文献:Lu, Y., Jin, P., Pan, X., & Ding, N. (2022). Delta-band neural activity primarily tracks sentences instead of semantic properties of words. NeuroImage,251,118979. https://doi.org/10.1016/j.neuroimage.2022.118979
论文原文 ¶
1. 研究背景 ¶
人类的语言一般是组合式的:单词组合成句子。然而,大脑是如何表征句子的仍有争议。在语音处理领域,大脑如何跨词整合信息来理解句子和段落是令人费解的( Goucha et al., 2017 ; Hagoort & Indefrey, 2014 ; Pylkkänen, 2019 )。其中一种假设认为,大脑应用句法规则来递归地将词组合成更大的组块,形成分层组织的句法结构,然后基于其句法结构导出句子的意思 ( Chomsky, 1957 ; Frazier & Fodor, 1978 ; Friederici, 2002 )。另一种假设推测,大脑不构建多词块,而是通过统计和语义分析直接跨词整合信息( Elman, 1990 ; Frank et al., 2012)。 神经科学的一些研究测试了大脑语音理解过程中是否将单词组合成短语,结果并不统一。 其中一些证据支持“组块”假说:例如,在短语边界处观察到EEG闭合正移(CPS)反应(Li & Yang, 2009; Steinhauer et al., 1999),表明大脑对短语边界敏感;最近的研究表明,低频EEG和MEG可以追踪短语和句子的时间进程 ( Ding et al., 2016 , 2018 ; Keitel et al., 2018 ; Kulasingham et al., 2021 ),这被视为大脑应用句法规则将单个事件分组为上级组块的证据 ( Ding et al., 