文献:Ding, N., Melloni, L., Tian, X., & Poeppel, D. (2017). Rule-based and word-level statistics-based processing of language: insights from neuroscience. Language, cognition and neuroscience,32(5), 570-575. https://doi.org/10.1080/23273798.2016.1215477
论文原文 ¶
1. 引言 ¶
为了准确灵活的表达意思,人类基于语法规则将较小的语言单位组合成更大的语言单位。然而,在语言的理解过程,大脑如何编码单词之间的关系并将它们组合成短语仍不清楚。一种假设提出的rule-based 模型认为支配语言生成的内部语法原则也用来解析接收到的口语的句法层级结构。而另一种假设提出的N-gram 统计模型认为,在语言理解过程中解码语言仅依赖于单词串之间的统计关系,而不构建分层语言结构。最近的神经语言学研究表明,追踪单词之间的概率关系不能解释语言理解过程中语言结构成分的皮层编码,也不足以支持语言理解过程中基于规则的加工。
2. 语言处理的可预测性 ¶
大脑主动地预测使输入的单词能快速的加工(Dikker, Rabagliati, Farmer, & Pylkkänen, 2010; Marslen-Wilson & Tyler, 1980; Poeppel, Idsardi, & von Wassenhove, 2008; Tanenhaus, Spivey-Knowlton, Eberhard, & Sedivy, 1995),并有助于在具有挑战性的听力环境中丰富不太明确的感觉信息(Miller, Heise, & Lichten, 1951)。例如,在嘈杂的环境中,单词间转移概率较高的句子比转移概率较低的句子更容易识别(Miller et al., 1951)。这种现象我们把它解释为对语言处理的可预测性。 统计语言模型的一个主要动机是描述大脑如何对未来单词进行预测。在N-gram统计模型(Martin & Jurafsky,2008)中,未来单词W是基于该单词之前的N-1个单词来预测的。并且这个模型已经在工程环境中成功应用。 但是N-gram模型能够充分描述人类理解系统一直是有争议的。有以下几个争论点:第一,有些句子虽然符合语法,但词与词之间的转换概率极低,就像乔姆斯基杜撰的著名例子:“colorless green idea sleep furiously”。大量的心理语言学和神经语言学研究表明,像这种句法正确但可预测性很低(通常无意义)的句子与句法不正确的随机单词序列的处理方式不同(Friederici, Meyer, & von Cramon, 2000; Marslen-Wilson & Tyler, 1980; Pallier, Devauchelle, & Dehaene, 2011)。正确的句法(或语音)结构也可以通过产生预测来促进语言处理(DeLong, Urbach, & Kutas, 2005)。然而,这样的预测是基于默认的句法(或语音)知识,而不是N-gram转移概率。第二,人类语言的语法允许单词之间长距离依赖。例如,“you can either read the first sentence of the first paragraph of the first book or not read it”。短语之间的距离可以是任意长度,这取决于嵌入子句的数量。