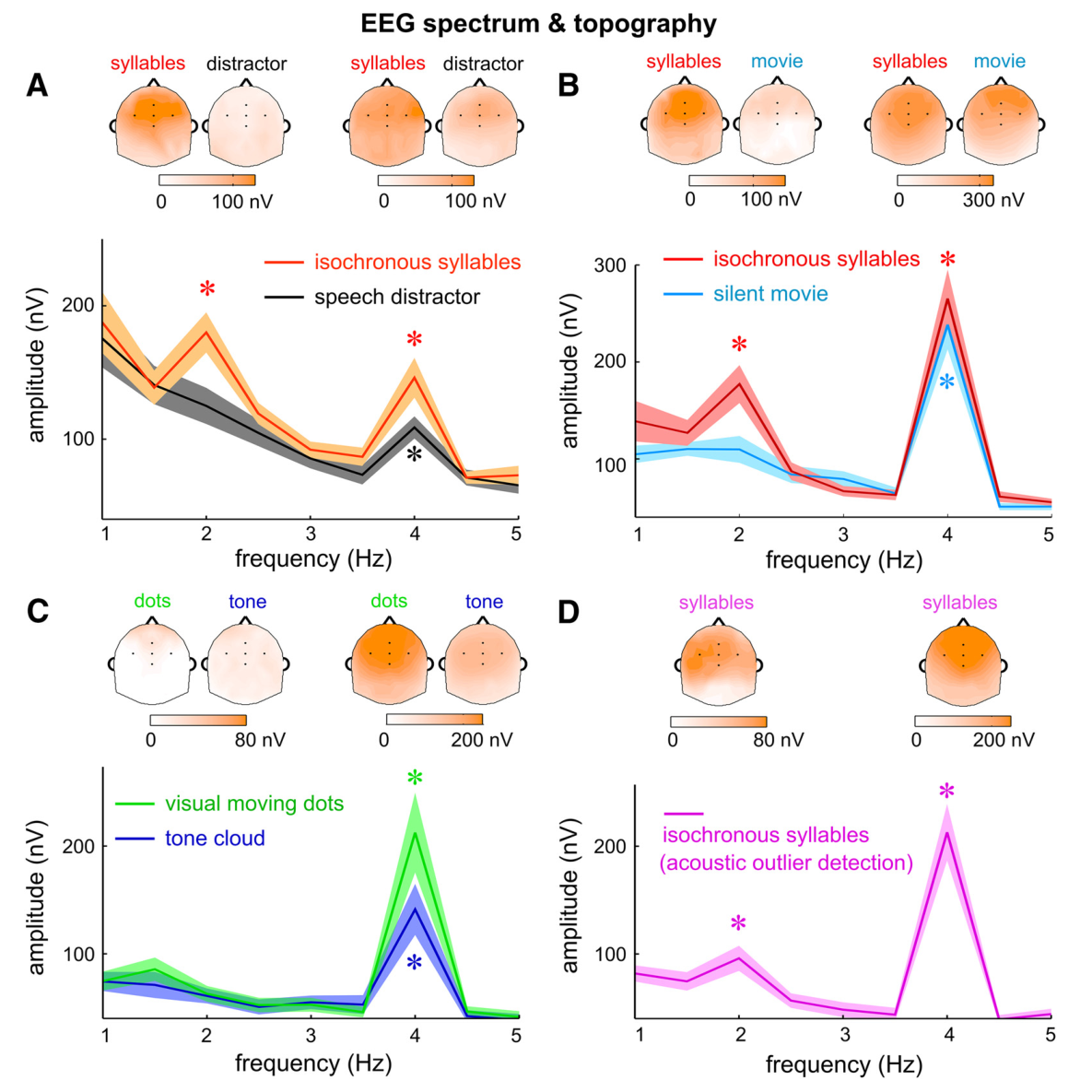
实验3的结果如图3C,两个任务都只有音节速率对应的波峰,并且听觉任务中的音节速率反应更弱,这可能是因为声调云的掩盖。这些结果表明,当被试从事不涉及语言处理的高要求的感觉任务时,会阻断基于知识的音节到单词的分组。
实验1和2表明,当被试注意等时音节序列并执行与单词相关的任务时,神经活动可以追踪单词节奏(实验一判断单词是否出现在序列中,实验二判断单词的生命性)。但是,还不清楚是对正确感觉输入的注意还是与单词相关的任务驱动了音节到单词的分组。实验4探究了这个问题,在此实验中被试在等时音节序列中执行了非语言的任务,监测呈现刺激的声音性别的变化,这个实验中被试的正确率为 92.5 ±1%。实验4的结果如图3D所示,可以观察到音节速率以及词速率对应的波峰,因此当被试执行低水平的非语言任务时,对应单词频率的神经反应仍然具有统计学意义。
