文献:Gao, X., Yan, T. T., Tang, D. L., Huang, T., Shu, H., Nan, Y., & Zhang, Y. X. (2019). What makes lexical tone special: a reverse accessing model for tonal speech perception. Frontiers in psychology, 10, 2830. https://doi.org/10.3389/fpsyg.2019.02830
论文原文 ¶
1. 研究背景 ¶
以汉语普通话为代表的声调语言占全世界语言的60%(Yip & Chung, 2002), 但是对语音感知的研究却更侧重于以英语为代表的非声调语言。TRACE 模型是目前提出的语音感知机制最具有影响力模型,该模型是基于非声调语言所提出的;该模型把语音加工分为三个层次:特征、因素和词。征方面包括元音和辅音的声学特征,例如塞音、擦音;音素方面包括特定的元音和辅音;词方面包括接收到的词和与之相关的词。该模型假设每个层次都有其专门的检测器,Ye 和 Connine (1999)在这个模型三个层次的基础上添加了音调层次, 音调层与语素层平行,形成了一个简单扩展的TRACE-like模型 。 关于声调语音感知的研究一方面认为,对词声调信息的提取比音段信息更晚或更困难。例如,行为学实验在书面同音字的判断(Taft & Chen, 1992)、真词判断(Cutler & Chen, 1997)、快速区分判断(Cutler & Chen, 1997)、监测目标物出现(Ye & Connine, 1999)以及单词重组(Wiener & Turnbull, 2016)任务中显示基于声调信息的反应比基于音段信息的反应更慢;在6岁的普通话单语和英语-普通话双语儿童中也观察到对错误音调的敏感度低(Wewalaarachchi & Singh, 2020)。而另一方面研究认为,词声调信息对语音加工的贡献要等于甚至大于音段成分的信息,例如,行为学实验证据表明双音节词或习语中声调和音段信息的变化在词汇判断任务中具有同样的准确性(Liu & Samuel, 2007);在习语的音节监测中对声调比对元音变化的监测更快(Ye & Connine, 1999);眼动实验表明声调与音节末尾音素对语音与图片匹配任务中的影响相同 (Malins & Joanisse, 2010)。然而词声调反馈的劣势或优势的机制尚不明确。
2. 研究目的 ¶
本研究的目的就是验证是否如TRACE-like模型中所假设的那样:在语音感知处理过程中音素层面与音调层面是并行处理的。
3. 研究方法 ¶
本研究使用了缺乏上下文的实验范式,如下图1所示。
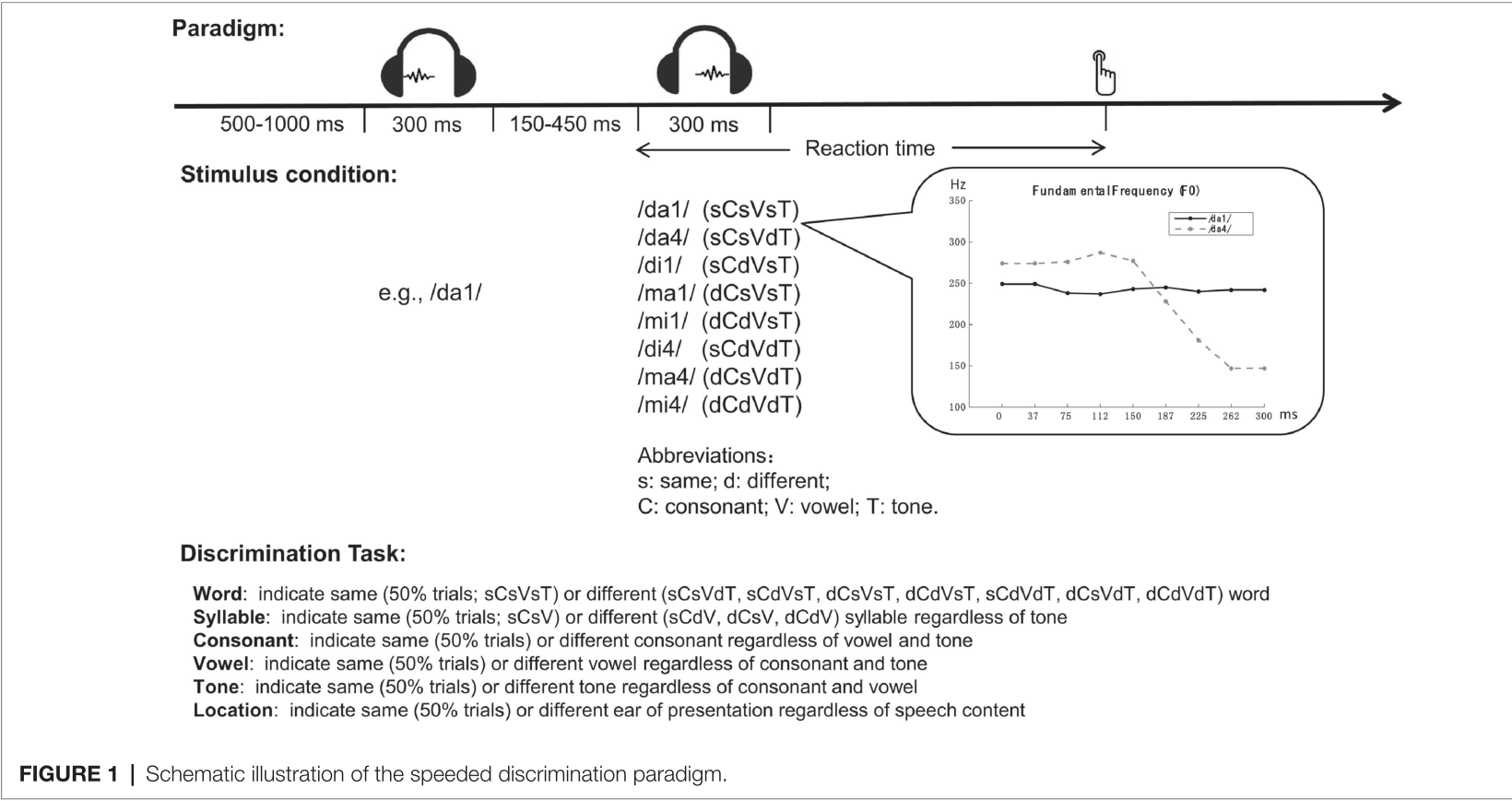
3.1 参与者 ¶
100名(平均年龄:22.8±2.4岁;61名女性)来自北京师范大学听力正常、无语言和认知障碍的参与者。
3.2 行为测试 ¶
给参与者连续播放两个独立的音节,并要求参与者对两个整个音节或者其中的子成分(词、音节、声调、辅音、元音和位置)是否相同作出一个快速的判断。