文献:Jin, P., Lu, Y., & Ding, N. (2020). Low-frequency neural activity reflects rule-based chunking during speech listening. Elif, 9, e55613. https://doi.org/10.7554/elife.55613
论文原文 ¶
1. 研究背景 ¶
最近的神经生理学结果表明,当听语音时,在多个时间尺度上观察到皮层活动,这些时间尺度与多层次语言单位的时间尺度相匹配,如句子、短语、单词和音节(Brodbeck et al., 2018; Broderick et al., 2018; Ding et al., 2017; Ding et al., 2018; Keitel et al.,2018; Makov et al., 2017)。即使短语和句子的边界没有韵律特征或词与词之间的过渡概率的提示,也可以观察到短语和句子的时间尺度上的皮层反应。在短语和句子的时间尺度上的神经反应被认为是大脑运用语法规则将单词分成组块的有力证据(Ding et al., 2017;Martin & Doumas, 2017)。
有人对这种基于规则的组块加工机制提出质疑,认为短语和句子的神经反应速率可能不是反映基于规则的多词块的神经加工过程,而是反映了对单个词的属性进行神经跟踪过程(Frank and Yang, 2018)。例如,在丁鼐等人2017年的文章中所用到的英文句子材料结构都为“形容词+名词+动词+名词”例如“new plans gave hope”。因此神经活动其实追踪了单词属性,例如语音信息或者区分物体和动作的语义信息。比如,因为每个句子都只有一个动词,因此神经活动对动词的追踪刚好对应句子频率,也就是说对每个词的单独的神经表征速率可能对应了所认为的句子表征。
并且之前的研究也表明对单词的神经反应取决于其语境,并且如果目标单词在语义上与先前的单词相关则反应幅度减小(Kutas and Federmeier, 2011; Lau et al., 2008)。也就是说,同一个句子中的单词比相邻句子中的单词更相关,因此在神经反应基于语境的前提下,其振幅预计在句子开始时会更强,从而导致表现为对句子的神经追踪。
