文献Chen, Y., Jin, P., & Ding, N. (2020). The influence of linguistic information on cortical tracking of words. Neuropsychologia, 148, 107640. https://doi.org/10.1016/j.neuropsychologia.2020.107640
论文原文 ¶
1. 研究背景 ¶
言语是一个由音节、音位、单词、短语、句子组成的等级体系。音节、音位是由语音特征定义的,而单词和短语、句子主要是由语言学知识定义。听者需要根据语言学知识把连续的语音流划分成具体的语言单位,而语言学知识是多维的。例如一个单词信息包括它是如何发音的、什么意思、如何与其他词组合、书写形式。在语言处理过程中,有人提出具有独立的神经表征来编码语音、句法、语义和拼写信息,这些信息通常共同激活,但可能具有不同的神经实现和行为结果。
最近的实验表明,不同时间尺度上的神经活动可以同时跟踪多层次的语音单位(Brennan & Hale, 2019; Ding et al., 2016; Keitel et al., 2018; Martin & Doumas, 2017; Meyer et al., 2016)。神经对词和短语及句子的追踪反映了神经不仅可以根据韵律信息编码,也可以根据语言学知识进行编码。并且,当被试听一种不知道的语言时,对高级语言单位的神经追踪就消失了 (Ding et al., 2016; Makov et al., 2017)。