由两个辅音(d,m)两个元音(a,i)和两个声调(一声,四声)独立组合成的八个不同音节组成的刺激集(/da1/, /da4/, /di1/, /di4/, /ma1/, /ma4/, /mi1/, /mi4/)。把所有有声调的音节成为词,所有无声调的称为音节。第一个刺激从刺激集中随机抽取,并随机呈现在被试的其中一个耳朵上,第二个刺激可以在位置(呈现的耳朵)、辅音、元音、词汇声调或它们的组合上与第一个标记相同或不同。
3.3 刺激条件 ¶
刺激条件由两个标记辅音、元音和声调相同或不同关系来表示,相同和不同的概率总是相等的,使所有任务都有50%正确的机会。词的差异被设定为词声调或音节(辅音、元音)或两者的差异;音节差异是辅音差异、元音差异或两者都有。位置辨别作为一项非言语控制任务,要求参与者指出两个声音是出现在同一个耳朵还是相反的耳朵,不论声音的内容是否相同。
3.4 数据收集和分析 ¶
4名参与者因为在所有任务中的错误率都低于85%而被排除,剩余96名参与者被随机分配到四个组。
4. 结果 ¶
4.1 不同任务之间的比较 ¶
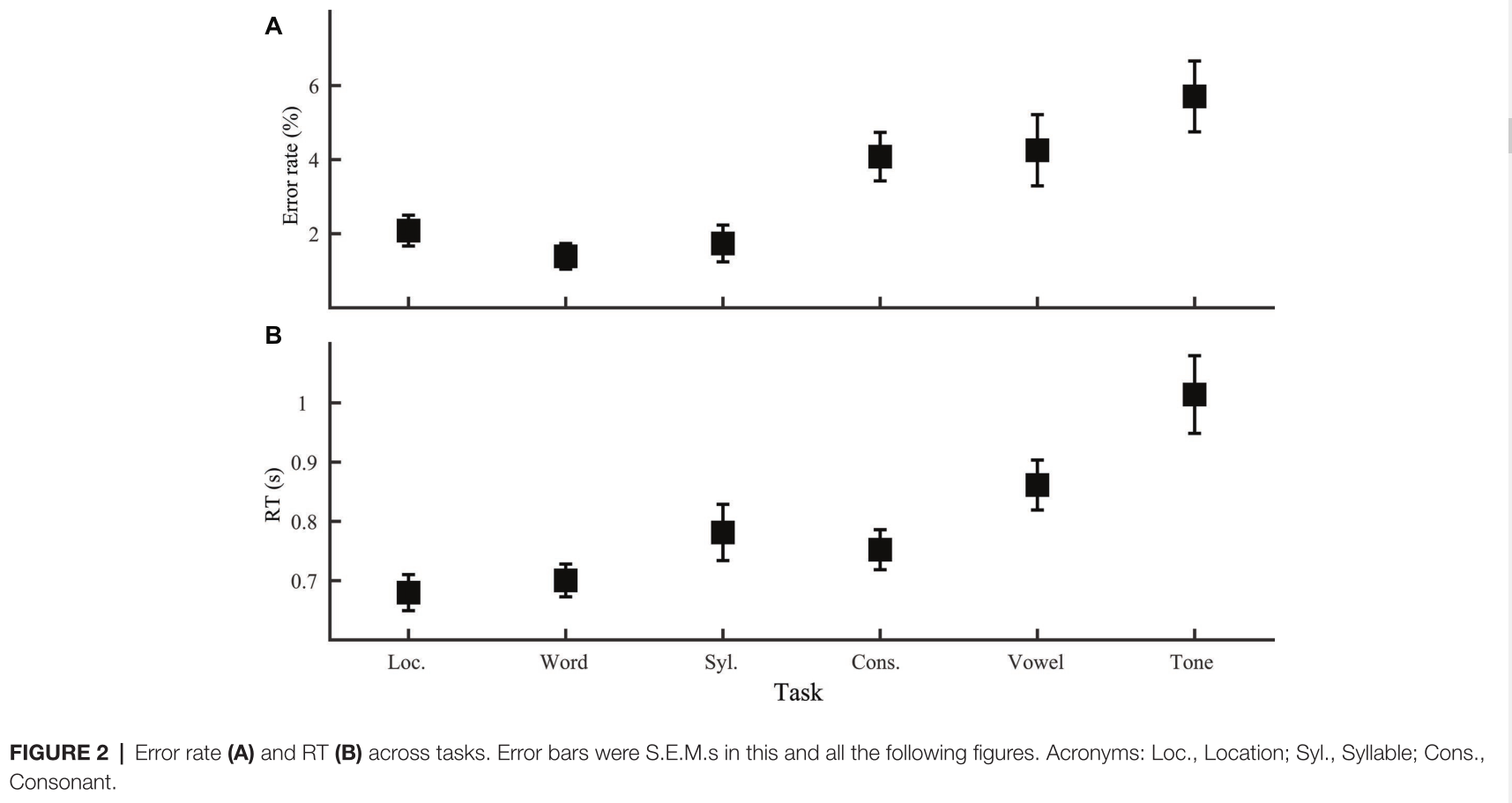
如下图2所示,错误率(one-way ANOV A, effect of task: F5,138 = 5.90, p < 0.001)和反应时(F5,138 = 8.23, p < 0.001)在不同任务中的差异显著。LSD post hoc 比较表明,六项任务可以基于错误率分为两组,位置、单词和音节辨别错误较少(这三个任务之间的比较p > 0.40,与其他任务相比p < 0.04),辅音、元音和声调的辨别更容易出错(这三个任务之间的比较p > 0.10,与其他任务相比p < 0.05)。基于正确实验的反应时(RT)将六项任务分为三组。声调辨别最慢(与其他任务相比P<0.05)。紧接着是元音辨别,比声调辨别快(p = 0.013),比位置辨别和词辨别慢(p < 0.01),与音节或辅音辨别没有差异(p > 0.05)。第三组包括位置、单词、音节和辅音辨别,彼此之间没有差异(p ≥ 0.1)。
