文献:Zora, H., Wester, J., & Csépe, V. (2023). Predictions about prosody facilitate lexical access: Evidence from P50/N100 and MMN components. International Journal of Psychophysiology, 112262. https://doi.org/10.1016/j.ijpsycho.2023.112262
研究背景: ¶
预测编码(PC)理论被视为皮质功能的统一理论(Friston, 2010;Heilbron and Chait, 2018;Millidge et al., 2021)。PC理论假设大脑依赖于生成模型,将自上而下的预测与自下而上的感觉输入相结合(de Lange et al., 2018; Heilbron and Chait, 2018; Mumford, 1992; Winkler and Schr ̈ oger, 2015)。
在神经元水平上,生成模型预先激活预测刺激的皮层表征,并将这种预先激活的表征与感觉输入进行比较。感觉输入和基于表征的预测之间的匹配会导致神经反应的抑制,这种现象称为期望抑制(Bell, 2001;Garrido et al., 2018;Summerfield et al.2008;Todorovic and de Lange, 2012;Wacongne et al., 2011);而不匹配会导致预测误差信号(Friston, 2005; Summerfield and de Lange, 2014)。 预测机制的证据已经在语言层次的几个层面上被发现,包括语音、形态句法,词汇语义/话语和句法上下文。但PC原理如何应用于一般语言和语音处理的问题仍不清楚。
韵律: 与听觉信号的物理属性有关,如基频( f0 )、强度和时长(Bolinger, 1961; Fry, 1958; Lehiste, 1970),是在词汇和短语/句子层面进行有效交流的必要条件。本文关注的是词汇层面的韵律,具体涉及词重音这一韵律现象,重读音节通常比非重读音节有更长的时长,更大的音强和更高的f0。 词重音除了在感觉层面编码感知显著性外,在认知层面对语义内容也有影响。不同的重音位置有时会产生词汇上截然不同的最小对并且制约词汇加工,如英语中的重音交替同形词:′forebear fore′bear。 不同的语言在词重音的实现和功能上是不同的,根据音节之间的突显关系,出现了两种重音模式:扬抑格(强-弱)和抑扬格(弱-强)。
MMN成分: MMN成分是研究词汇重音处理中所涉及的预测过程的理想工具,它不仅表明大脑对听觉感官输入的韵律变化的自动反应,也是预测误差的神经生理特征。之前的MMN研究证实了( Zora et al . , 2015 ; Zora et al , 2016a)各种语言的重音知觉线索的相对重要性及其对词汇访问的影响。 在oddball范式中,MMN通常是由不常见的异常刺激穿插在频繁的标准刺激中引起的。大脑根据标准建立规则,并对即将到来的刺激产生预期;不符合这些期望的异常刺激会引发MMN反应(Garrido et al., 2009)。 自发现以来,有几种假设机制来解释MMN成分,其中两个主要假设:适应假设(J a askel ainen et al., 2004;参见Larsson和Smith, 2012;Matsuzaki et al., 2012)和模型调整假设(Winkler et al., 1996;Naat anen and Winkler, 1999)。适应假说将MMN解释为听觉皮层N100适应的产物,反映了简单的自下而上加工。重复标准刺激的N100振幅由于重复抑制和侧抑制而降低,而异常刺激引起N100增强,反映了非适应N100神经元的激活(Butler, 1968;May和tititinen, 2004)。模型调整假说假设MMN反应反映了由于预测和实际感官输入之间的差异而导致的感知模型的在线更新(Winkler等人,1996;N a at anen and Winkler, 1999),和关于感官输入的长期经验对模型有调节作用(Winkler和Schr ø oger, 2015)。 