但是,还不清楚对语言单位的神经追踪,即使是最基本的单词水平,具体反映了语言信息的哪些方面比如语音、句法或语义。一方面有假设说对单词的神经追踪反映的是语义/句法信息 (Broderick et al., 2018; Martin & Doumas, 2017)。这一假设认为编码不同语义/句法特征的神经网络可以在MEG或EEG记录的宏观神经活动中得到解析。另一方面,一些研究表明追踪单词的神经活动反映了语音特征,有证据表明大脑反应反映了在单词识别的语音信息整合(Brodbeck et al., 2018)。
2. 本研究 ¶
此研究试图通过一个人造词学习实验来研究单词的语音、语义和orthographic特征如何影响多音节单词的神经追踪。在实验一中,被试分为三组分别进行人造三音节词训练。第一组只学习人造词的语音,另外两组学习了与人造词对应的orthographic和语义信息。学习完之后被试被暴露在由人造词组成的连续的语流中,并记录他们的脑电活动。然后实验分析了,追踪人造词的脑电反应是否受语音语义和orthographic的调节。在语音收听期间的EEG反应不仅反映了训练效果,还反映了结构化流的统计学习和音频刺激的物理属性(Batterink & Paller, 2017; Buiatti et al., 2009; Saffran et al., 1996)。因此本研究又进行了实验二以控制混杂因素的影响。实验二中被试听到的人造词与实验一中一样,并且两种实验中都包含真词的情况,以与人造词的EEG进行对比。
3. 材料与方法 ¶
3.1 被试 ¶
