文献:Gennari, G. , Marti, S. , Palu, M. , A Fló, & Dehaene-Lambertz, G. (2021). Orthogonal neural codes for speech in the infant brain. Proceedings of the National Academy of Sciences, 118(31), e2020410118. https://doi.org/10.1073/pnas.2020410118
论文原文 ¶
1. 研究背景 ¶
大脑对不断变化的语音信号提取稳定的表征的能力对人类尤其是语前儿童非常重要,因为要习得语言他必须在非常不一致的语音信号中获得语音、词汇、句法上的组织规律。然而,这种能力的神经基础仍未明确。
视觉领域基于物体和人脸识别过程中神经元记录的最新发现表明,为了处理大量传入的图像,大脑将输入分解为独立和正交的低维成分,每个成分编码不同维度的变量。最近成人颅内高分辨率记录和fMRI数据表明:在被动听语音的过程中,观察到了部分语音特征的神经特殊化。那么早期婴儿语音感知是否用了同样的分解策略?
大量的经典研究已经证明,婴儿来到这个世界上时具备区分不同语音感知的能力,并且行为学以及神经影像学的研究都表明婴儿从出生就具备自发掩盖由说话者音质、音素、韵律所产生的声学上的变化的能力。并且,新生儿表现出的语音感知差异正好与具有语义差异的语音差异一致。随便早期具备发现音节间最小语音差异的能力,但并不能真正揭示潜在的神经代码的性质:婴儿可能会将话语作为一个整体来处理或者将它们分解成更小的元素(例如,音素或语音特征)。行为学上的研究表明新生儿和2个月大的婴儿无法在一组具有不同元音的音节中识别出共有的辅音。并且有研究表明婴儿能够用音节的数量而不是音素的数量对话语进行分类。鉴于以上研究结果,很多学者都提出音节是语音感知的最原始单位。计算模型也证实了在会话语音中通过一般听觉机制确实可以获得类似音节的结构。目前广泛认为这种宽泛的语言单位是词汇学习的起点。
神经影像学绕过行为学的限制开辟了新的范式,脑电图显示,3个月大的婴儿能够发现重复不同发音方式的CV音节中的同样的辅音。他们甚至可以不依赖于语境将每个辅音与视觉形状联系起来。这些发现好像都支持语音的亚音节加工,促使我们重新审视早期语音表征的形式。
2. 本研究 ¶