2017a ; Martin & Doumas, 2017 ; Meyer & Gumbert, 2018 );此外,包含短语结构的计算模型可以预测神经对语言的反应 ( Artoni et al., 2020 ; Brennan & Hale, 2019 ; Fedorenko et al., 2016 ; Hale et al., 2018 ; Nelson et al., 2017 )。
然而也有一些证据支持跨词整合信息假说:例如,无短语结构的模型可以更好地预测 EEG 对语言的反应(Frank et al., 2015);并且有人提出短语和句子的神经追踪可能是由于单个词的语义属性(Frank & Yang, 2018),例如,丁等人(2016)使用的句子是具有规律的句法结构,即形容词+名词+动词+名词,形容词和动词的出现率与句子的出现率相同。因此,有可能看似追踪句子的神经活动,实际上追踪了区分形容词和动词词汇的语义属性。 为了梳理句法结构和词汇语义属性的作用,最近的一项研究给参与者呈现了不构成句子的单词序列,并明确要求参与者应用人工规则来组合序列(Jin et al .,2020)。研究结果显示,皮层活动追踪的是由显性组块规则定义的多词组块,而不是词汇语义属性。然而对句子的神经追踪在多大程度上可以用词汇语义属性来解释仍不明确。当听者专注于单词的语义信息而不是执行sequence chunking 任务时,神经活动是否主要追踪词汇的语义属性也是不明确的。
2. 研究目的 ¶
本文主要研究task和sentential structure如何分别影响word sequences的神经追踪。我们使用一个word-monitoring任务来引导听众注意单个单词的语义属性。在这个任务下,为了研究sentential structure的影响,我们向听者呈现了句子序列和单词序列,它们被用来对追踪词汇语义属性的神经响应进行frequency tag。