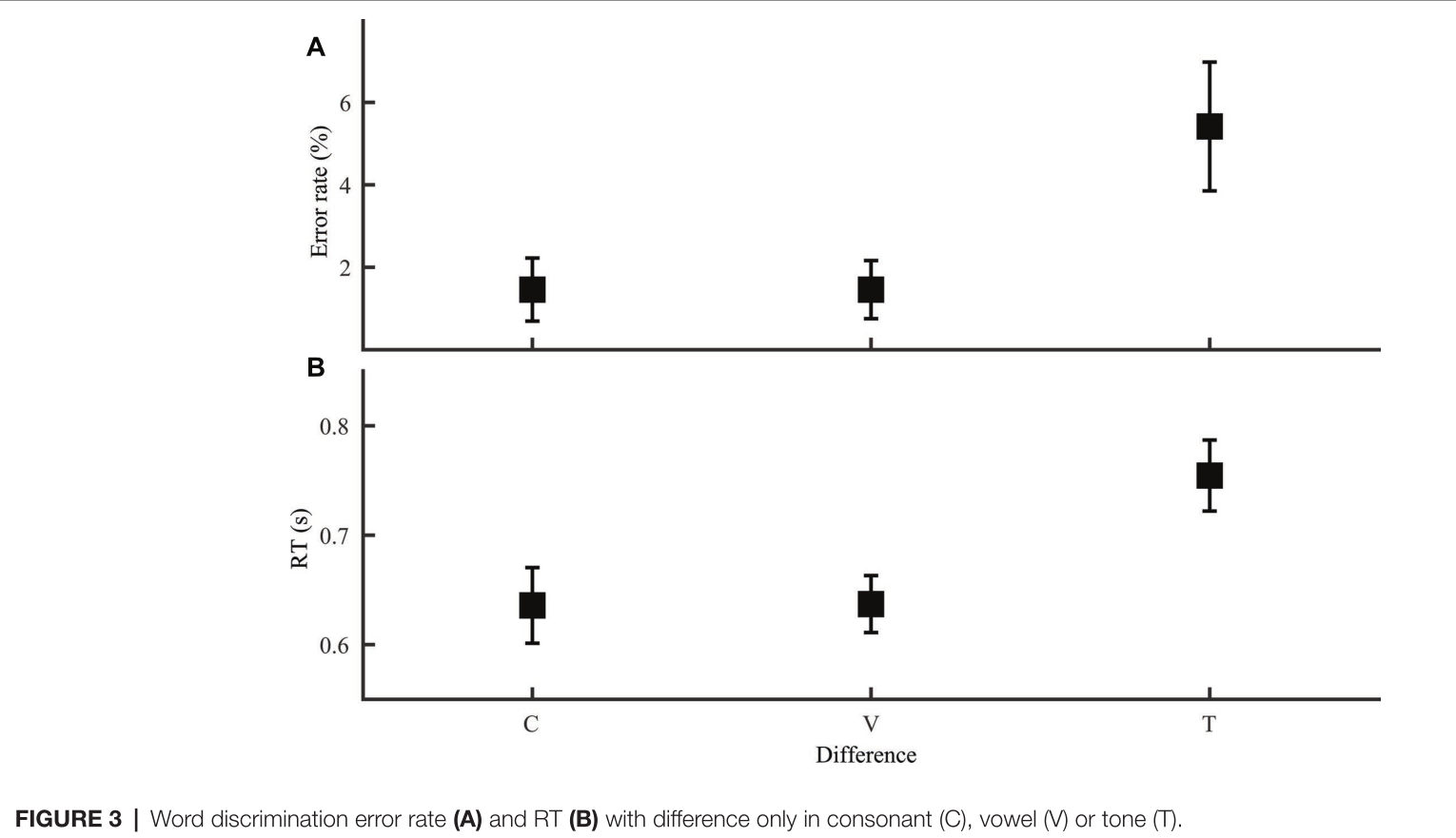
4.2 基于声调和音段差异的词辨别 ¶
实验比较了只有声调差异的词辨别试验和只有辅音或元音差异的词辨别试验。如下图3所示,LSD post hoc 配对比较发现,声调差异比声母差异和韵母差异表现更差,而音素之间差异表现相似。
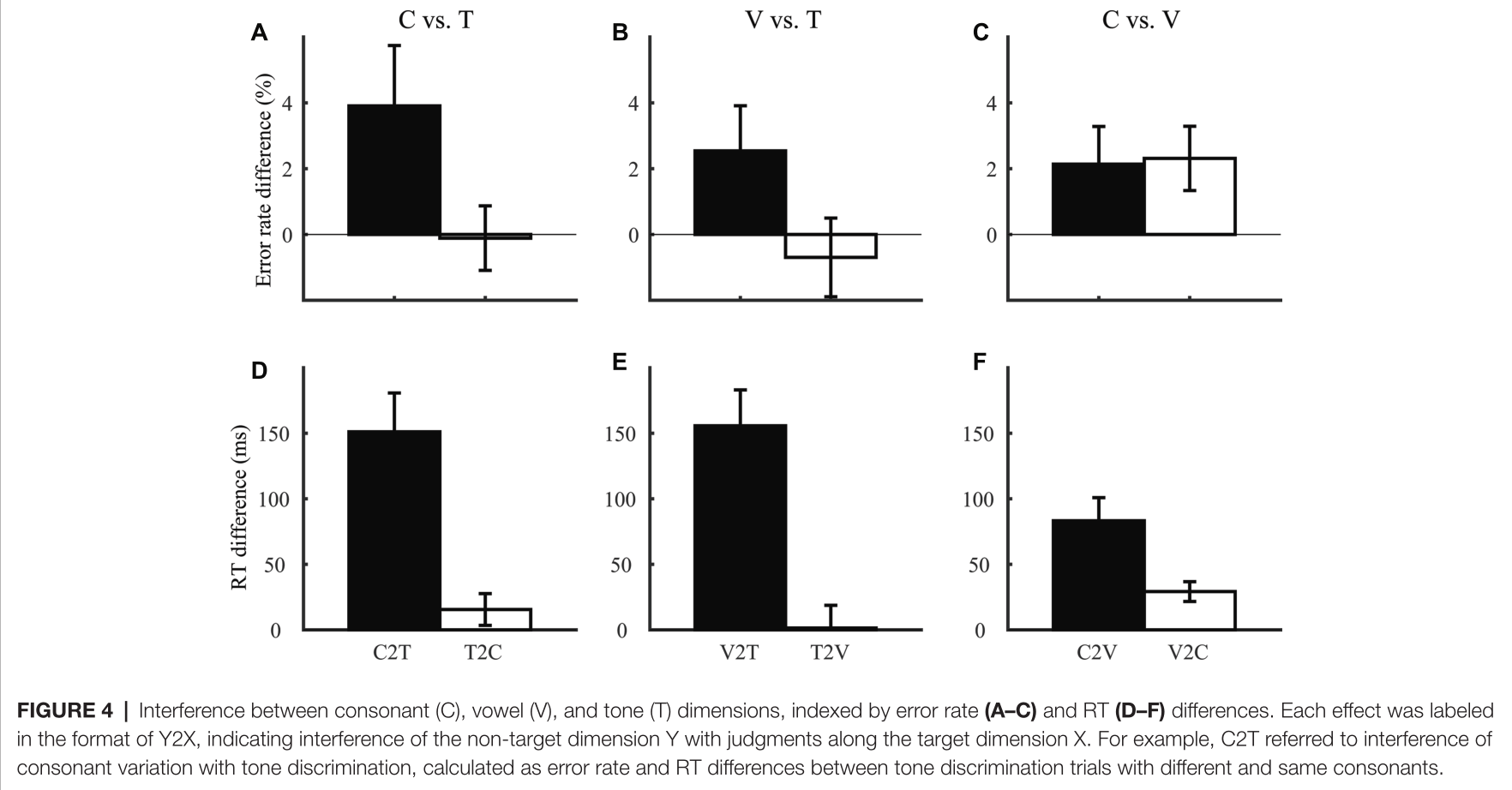
4.3 音素与词之间的干扰 ¶
本实验计算了非目标维度(如辅音和元音)的变化对目标维度(如词汇声调)判断的干扰。如下图4所示,错误率没有显著干扰。而反应时显示出明显差异。
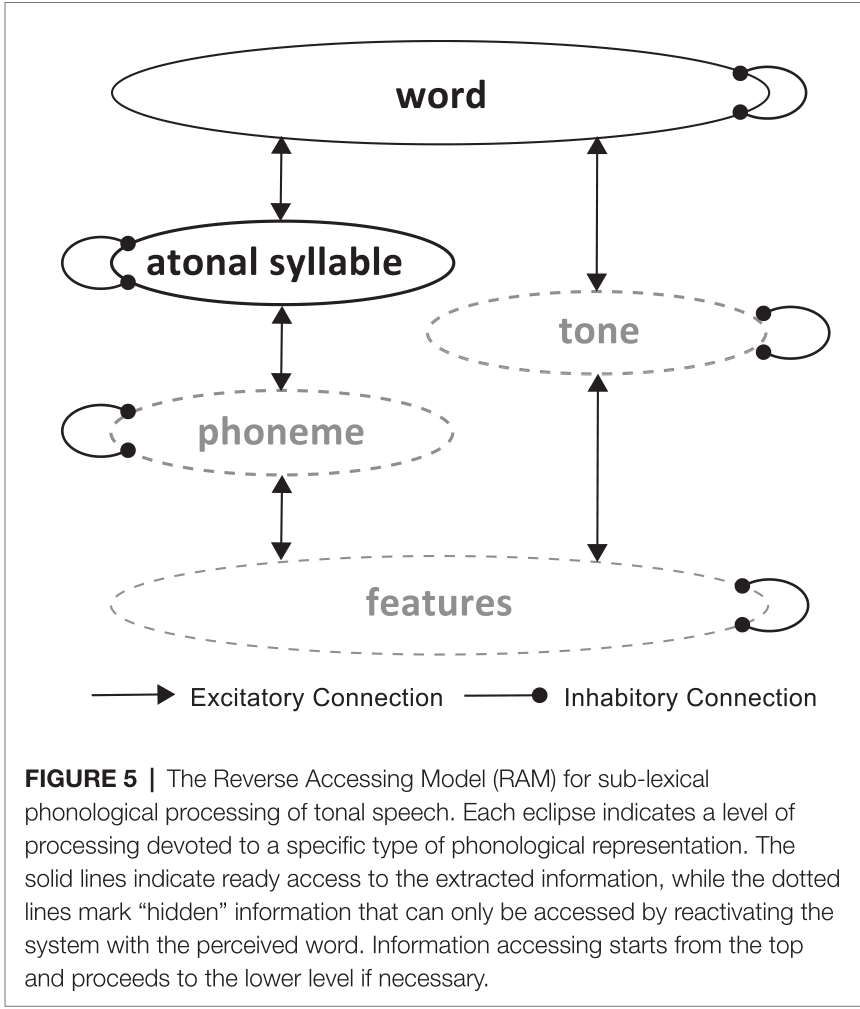
5. 讨论 ¶
RAM与TRACE有两个不同关键之处:首先,引入无声调音节的表征层次,这使辅音和元音信息可以在声调提取之前整合。其次,信息处理从顶层开始,根据任务需要从下层依次进行。此外,只有音节及以上层次的信息容易提取,而音素和声调层次的信息只能通过大脑对所感知到的单词重新激活。