词汇属性模型与语义相关度模型不认同组块层级的表征,对句子和短语神经反应速率提供了几种不同的解释。但是,组块模型允许基于不同的组块规则对同样的单词序列进行不同的分组,尤其在处理结构模糊的序列中最明显。例如, ‘sent her kids story books’ 可以分语块为‘sent [her kids] story books’ 或者 ‘sent her [kids story books]’ (Shultz and Pilon, 1973)。对于这种结构模糊的句子,当句子分为不同的组块时,基于规则的词块模型能够预测不同的短语追踪反应,而词汇属性模型或语义相关度模型不能。
2. 本研究 ¶
以上三种模型不是互相排斥的,单词语义属性的神经编码是分析词与词之间语义关系或构建多词块的前提。众所周知,大脑反应反映了单词属性和语义关系的编码,但大脑是否表征多词块仍有争议。因此,当前研究的目的是检验与多词块对应的时间尺度上的神经活动是否确实指示组块层级的神经表征或者可以由更简单的单词层级表征来解释。
因此本研究让被试基于两种不同的规则对词序列进行词块组合来区分基于语法规则的组块模型和基于单词层级的模型。所使用的词序列是由生物名词和非生物名词组合而成,如下图1A所示,该序列没有由语法规则定义的组块,但是被试明确学习了人工规则来对序列进行分组,并且两种情况下的规则不同。
当被试在在执行基于显性分词块任务时,用脑磁图(MEG)记录他们的大脑皮层活动。基于单词层级的模型也就是词汇属性模型与语义相关度模型,预测当被试听同样的单词序列而不管其执行哪种分词块任务时被试的大脑皮层都表现出同样的神经反应。而基于规则的语块模型预测神经反应基于词块规则。
3. 实验方法 ¶
3.1 被试 ¶
有16名被试参与研究(19-27岁;平均年龄22.6岁;八名女性),所有的被试都是右利手,自我报告无听力损失和神经生理疾病。
3.2 实验材料 ¶
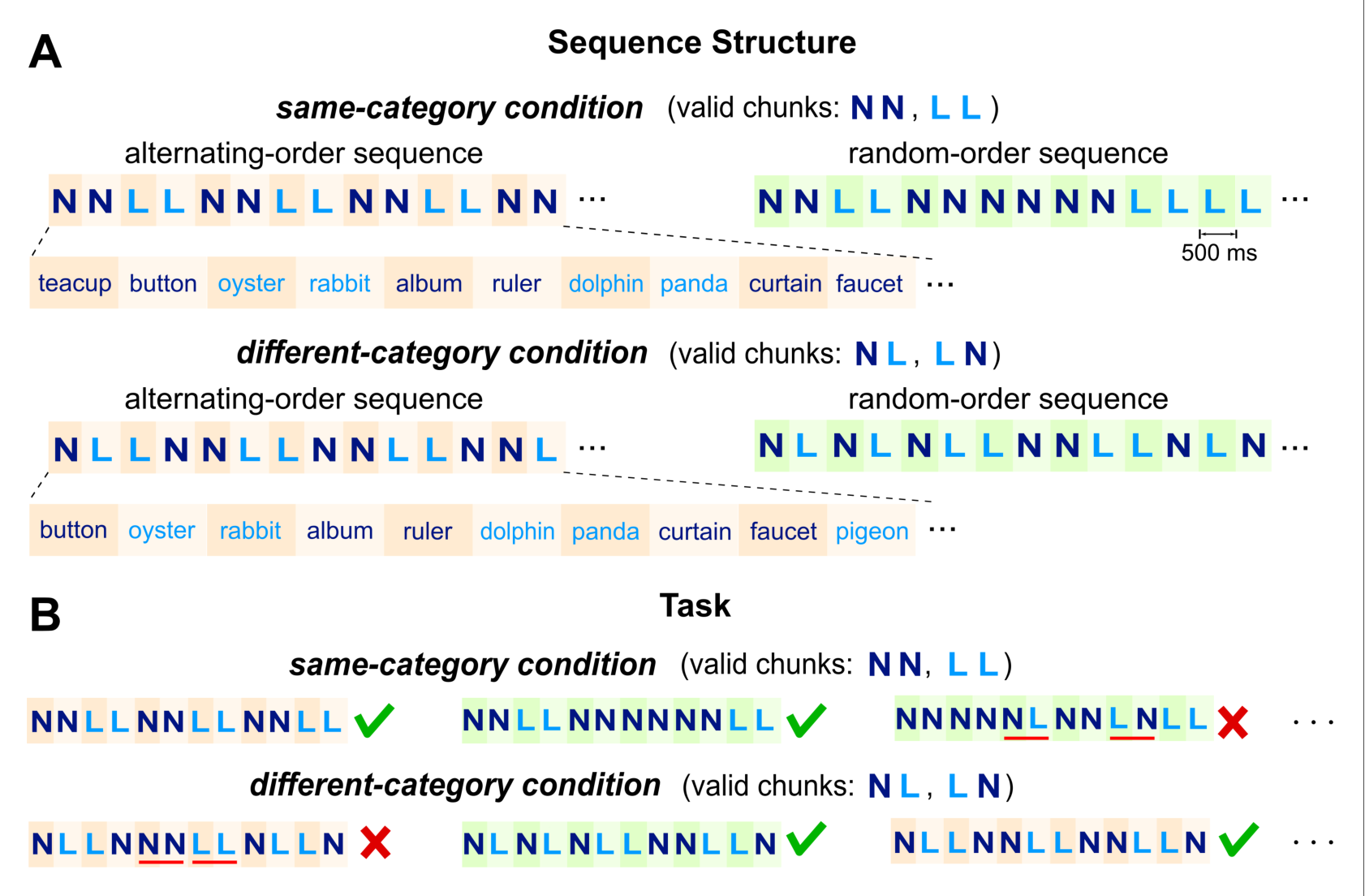
a. 词 ¶