研究还使用word2vec模型来预测追踪词汇语义属性的神经响应,该模型是一种描述单词之间语义关系的连接主义模型( Bengio et al., 2000 ; Mikolov et al., 2013 ),并测试所测量的神经响应是否与模型的预测一致。此外,为了分析task对神经反应的调节程度,还比较了word-monitoring任务中记录的神经响应和显式sequence chunking任务中的响应 ( Jin et al., 2020 )。
3. 研究方法 ¶
当参与者听以1赫兹重复的句子和单词表时,使用脑电(EEG)记录大脑皮质活动。
3.1 参与者 ¶
此研究纳入了32个母语为汉语普通话的成年人(20至30岁,平均年龄23岁,14名男性),右利手,自我报告无听力损失、无神经障碍。
3.2 刺激 ¶
此研究呈现了两种词序列,如图1A,即词序列和句子序列。每个序列由24个普通话双音节词组成。所有的双音节词都是使用iFLYTEK合成器独立合成的。合成的双音节词直接连接构建序列,词之间没有声学间隙。每个双音节词是一个独立的语音单位,以2 Hz的频率同步出现。 在句子序列条件下,此研究构造了80个四音节句子,其中前两个音节构成一个名词(或一个普通名词短语),后两个音节构成一个动词(或一个普通动词短语)。这些句子都是汉语中常见的句子,平均每个句子在实验中出现5.7次。 与句子序列不同,词序列没有句法结构,而是由双音节名词(N = 240)构成,包括生物名词(l)和非生物名词(n)。生物名词包括两个子类,即动物(N = 60;例如:猴子、熊猫)和植物(N = 60;例如,郁金香,草莓)。同样,非生物名词包括两个子类,即可操作的小物体(N = 60;例如茶杯、牙刷)和大型不可操作物体(N = 60;例如游乐场、旅馆)。在每个词序列中分别从两个子类别中随机挑选生物名词和非生物名词。在词序列中,单词的语义类别以两个词为周期循环变化(图1A),并且每个单词的选择都独立于其相邻单词。 此外,为了建立离群试验,使用了42个双音节抽象名词(例如,荣誉、精神),并且每个抽象名词在实验中仅出现一次。