浙江大学公开招募了46名被试,他们被随机分到实验组(n = 24; 20–28 岁, 平均年龄23 岁; 12 名男性)和控制组(n = 22; 20–31 岁, 平均23 岁; 11名男性)。控制组中有另外两名被试在实验过程中睡着了数据被剔除。实验组被试参加了实验1a1b1c和1d,控制组被试参加了实验2a和2b。所有的被试都是右利手,单语普通话母语者。
3.2 刺激 ¶
a. 人造词 ¶
共四组人造词,每组包含5个三音节人造词,这些人造词没有意义,由普通话音节组成但不涉及任何语义信息。具体方法为首先选5个三音节的真词(例如,无花果、皮夹克),然后把这个词的首,中,尾音节分别替换为σ1、σ2和σ3。共选了四组三音节真词,且都是名词,每个音节在每个单词中只出现一次。通过在相同位置(例如,所有单词的σ1)改组音节来构建一组人造词,合成的5个人造词具有与原始的5个真词相同的首/中/尾音节集。每个人造词或真词的语音都是通过连接使用Neospeech合成器独立合成的音节来创建的(http://www.neospeech.com/) 每个音节的持续时间调整为250 ms,并且在音节之间没有声学间隙。
b. 语音序列 ¶
实验中的真词和人造词是通过序列来呈现给被试的,实验一的四种情况下,一个序列的包含2400个音节(对应800个真词或人造词),每个音节以250ms即4Hz的频率呈现,相同的真词和人造词不会立即重复呈现。实验在语音序列的开头和结尾加了7到8个随机的音节,防止被试简单的从一开始把音节以三个为单位组成组块而不是通过记忆找到词的起始音节。开头和结尾随机的音节是从真词和人造词中音节中随机选出来的。实验一每种条件下的持续时间为10min零3.75s。每个语音序列中的十个音节被处理成不同的声音(共振峰偏移比= 1.5)。