共240个具体名词,其中生物名词(L)120个,分为动物(60)和植物(60)两个子类;非生物名词(N)120个,分为小物件(60)和大物件(60)。(语音材料由iFLYTEK合成器合成,并按照丁鼐等人2017年中的研究把所有的语音刺激强度和呈现时间(500ms)调成一致,对于单词内两个音节的强度和持续时间不做控制,存在协同发音情况。)
b. chuck ¶
两个词组成一个chunk,共有两种有效chunk,一种是同词类的即NN,LL;一种是不同词类的即NL,LN。
c. sequence ¶
一个sequence由24个词(12个chunk)串联组成,一个sequence共持续12s,两种有效词块以交替或随机的方式组成四种sequence(如图A)。sequence中的生物名词和非生物名词都是从两个子类中随机选取。有效词块交替组成的sequence都有一个稳定的结构,即由四词结构重复6次组成;有效词块随机排列组成sequence时,每个词块独立随机的从其对应condition下的两种有效词块中选择,当确定好词块中的词类别时,再随机的从词集(60个)中随机选择。(通过移除不同词类的交替sequence的第一个词可以转变成同词类的交替sequence。)
d. condition ¶
实验中同类词sequence和不同类词sequence分别在两个不同的block中进行实验,他们之间的顺序在不同的被试之间counterbalance。因此共有两个condition,每种condition中,30个交替顺序和30个随机顺序的sequence混合随机顺序呈现,其中8个交替和8个随机顺序的sequence中一个词块中的L和另一个词块中的N调换,这样就导致此sequence中有两个无效词块(如图B)。这16个sequence称为异常sequence。44个正常sequence和16个异常sequence混合以随机顺序呈现。
3.3 实验流程 ¶
熟悉合成词:被试先听单词再按键在屏幕上看听到的单词,然后被试可以按键选择再听一遍或者听一下个单词。
训练:先训练同词类的condition再训练不同词类的condition,明确告知被试sequence由2词词块组成,并被明确告知如何根据L和N构建有效词块,所有不符合有效词块构建规则的都属于无效词块,并且在实验中要监测无效词块。指导完被试之后,让被试先听两个正常的sequence再听两个异常的sequence,让被试在听到无效词块时尽快口头报告。可以根据被试需求再次播放sequence。