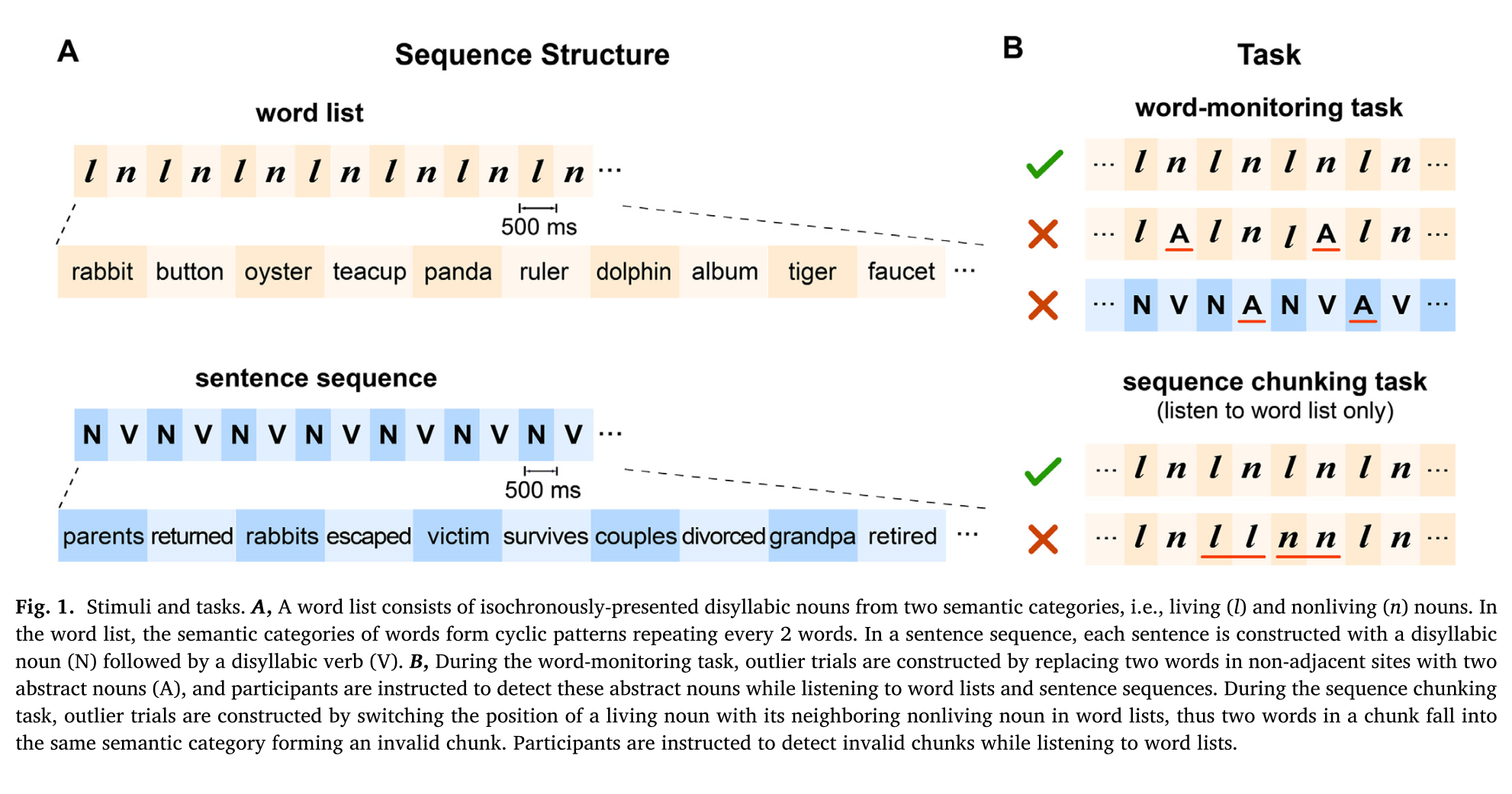
3.3 实验程序 ¶
在实验开始之前把实验中所用到的全部单词随机呈现给参与者以提前熟悉。采用EEG记录实验中的神经反应,实验分为三个block。在每个block中,30个正常的序列和7个异常的序列混合以随机顺序呈现。前两个block是当给参与者呈现单词序列和句子序列的时候让其执行word-monitoring任务,在这项任务中让参与者监测偶尔出现的抽象名词。另一种情况是在给参与者呈现词序列时让其执行sequence chunking 任务,在这个任务中告知参与者当词序列中相邻的两个词属于不同的语义范畴时(例如,生物名词和非生物名词)可以构成一个组块,并且要求他们监测包含相同类别词的无效组块(如图1B)。这个任务的离群实验的无效组块是通过调换相邻的生物名词和非生物名词来实现的。 在一次试验中,听完一个序列后,参与者按下不同的键来指示它是正常的还是异常的序列。然后,在1秒和2秒(均匀分布)之间随机化的静默间隔之后,呈现下一个序列。EEG仅分析正常序列的实验。
4. 结果 ¶
4.1 模型预测结果 ¶
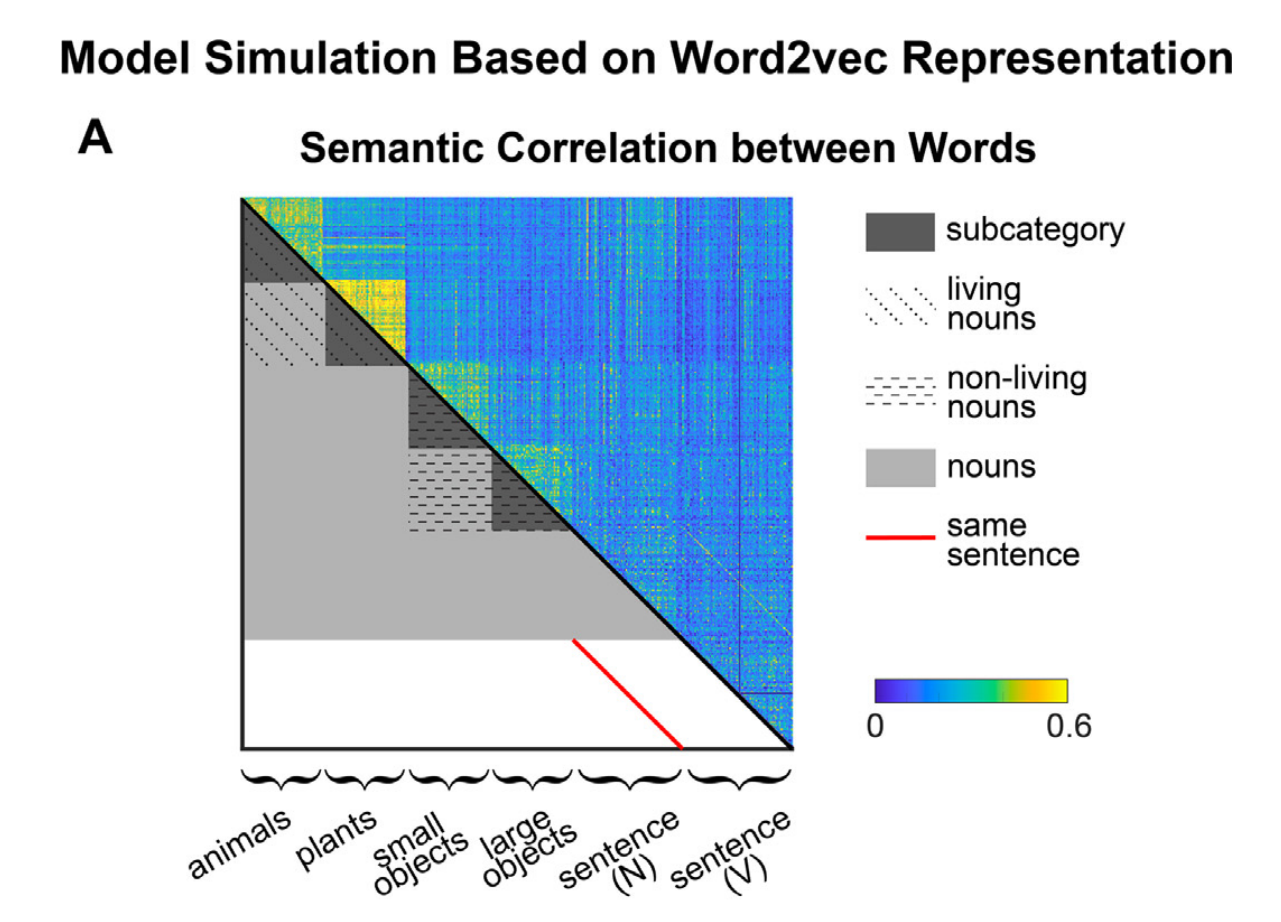
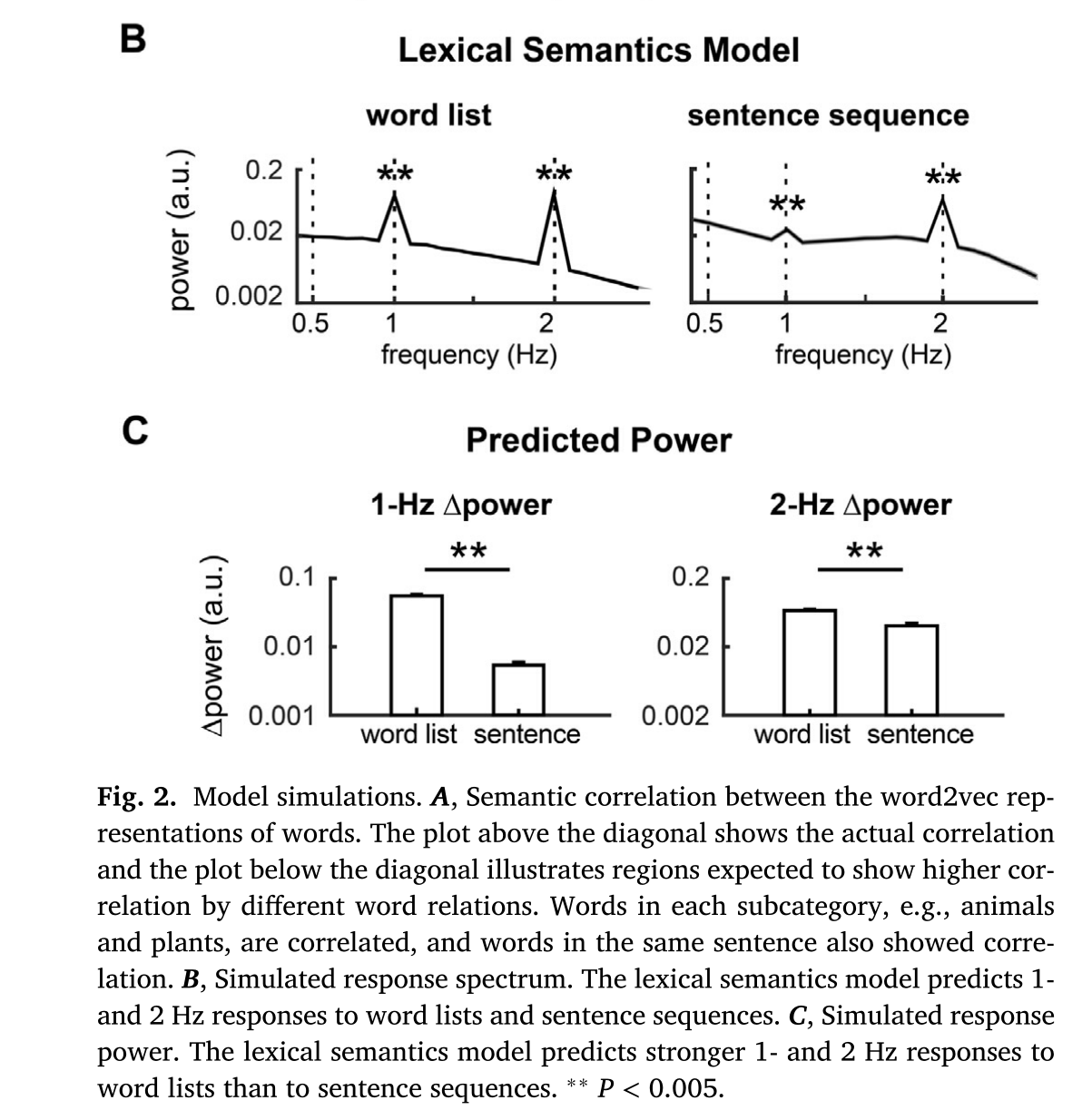
4.2 EEG反应 ¶
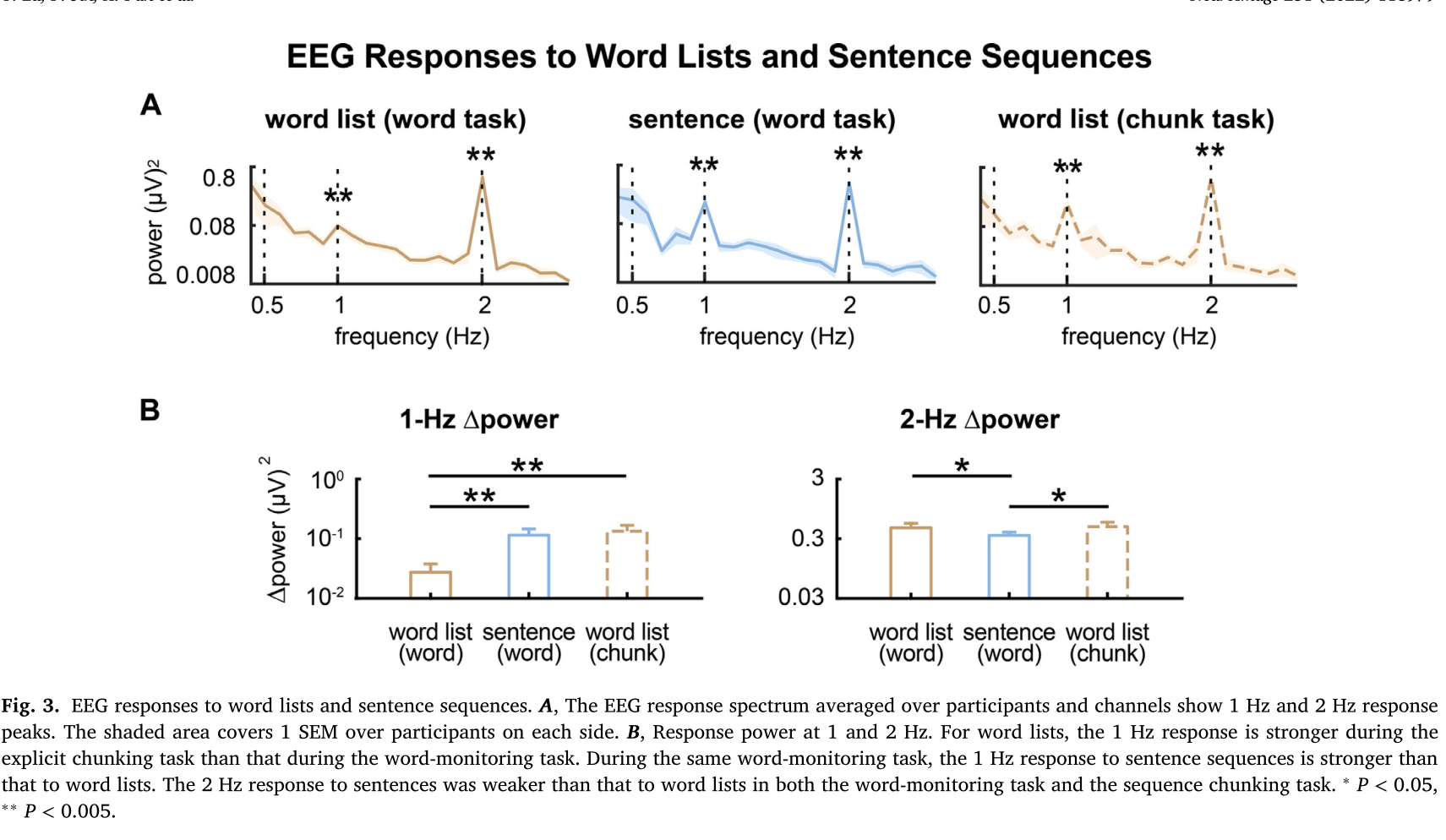
5. 讨论 ¶
在言语理解过程中,大脑是否构建短语和句子表征已经争论了很长时间。有人认为,大脑皮层活动追踪了语音中的句子和短语结构,证明了大脑中的句子和短语表征( Ding et al., 2016 )。然而,有人认为,明显的句子/短语追踪是由单个词的词汇属性的神经编码引起的( Frank & Yang, 2018 )。目前的研究表明,在word-monitoring任务中,脑电图对词序列的反应显示出1Hz的响应(图4A),这是由词汇语义学模型和单词发生频率模型预测的(图3)。