因此本研究用256通道脑电图系统,记录了3月龄婴儿对120个不同声学和语音特征的自然辅音-元音音节的神经反应。通过独立的改变辅音的发音方式(阻音与响音)和发音部位(唇音,齿槽音,舌音)来选择音节。每个辅音与两个元音(/i/和/o/)结合,由一个男性和一个女性说话者以五种不同的发音发出。使用多元解码分析婴儿在整个音节、音素、语音特征三个可能水平上的语音加工。如果婴儿能提取说话者不变的信息,那么训练其对男性声音产生的音节做出反应的解码器就有望推广到女性声音。因此推断如果辅音和元音分开处理,那么元音“o”的训练的解码器可以推广到另一个元音“i”。相反,如果每个音节都有自己独特的编码那个以上推论就不成立。在亚音节水平上,区分bo和do的解码训练是否能够区分mi和ni揭示唇齿发音位置的神经编码的存在,或者仅能区分bi和di则证明仅编码了辅音b和d。
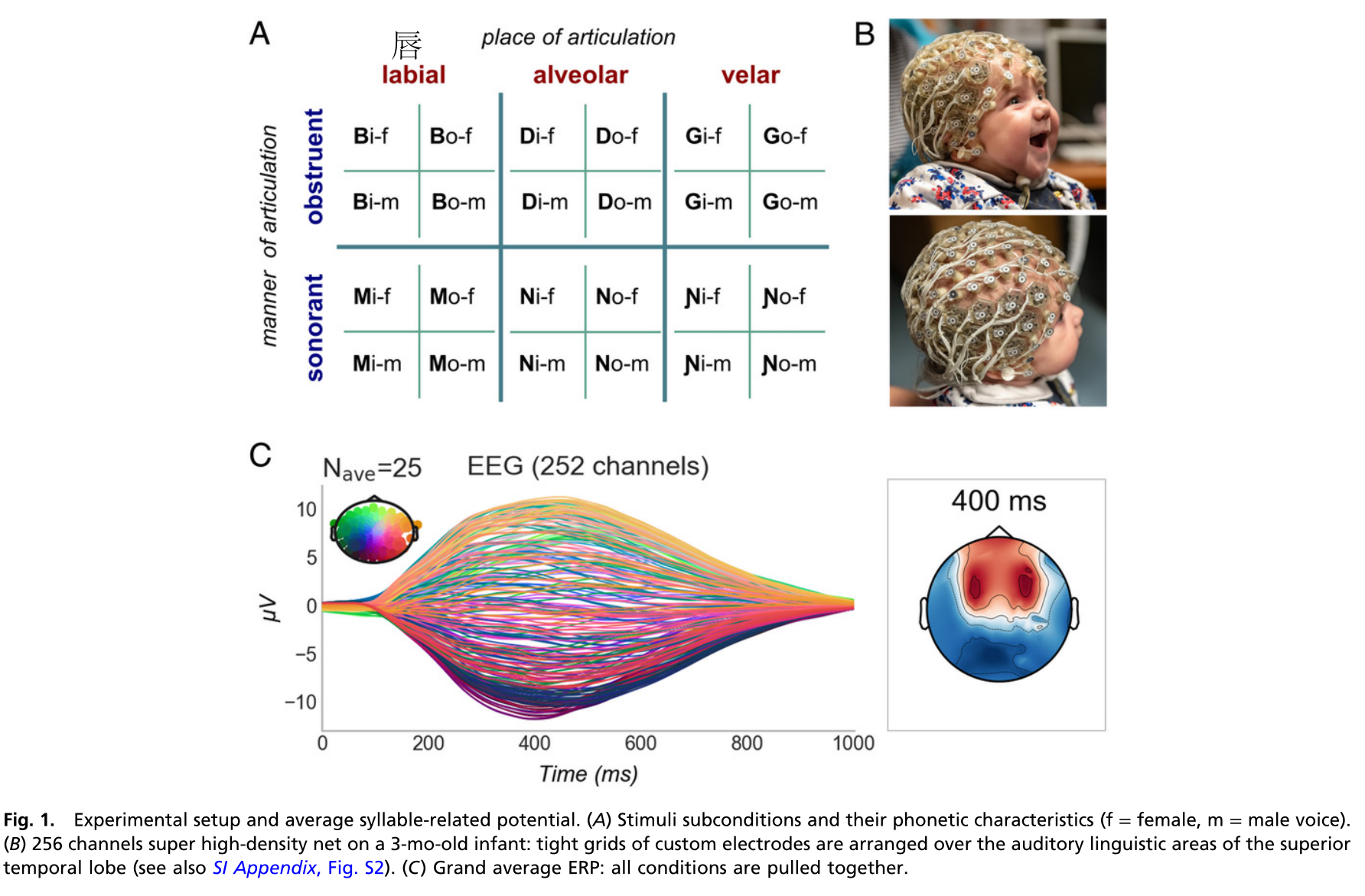
3. 研究结果 ¶
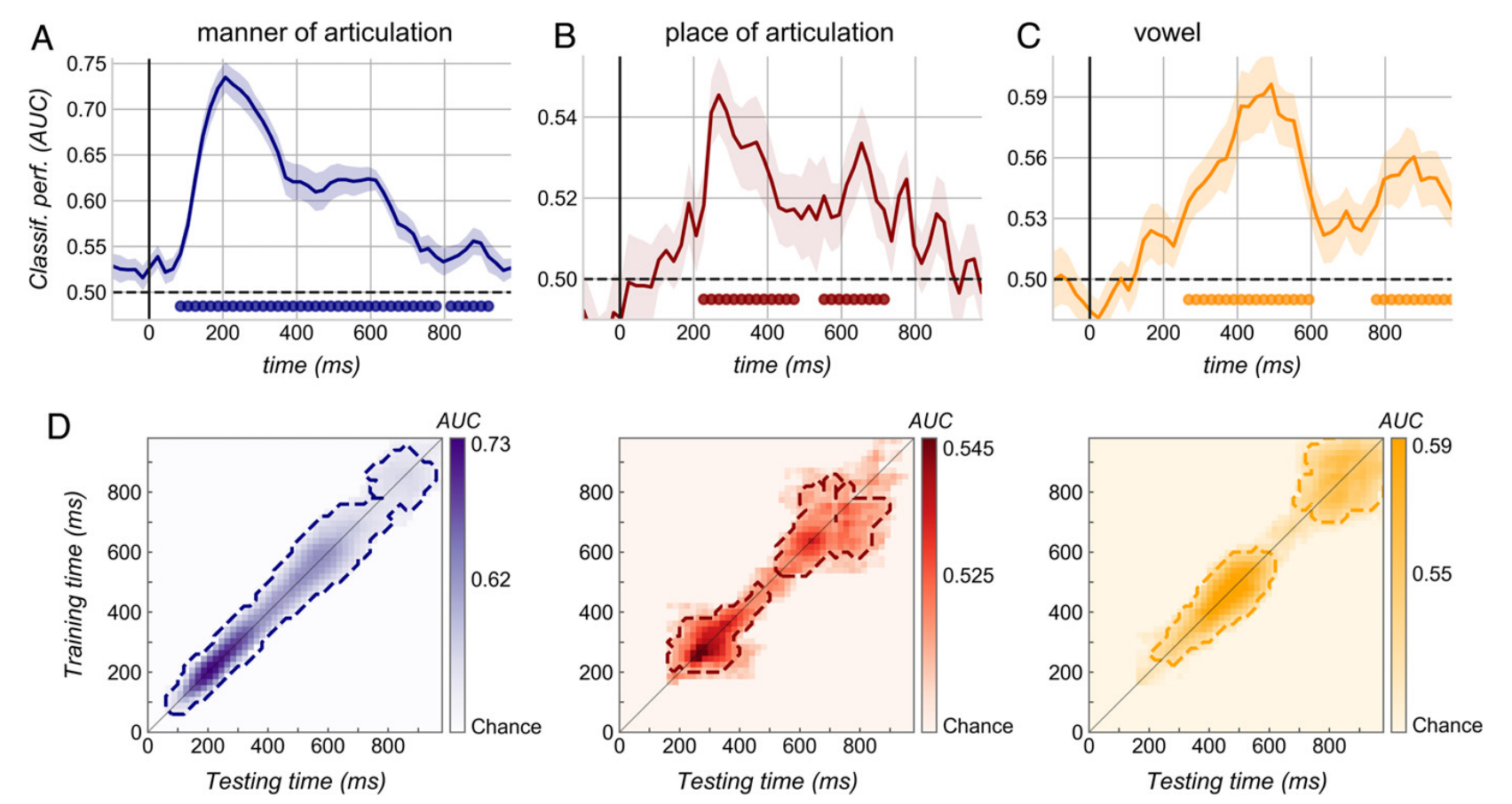
3.1 分类是在动态和离散神经模式的基础上实现的。 ¶