练习:之后被试进行一次在脑磁图扫描仪外的与正式脑磁图实验相同的练习实验,在练习和正式实验中,被试在每个sequence后根据正常和异常sequence作出不同的按键反应,做出按键反应之后会在1~2s随机的时间间隔呈现下一个sequence。当被试在五个连续播放的sequence中能够做出4个正确的判断则结束练习实验进入正式实验。
3.4 数据收集 ¶
在北京大学使用306传感器全脑MEG系统记录神经磁反应,采样频率为1 kHz。为了脑磁图源定位,使用北京大学的西门子Magnetom Prisma 3T MRI系统收集所有被试的结构磁共振成像(MRI)数据。
3.5 数据处理 ¶
只分析被试对正常序列的神经反应数据,用时间信号空间分离(tSSS)来消除脑磁图信号的外部干扰 (Taulu and Hari, 2009)。因为本研究仅关注0.5 Hz、1 Hz和2 Hz的反应,因此使用线性相位有限脉冲响应(FIR)滤波器对脑磁图信号进行0.3至2.7 Hz的带通滤波。提取每个序列的反应,下采样到20Hz的采样率,并称为一个试次(trail)。采用主成分分析法(PCA)将306通道脑磁图数据转换成分量以呈现波形,在PCA分析中,对相同和不同词类condition下的反应以及对交替和随机顺序序列的反应进行汇总。
3.6 频域分析 ¶
为了避免声音呈现时反应的影响,在频域分析中每个trial的前两秒都移去,因此每个trial的持续时间为10s,使用离散傅立叶变换(DFT)将所有试验的平均值变换到频域,DFT分析的频率分辨率是1/10 Hz。
3.7 源分析 ¶
在Brainstorm软件中(Tadel et al., 2011),使用皮层约束最小范数估计(MNE)将trial中平均的脑磁图反应映射到源空间(Ha¨ma¨laïnen & Ilmoniemi, 1994)。使用Freesurfer软件,T1加权的MRI图像用于提取脑体积、皮质表面和最内部的颅骨表面。
4. 模型模拟 ¶
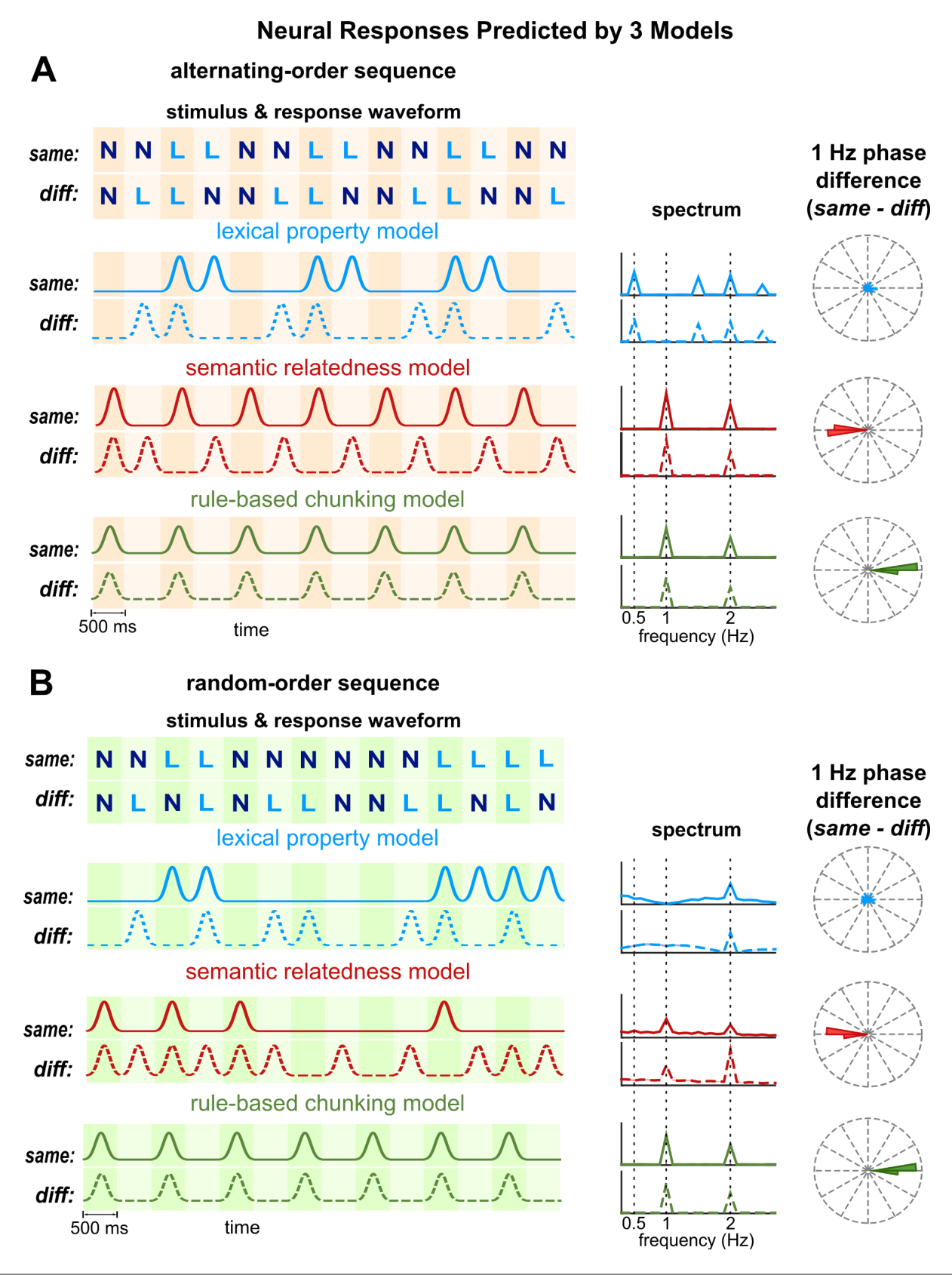