实验二中的真词与实验一中的真词一样,实验二中人造词是实验一的4倍长,包含9600个音节(对应3200个人造词),持续40min,3.75s。真词序列中的10个音节和人造词序列中的40个音节具有不同的声音(共振峰偏移比= 1.5)。
3.3 实验设计 ¶
被试在一个安静的房间进行测试,每个实验都在单独的时段进行,并且在整个实验过程中记录脑电图,在实验1中,4组人工词被随机分配到实验1a、1b、1c和1d,四个情况的顺序在不同的被试之间进行一个平衡。真词情况下的真词是由生成人造词的真词组成的。在实验2中,一组人造词被随机分配给控制条件(2a),真词条件包含用于生成这些人造词的真词(2b)。
a. 实验1a:语音 ¶
这个情况下,被试在训练阶段学习人造词的语音形式,如下图B所示,每次人造词呈现发音的同时在屏幕上显示其拼音,持续750ms,两个人造词之间有250ms的间隙,共5个人造词,每个重复60次,训练时间共计5min。要求被试记住人造单词的发音,并准备随后进行测试。具体为:进行一个双选择强迫选择(2AFC)测试来评估语音学习。在5次实验的每次,被试会听到他们学习的一个人造词(例如,shen luo tai)和一个由人造词的一个音节对加上一个附加音节组成的部分词箔(例如,luo tai wú),中间间隔500ms,要求被试通过按键反应来选择刚才听到的哪个词是学习过的词,按键反应之后继续进行下一个测试。
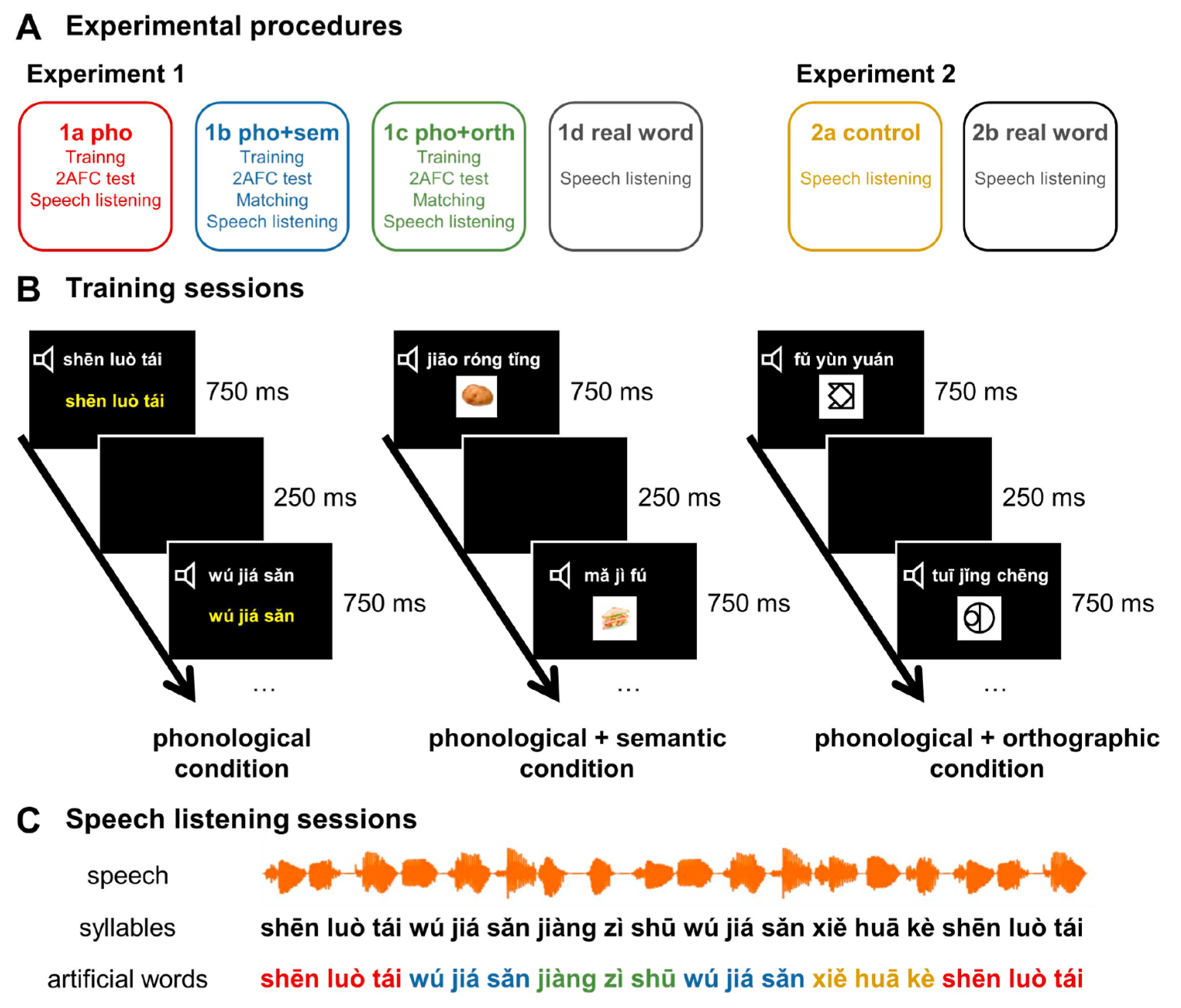
b. 实验1b:语音+语义 ¶