在这种情况下单词“either”对后面的单词“or”的预测就不是基于N-gram模型的。这种情况在语言中也是非常常见的。这种远距离的依赖也可能以其他形式出现。例如 “These insects can digest wood because … in the morning they really like to eat pine.”在这个句子中,尽快“eat”后面跟“pine”之间的概率非常低,但是这里“pine”的可预测性是基于上文的语境。 总之,N-gram模型并不是用于预测接收语言信息的唯一信息源,它不能描述基于句法信息或语篇层面的上下文所做的预测。因此,rule-based 模型和N-gram模型的区别不在于大脑是否做出预测,也不在于大脑是否对统计规律敏感;关键的区别在于大脑追踪统计规律并产生预测的语言单位是哪种——层级结构还是线性N词串(Townsend & Bever,2001)。
3. 统计模型和rule-based层次模型之间的关系 ¶
基于统计的处理和基于规则的处理是相关的,而不是相互排斥的。首先,句法规则为统计提供线索。第二,有人提出,规则可以基于统计线索来学习。通过大量的暴露于语言环境中,人类可以抽象出组合语言的语法规则。抽象/概括可能是rule-based处理和统计处理之间的潜在联系(Marcus, 1999; Seidenberg et al., 2002)。 这两个模型之间的区别是,rule-based使用分层的句法“组块”来描述单词之间的关系,而N-gram模型描述单词之间的线性关系。
4. 层级结构的构建及其神经关联 ¶
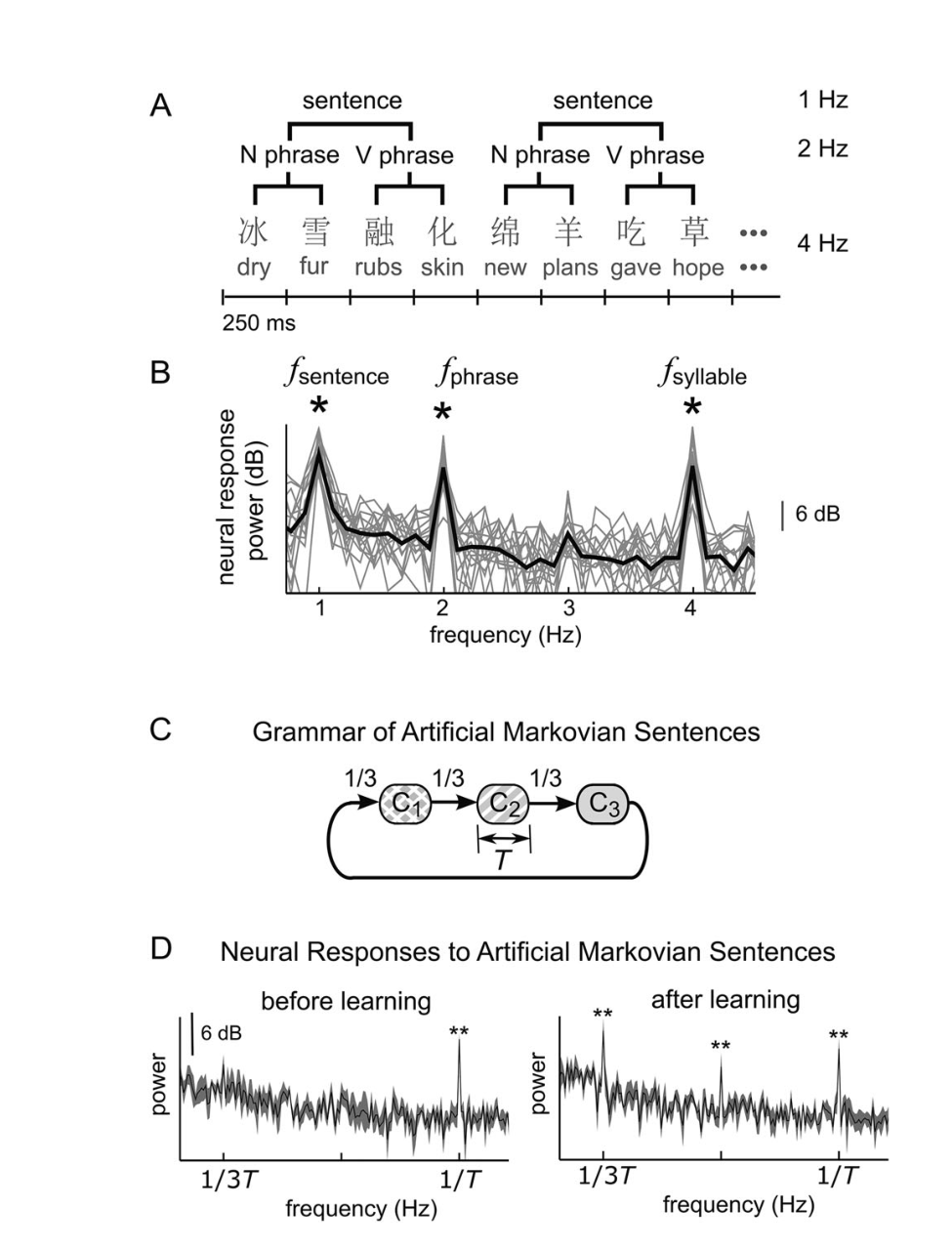
对语音和声音序列处理的神经编码的研究可以阐明rule-based模型和N-gram模型之间的争论(Bahlmann, Gunter, & Friederici, 2006; Brennan et al., 2012; Dikker et al., 2010; Fitch & Friederici, 2012; Friederici, Bahlmann, Friedrich, & Makuuchi, 2011; Pallier et al., 2011)。例如,功能磁共振成像研究表明,基于规则的语言层次结构的构建主要发生在左额下回,例如Brodmann区44和颞区(Fitch & Friederici, 2012)。 在神经生理学研究方面,一方面,大量文献表明,即使没有任何基于规则的结构,大脑对各种类型的统计线索也很敏感(Kutas & Federmeier, 2000; Näätänen, Paavilainen, Rinne, & Alho, 2007)。另一方面,也有纯粹基于规则的层次语言处理的神经生理学证据。简要回顾以下两个神经生理学证据。 首先,大脑可以同时表示层次短语结构,即不同大小的句法组块,从而引起输入序列的多元表征。例如,有研究显示违反语境会引起经典的N400响应,类似于当局部句子违反语境时观察到的情况(Van Berkum, Zwitserlood, Hagoort, & Brown, 2003)。这一结果表明,大脑可以在类似的时间窗口内,即在单词出现后的半秒钟内,检测到局部和全局上下文的违规的情况。这表明大脑保持着一种局部和整体情境的表征,这种表征可以被迅速提取。仅仅使用N-gram模型很难解释这种现象,因为建模整体背景需要整合数十个单词,这超出了人类工作记忆的极限。还有例子研究表明,在听口语时,皮层活动同时遵循不同大小的语言结构的节律,例如单词、短语和句子(图1(a,b)),这为层级语言结构的同时神经表征提供了直接证据。