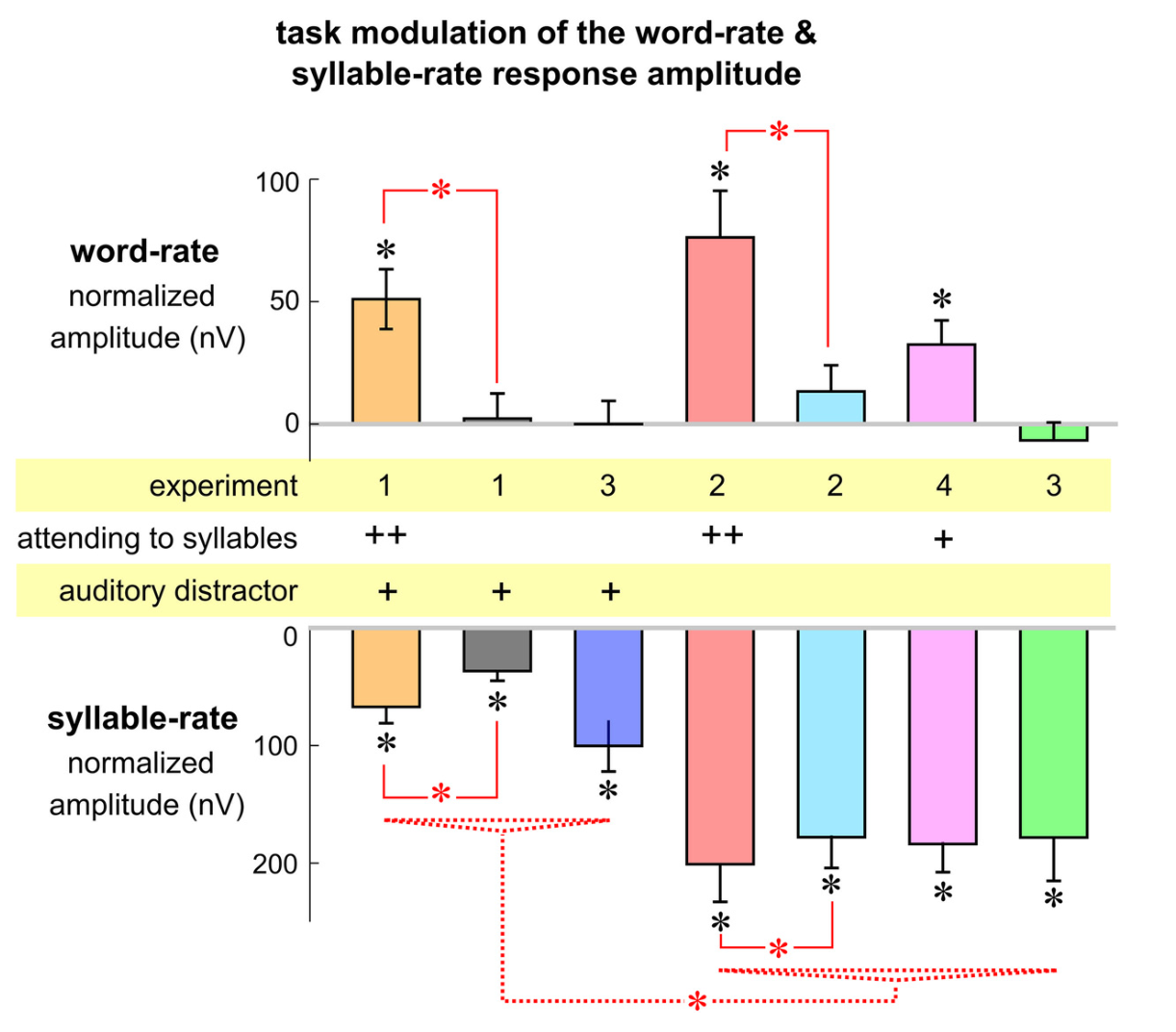
下图4是是实验1~4结果的总结,可以清楚的发现,音节速率的反应因听觉干扰的而减弱。这一结果与以前的发现一致,即对一只耳朵的听觉输入的反应被对侧耳朵的听觉输入减弱(Fujiki et al., 2002; Ding & Simon, 2012a)。并且在被试注意力不在等时音节上时实验4中词速率的反应比实验1~3中的条件都强,但是词速率反应的幅度小于实验2中在听语音条件下观察到的幅度,这可能是由于在实验2中的词汇水平的任务加强了对单词速率的神经追踪。
4. 讨论 ¶
此研究调查了注意力和任务如何不同地调节听觉事件(即音节)和时间组块(即单词)的神经追踪。在这项研究中,将音节分组为单词仅依赖于自上而下的词汇知识(即心理词典),而不是自下而上的声学线索。结果发现,将语音流中的音节分组为多音节单词需要注意语音(实验1-3),而不是词汇意义相关的任务(实验4)。