这个情况下被试在训练时每个人造词会搭配对应的图片例如,马铃薯、三明治,如上图B所示,每个人造词呈现的同时在屏幕上会显示对应的图片,持续时间70ms,在训练结束之后进行一个如实验1a的2AFC测试,之后他们需要进行另一个词与图连线搭配的测试。其他程序与上个相同。
c. 实验1c:语音+orthographic ¶
在此训练阶段每个人造词对应一个无意义的符号。
d. 实验1d:真词 ¶
被试直接听真词然后监测音调较高的音节并做出按键反应。
e. 实验2a:控制条件 ¶
实验2被试不进行任何训练,被试也不知道每个人造词为三音节的,实验之前告诉被试他们即将听40min没有听过的语音,在听的过程中需要监测比其他音调高的音节。在40min实验时候再进行2AFC测试来区分人造词和部分词箔。给被试的指导语为哪一个更像你刚才40min实验中听到的音。
f. 实验2b:真词条件 ¶
该条件与实验1d相同。
4. 结果 ¶
4.1 行为表现 ¶
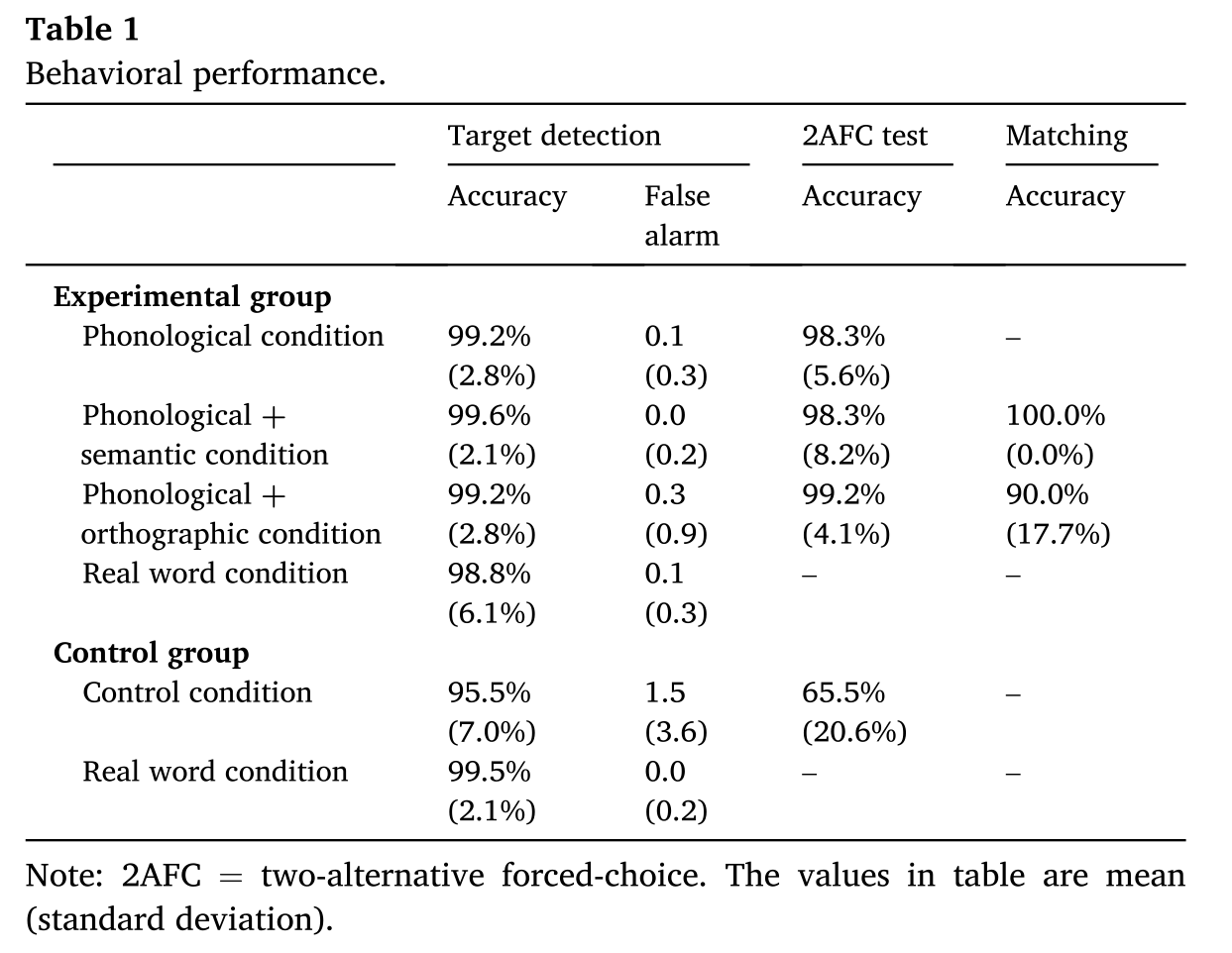
如下图2所示,2AFC测试和匹配连线测试在实验组中都处于上限;对照组2AFC测试的准确性显著高于 chance level,表示语音收听期间的统计学习过程;实验组的2AFC测试成绩显著高于对照组,这表明实验组的被试在训练后获得了更强的单词级表征。
4.2 训练对词汇皮层追踪的影响 ¶
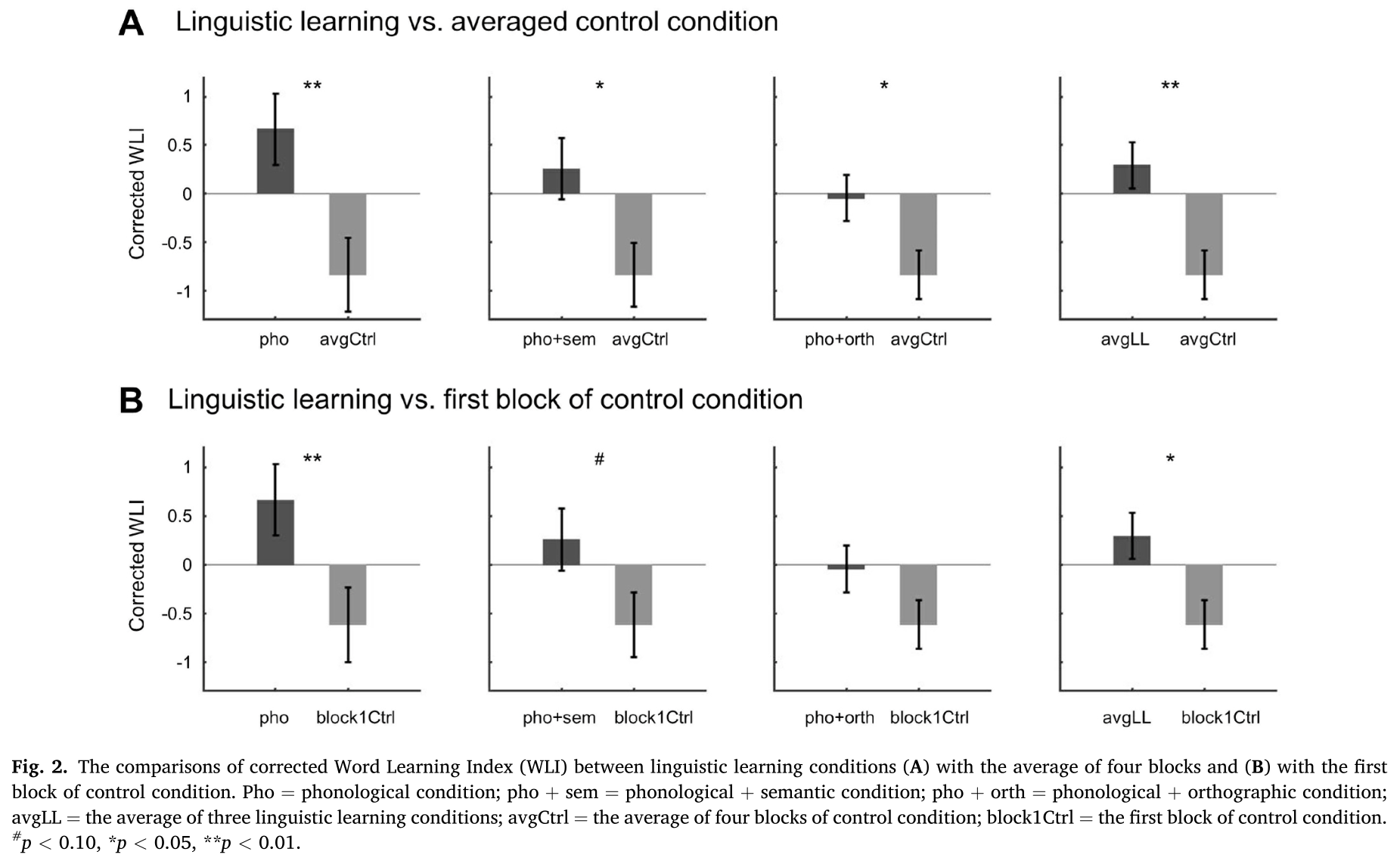
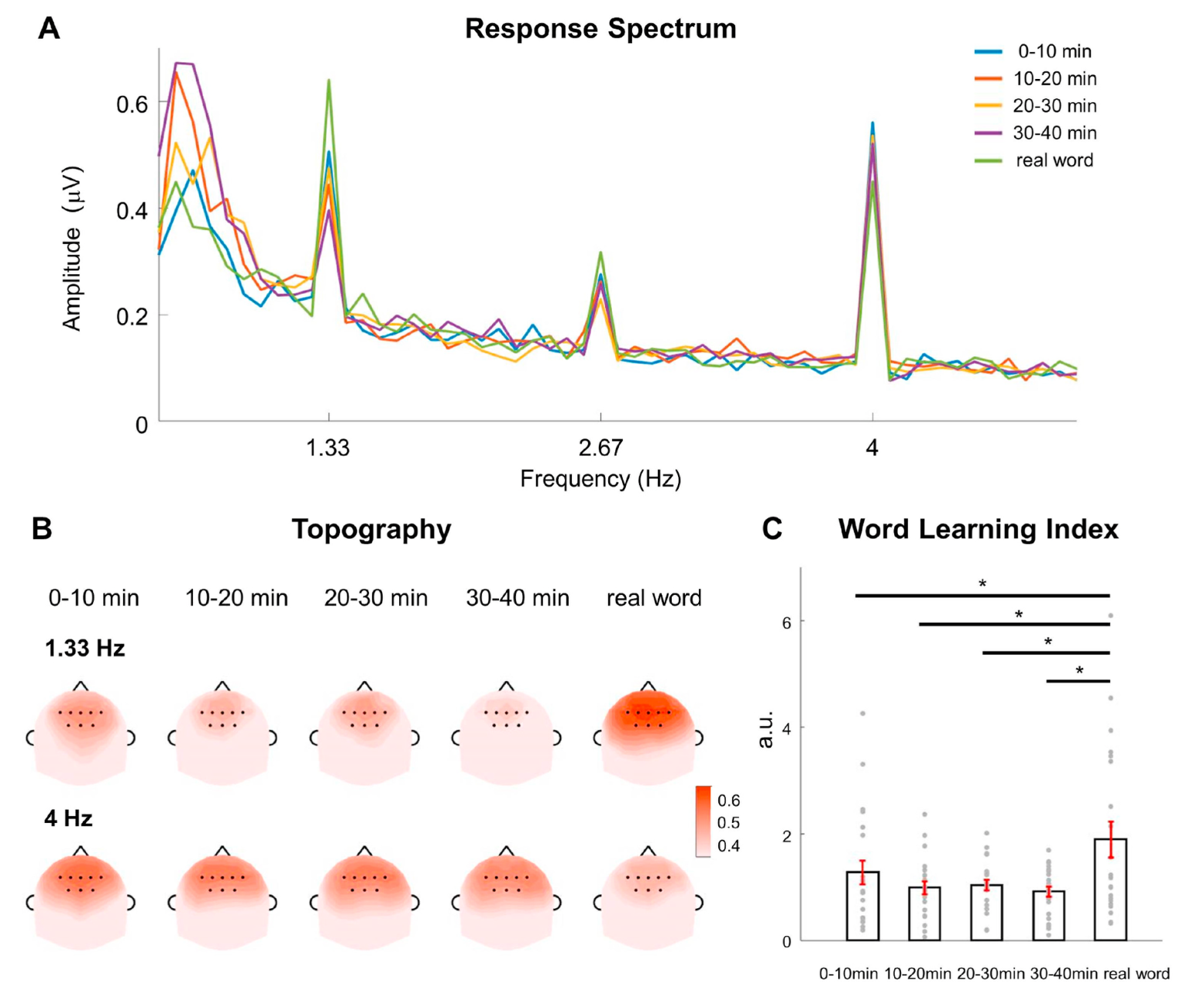