首先评估了接受过反应训练的婴儿的解码器是否能够根据语音刺激的语音特征对脑电图记录进行分类。图2AB显示从音节开始后80ms能够区分响音和阻音,而发音位置被分为两个时间窗:220-480ms。实验设计中的元音o和i在高度和后部都不同,排除了亚音节编码方式。图2C则显示出在260-400ms可以识别出元音。
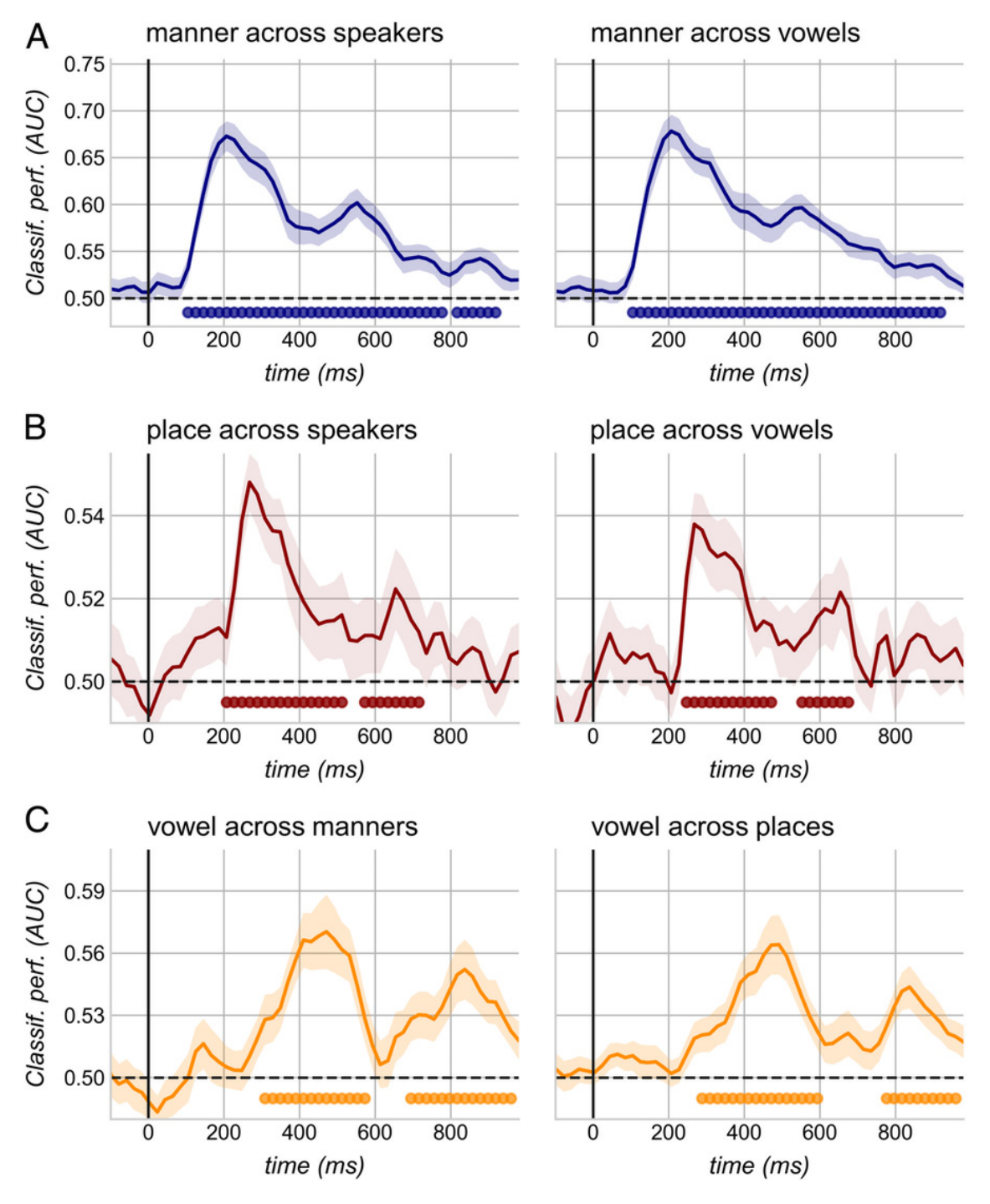
3.2 亚音节成分的不变代码 ¶
通过在单一上下文(例如,由女性声音说出的刺激)上训练新的发音方式和发音部位的估计器,并在用未训练条件(例如,男性声音)下测试,来检验神经代码的不变性。第一次分析纳入讲话者环境因素。第二次分析中纳入元音因素。因为之前关于婴儿和成人的的研究表明音素和讲话者身份的信息在早期是分开编码加工的,因此我们估计声音性别之间是能够全部推广泛化的。
3.3 音节首先被分解成对应于发音部位和发音方式的正交码,然后再进行综合 ¶
如果婴儿通过类似于语言学家假设的语音特征那样,将辅音分解成独立的正交维度来编码,那么在一个特征维度上训练的解码器应该可以获得成功的推广,而不管其他语音领域的变化。也就是说,预测器通过唇、腭帆和牙槽上提取发音方式编码,在阻音和响音上提取发音位置编码。
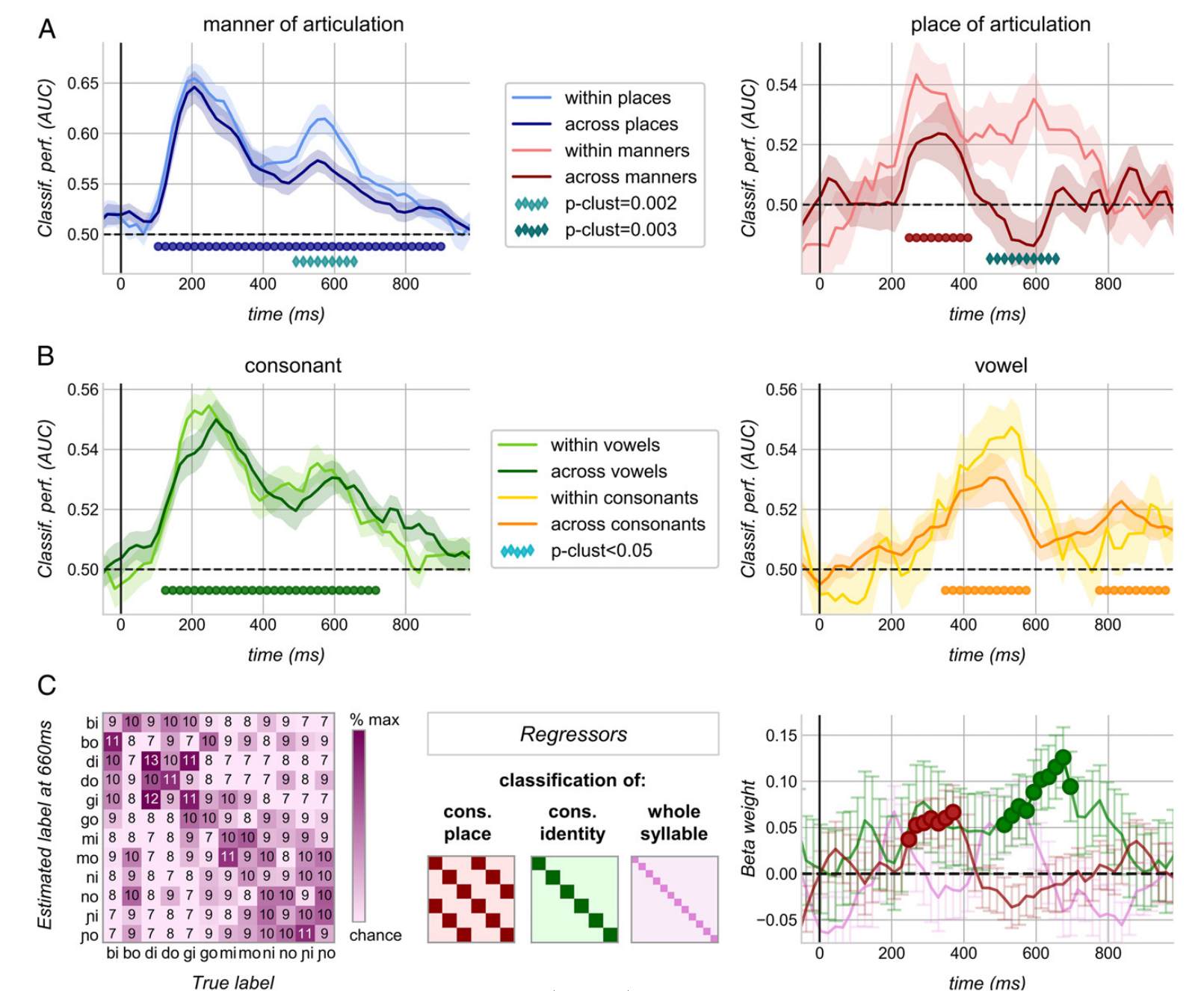