词汇语义学模型进一步预测,对词序列的1Hz响应比对句子的强(图3),但现实中检测到的对词序列的1Hz神经响应明显比对句子的响应弱(图4B)。这表明,仅靠词的语义属性不能完全解释对句子的神经追踪。在明确的sequence chunking任务中,皮层活动可以明显追踪由人工分块规则定义的多词块,而且对多词块的响应程度与word-monitoring任务中的句子序列相似。
5.1 词的上下文相关属性的神经编码 ¶
对单词(例如N400成分)的上下文的神经反应敏感,例如与先前单词的语义关系( Kutas & Federmeier, 2011 ; Kutas & Hillyard, 1980 , 1984 )。最近的研究表明,神经活动可以追踪lexical surprisal/predictability( Gillis et al., 2021 ),而不依赖于它们的semantic relatedness ( Frank et al., 2015 ; Willems et al., 2015 )。在此研究中,从大型语料库中计算出的二元语法概率显示,句子比单词序列有更强的1 Hz变化。每个句子在实验中出现了5、6次。相比之下,单词序列中的生物单词和非生物单词是随机配对的,单词对很少重复。因此,相对于词序列参与者更容易预测句子中后面的单词。 因此,semantic relatedness 和lexical surprisal/predictability都可以预测对句子的1 Hz响应强于对单词列表的1 Hz响应。然而,这些测量不能预测对单词序列的1 Hz反应。当前研究的目的是调查如Frank和Yang (2018)所提出的单个单词的语义属性分布是否可以完全解释delta波 EEG响应,因此,刺激没有排除例如单词之间的语义相关度和词汇可预测性的影响。未来的研究需要分析这些因素如何有助于语音的神经追踪。
5.2 多词块的神经编码 ¶