三个模型都认为序列中的最小单位是单词,模型输出是一个词一个词的,因此在模拟中,先使用脉冲序列来模拟,词汇属性模型和语义相关性模型是基于其单词语义引起刺激的,对于下图2所示的模型中,只考虑生物和非生物两个特征。每个特征取一个二进制值,当特征存在时为1,否则为0,每个词的脉冲幅度等于这个二进制值。语义相关性模型基于词汇属性模型建立:当前词和前一个词之间的语义相关度由词汇表征之间的相关系数来表征(Broderick et al., 2018)。此外,由于神经对刺激的反应通常较弱,如果刺激之前有类似的刺激,使用1减去相关系数来调制脉冲序列。在基于规则的组块模型中,单位振幅的脉冲被放置在组块开始时。
5. 结果 ¶
5.1 词序列和模型的预测 ¶
实验比较了基于两种不同规则构建组块的情况,它们分别在不同的block中进行,其中相同词类情况下的正确率为85 ± 2%,不同词类的正确率为 86 ± 2% 。分别分析这两种情况下的神经反应。可以直接比较相同词类和不同词类情况下的交替序列。
三种模型对相同词类和不同词类的交替和随机顺序序列的神经反应的模拟如图2所示。其中词汇属性模型认为两个神经群体分别调谐到生物名词和非生物名词的语义,下图只显示了调谐到生物名词的情况(图2AB)。在频域中分析的模拟神经响应表明,在频谱中,两个神经群体都没有在1 Hz(词块)处显示频谱峰值;与词汇属性模型相反,语义相关度模型和基于规则的组块模型预测1 Hz的响应峰值(图2AB中的红绿曲线)。
5.2 交替顺序序列的规则相关神经追踪 ¶
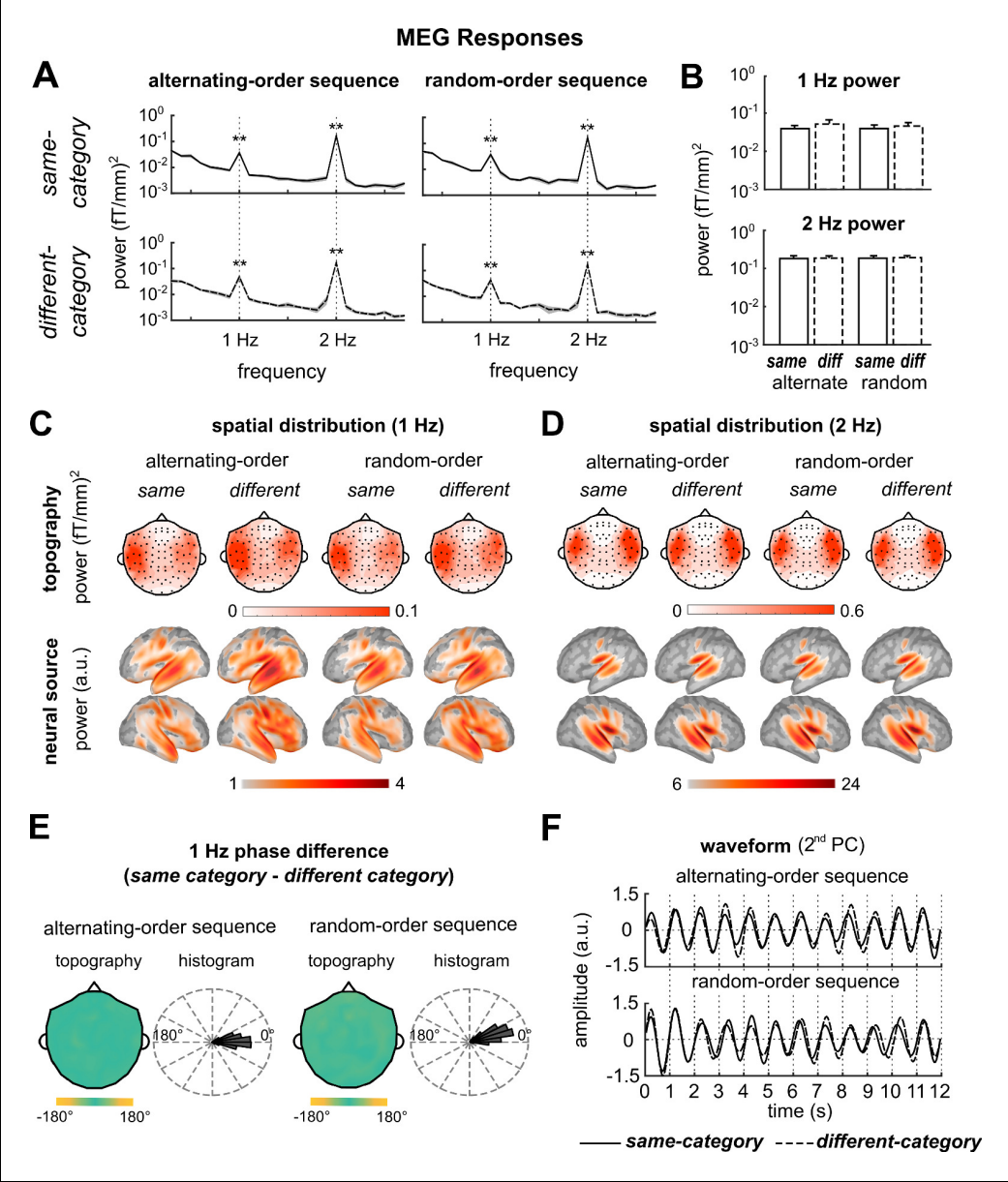
分别对相同词类和不同词类condition下的的MEG进行平均,并将平均反应转换到频域。首先分析交替顺序序列的MEG反应,两种condition都显示出明显的1Hz反应,1Hz的光谱峰值与语义相关性模型和基于组规则的组块模型所预测的一致,与词汇属性模型不一致。并且可以观察到明显的2Hz的值,没有观察到0.5 Hz的反应。
分析了不同condition在1Hz时的相位,在所有306个脑磁图传感器中,与180°相比所有被试的平均相位差更接近0°,并且所有脑磁图传感器的平均相位差明显更接近0°,平均相位差为0.5°,这个结果与基于规则的组块模型的预测一致。并且关于反应谱和反应相位差的主要结果可以在个体中观察到。