3.4 辅音和元音仍是分开的 ¶
如图2和3所示,元音解码性遵循双峰模式,与观察到的辅音维度非常相似,但峰值明显较晚。连同元音代码在辅音特征上的不变性(图3C),这些观察表明婴儿以独立且有序的方式对构成音节的两个音素进行编码。研究比较了元音和辅音条件下辅音和元音估值器的表现。结果如图4B所示,一个完整的音节代码的存在会导致整个语境的表现下降。这种下降从未发生,表明至少直到音节开始后1 s辅音和元音是保持分离的。
4. 讨论 ¶
这项研究中观察到的分类模式揭示了婴儿大脑中的两种语音编码格式。在处理的第一阶段,每个辅音通过其在发音方式和发言位置维度上的坐标进行编码,这可以从在一个维度上训练的解码器可以推广到另一个维度的不同级别得到证明。在第二阶段,这两个特征被组合成特殊的束,仍然允许音素分类,但阻碍了跨不同辅音的特征解码的完全推广和泛化。这种功能性进展与神经代码的动态性质一致,如图2D的矩阵所示。虽然实验主要集中在辅音上,但是元音的相似处理阶段也是可能的。最后,本研究没有发现完整的音节编码的证据。因此本研究推论,尽管缺乏发音运动计划和言语产生技能,但语前期的婴儿已经具备了结构化的言语分析的组合编码,这可能是婴儿第一年语言习得快速的原因。