对于实验1和2,研究测试了1)每个语言学习条件,2)三个语言学习条件的平均值,与1)四个block的平均值和2)控制条件的第1个block之间的单词学习指数(WLI)的差异,WLI通过单词频率下的反应幅度除以音节频率下的反应幅度来计算。独立样本t检验显示,在语音条件、语音+语义条件、语音+orthographic条件下更高的WLI,而且它们WLI的平均值比控制条件下的四个block的平均值还要高(如下图A所示)。如下图B所示语音条件的WLI和三种语言学习条件的平均分显著高于控制条件下第一个block的WLI,并且在实验1中训练条件下比控制条件下仅仅通过统计学习的block的的WLI都有显著更高的趋势。
4.3 语言学习对词汇神经追踪的影响 ¶
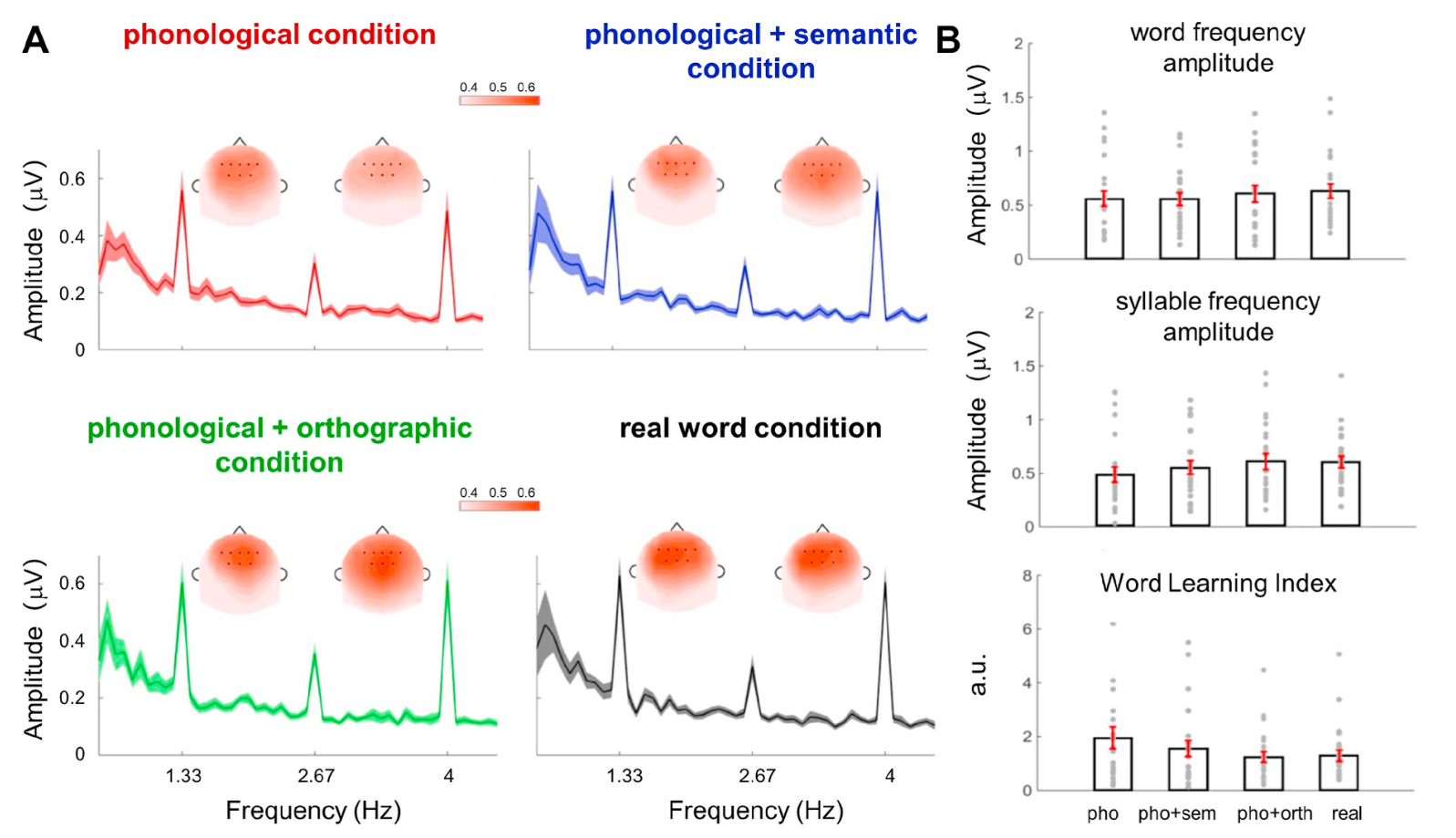
实验1为了探究语言学知识(语音,语义,orthographic特征)对三音节词神经追踪的影响,下图A展示了四个condition(语音,语音+语义,语音+ orthographic,真词)下的EEG反应谱。
4.4 控制条件下对单词的神经追踪 ¶
在实验2中,被试在没有学习训练的条件下听人造词的语音,神经追踪反映了统计学习和音频刺激的物理属性,下图A展示了4个10min控制条件下和真词条件下的EEG反应,所有的条件都展示明显的对应单词,音节以及单词第二谐波频率的峰值;控制组真词的WLI明显大于控制组其他4个block,并且这4个block的WLI无明显差异。
5. 讨论 ¶
这个研究主要探讨了学习以及语言学知识的不同方面如何影响大脑对单词层级的神经追踪,并发现了实验组对单词层级的神经追踪明显大于控制组,反映了将连续语音流分割成离散单元的训练的促进作用,并且发现在实验组中对学习过(无论学习的条件不同)的人造词的神经追踪的幅度与真词相当,这也反映了基本的语音信息在单词层级神经追踪的重要作用。