5.3 随机顺序序列的规则相关神经追踪 ¶
与交替顺序序列的分析方法一样,对随机顺序序列的MEG反应可以明显观察到一个1Hz的(如图3A所示),两种condition下的1 Hz反应都很明显,并且随机序列和交替序列的1Hz反应强度无明显差异(如图3B所示)。并且随机序列也显示出明显的2Hz峰值反应,对0.5Hz峰值的发应不显著。在所有的脑磁图传感器中两种condition在1 Hz的相位差也更接近0°(图3E)。
6. 讨论 ¶
此研究证明了低频神经活动可以追踪基于人工组块规则在心理上构建的多词组块。在加工序列事件时大脑是否表征序列的组块层级在认知领域包括语言加工、动作计划等方面一直是有争议的。这种多组块的表征在不同的领域分别被称为短语、图式等等,例如对于日常制作咖啡的行为,一种观点认为,大脑在这个过程构建了具有层次结构的计划,分为加糖加奶几个子计划,子计划又分为更细的计划比如打开包装,将奶倒入咖啡。另一种完全相反的观点认为,大脑把执行的基础动作直接串联并没有更高级组块的表征,似乎是层级表征的现象是附加产生的。之前的很多研究证据也分别支持了以上两种不同的观点。还有人提出,可能以上两种加工方法同时存在于大脑的不同区域,分别在不同的任务中执行(Goucha et al., 2017)。例如,在语言加工中,之前的研究提出基于单个加工的单词简单组合是在前颞叶进行的(Bemis and Pylkkanen, 2013; Brennan et al., 2012) ,基于规则的组块加工是在下额叶进行的(Grodzinsky and Friederici, 2006; Grodzinsky and Santi, 2008)。
在本研究中,被试执行的是显性的人工组块规则,与基于语言知识组成词块的隐形的规则不同,那么大脑在这两种不同任务中组块表征机制是否是相似的也不清楚。不同领域组块表征的机制通用的一个动机是许多序列组块任务使用共同的计算原则,即找到并编码组块边界。本研究中涉及到的决策变量不允许决策变量增加与更新,组块中第一个词无论是N还是L都不会影响决策,只有当第二个单词与第一个单词比较时才会更新决策。由于决策变量每一个组块更新一次,因此可能会对组块速率的反应有潜在的影响。本研究中的组块速率反应的神经源不是之前EEG/MEG研究中的主要决策信号P300成分,但它仍可能反映顺序决策,因为这种反应分布广泛 (Gold and Shadlen, 2007)。