有人提出,大脑可以将多个单词组合成一个组块,并为该组块整体建立一个神经表征。一方面,在正常的语言处理过程中,单词可能会根据句法规则隐含地整合到语块中。另一方面,让参与者通过显性sequence chunking规则将单词分组为组块。此外,也有证据表明组块可以自发发生( Wymbs et al., 2012 )。人们更喜欢将项目分成两到四个项目的块( Lerdahl & Jackendoff, 1981 ; Miller, 1956 )。 组块可以通过多种机制实现。有人提出组块可以使用自发过程或受控过程来实现,这些过程涉及不同的神经回路( Jeon & Friederici, 2015 )。也有可能存在一个共同的核心皮层区域用于组块。例如,有功能磁共振成像研究表明,腹外侧前额叶皮层,包括Broca,不仅是语言处理的核心区域,而且可以被基于规则的非语言顺序处理任务激活( Koechlin & Jubault, 2006 ; Thompson- Schill et al., 2005 )。此外,组块也可以由不同的线索驱动,发生在多个维度上。例如,在自然语音中,韵律是驱动解析的关键因素,并且在韵律短语边界处观察到EEG CPS响应( Lia & Yang, 2009 ; Steinhauer et al., 1999 )。此外,语言理解过程中的组块也可能发生在语义和句法层面( Artoni et al., 2020 ; Brennan et al., 2012 ; Nelson et al., 2017 ; Zhang & Pylkkanen, 2015 , 2018 ),未来的研究需要调查哪个维度更强烈地反映在语音的神经追踪反应中。 总之,目前的研究和先前的研究( Jin et al., 2020 )表明,词的语义属性不足以解释delta波对句子的响应。相反,内隐句法加工和外显序列组块能更有效地驱动delta波响应。这些结果表明,delta波神经活动更好地解释了组块水平的神经表征,而不是词汇水平的神经表征。