本研究的实验条件下被试只进行了一个5min的训练学习,单词层级的神经反应依然比控制组更明显。表明了学习或者训练在序列分组中的重要性,并且之前的ERP研究也展示出了学习对语音分段的影响。
但是本研究中没有发现语义和orthographic信息对单词层级的神经追踪的影响。但是之前的研究有发现有影响(Broderick et al., 2020, 2018)。可能是由于本研究中所用的刺激是一系列不相关的词,任务是监测声音变化,很明显刺激和任务都没有充分调动对语义和orthographic信息的加工,但同时也没有调动对于语流的分割,因为监测音调高的音节也不需要对语流进行分割。因此,将语音分割成单词语音可能是一个比语义/拼写处理更自动发生的过程。并且之前的研究也表明了对词语义的加工是依赖于注意力和任务的。条件之间无明显差别的第二个原因是实验中缺乏更高级别的加工。第三个原因是训练时间太短。
在控制条件下前10min也显示出对词层级的神经追踪,约在5至7min达到峰值,这与之前快速统计学习的证据一致,这表明人类统计学习是非常快速的以及人类对环境中存在结构化时间模式学习的强大能力。
实验中还有需要改进的地方,第一,在实验1b中通过同时呈现对应的图片来给语音赋予语义,但是当图片引出语义表征时也会引出图片对应的单词;第二,在语音+ orthographic的条件下,只有充分的符号并没有包含充分的 orthographic信息。还需使用不知道的语言或者携带orthographic信息的人造词进一步研究。
总之,这篇研究强调了外显学习和语音信息对单词追踪的重要作用。