不同的序列组块任务涉及共同的计算原理不一定意味着这些原理在共同的神经网络中实现。但是确实有证据表明有序列组块的主要神经网络区域,例如有fMRI研究表明腹外侧前额叶包括Broca不仅是语言加工的核心反应区,也是非语言序列加工的反应区。但是也有人主张特定序列加工机制有特定的加工区域,尤其是对语言的加工(Fedorenko et al., 2011),有研究表明对于新学习的规则,不同复杂程度的规则会激活额叶不同的区域;但是不同复杂程度的语法规则都会激活Broca区(Jeon and Friederici, 2013)。因此有人提出这样的假设,即自动过程和更多的受控过程依赖于不同的神经回路(Jeon and Friederici, 2015)。基于这个假设本研究中的人工显性规则和隐形语法规则可能涉及额叶不同区域,以脑磁图的空间分辨率,本研究无法精确定位组块速率反应的神经来源,但是本研究发现额叶激活是双侧化的,并且没有观察的明显的偏侧化,这与句子追踪的偏侧化反应相反(Ding et al., 2016; Sheng et al., 2019)。
对于语义相关性模型来说,众所周知如果目标单词前面有一个语义相关的单词,那么对目标单词的处理会更快,而且它的ERP的N400成分和它的MEG对应神经反应会减小(Broderick et al., 2018; Kutas and Federmeier, 2011; Lau et al., 2009)。因此按理说,本研究中同词类比不同词类组块的语义相关度大,但是由于本研究中所使用的为例如L又分为动物和植物两大词,例如就算同属于L的乌龟和兔子之间的相关性还是比较弱,因此神经反应中也没有显示出语义相关性的反应。
本研究不能区分组块速率的神经反应到底是哪种组块加工机制所驱动的,只能证明单个单词的神经追踪不能完全解释组块速率的反应。但是本研究与之前的研究充分表明大脑可以根据长期句法规则或在实验中学到的临时规则来构建高级语言表征。