对于语音和单词等熟悉的东西来说,MMN成分更大,这证明它反映了更高的认知过程,比如与熟悉的东西相关的长期记忆痕迹的激活,超越了感觉处理。MMN对有意义的熟悉事物的反应可以解释为分布的神经元记忆回路。Hebb(1949)的模型假设:共同激活的神经元发展成具有反馈和前馈连接的记忆回路,并且正是这些强连接的细胞组合的激活导致了学习认知表征的MMN增加(N a at anen, 2001;Pul vermller和Shtyrov, 2006)。以上所有的模型都展示了预测在语音感知中的作用的不同视角,并引发了一个关于PC环境下MMN响应的特定问题(Garrido等人,2008;Garrido et al., 2009;Grisoni et al., 2019)。
P50成分: 被认为是强制性的ERP成分,主要受刺激的物理特征的影响,并且发现在oddball范式中,P50对不常见的异常刺激更大。它也是对不相关刺激的抑制指数,这种现象被称为重复抑制或感觉门控、习惯化、神经适应。所有这些现象的特征都是P50对重复刺激的反应衰减,特别是在配对刺激范式中。
N100成分: 是另一种重复诱发的神经衰减(Fruhstorfer et al., 1970;Woods and Elmasian, 1986)。N100振幅被证明对语音比非语音更弱(Woods and Elmasian, 1986),对预期音调比意外音调更弱(Todorovic et al., 2011)。N100分量也反映了对节奏预期的违反(Cason and Sch ̈ on, 2012; Zhang and Zhang, 2019)。Cason和Sch ̈ on(2012)观察到,当重读模式与启动词不匹配时,目标词的N100反应很大,这表明发现了与预期不匹配的听觉事件。
本研究 ¶
从PC框架中获得灵感,研究了随着时间的推移,在听觉处理过程中,大脑在产生词汇访问之前,如何通过不同的预测机制(无论是适应机制还是长期记忆激活机制)分析词汇重音信息。 之前的MMN研究表明词汇重音对词汇获取的贡献(Zora et al., 2015;Zora等人,2016a),但有必要进一步研究以更好地理解MMN反应如何转化为不仅涉及词汇重音加工而且涉及词汇获取的预测过程。此外,缺少对MMN成分和其他ERP成分(P50和N100)之间相互作用的直接调查,这些成分表明了预测过程。
材料设计: 考虑到在词汇加工( Bond and Small , 1983 ; Cooper et al , 2002 ;卡特勒, 1986)中音段信息可能大于韵律信息,实验材料由音段相同但韵律不同的词汇组成,其中重音在第一或第二个音节上的位置导致不同的词汇语义。为了确定词汇语义的存在是否调节P50/N100复合体和MMN分量的振幅,区分词汇加工和一般听觉加工是必要的,为此将真词与物理匹配的假单词进行比较。
本研究期望看到: 1,ERP调节与P50/ N100复合体和MMN成分在单词和假词中的韵律变化相关,但具有不同的形态和幅度,表明韵律和语义熟悉在这一过程中的作用以及不同的潜在机制。 2,考虑到韵律和语义之间存在关联,假设真词的韵律变化比没有这种关联的假词有更弱的P50 / N100反应,这表明真词重音模式的变化在听觉加工的早期阶段比假词更受期待。 3,为排除抽象韵律规则的调节(不仅编码在真词水平,而且编码在假词水平),因此在后期阶段,MMN的诱发有望表明韵律信息的长时记忆表征在有意义和无意义项目加工中的影响。
方法与设计 ¶
被试: ¶
30名荷兰语使用者(15名男性,15名女性;年龄18 ~ 32岁,M = 23.7, SD = 3.33)参加实验。有利手,视力、听力和语言发育正常。最终28名参与者(年龄18-32岁,M = 23.8, SD = 3.30)的数据被纳入分析。
刺激记录和操作: ¶
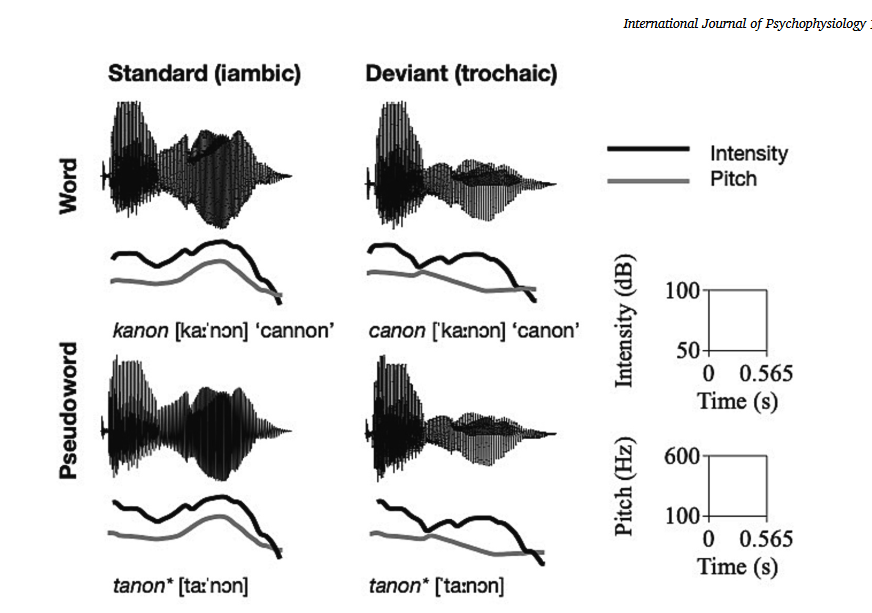
实验材料是一个单语素双音节荷兰语最小对:canon [′kaːnɔn] vs kanon [kaː′nɔn],其中词汇重音模式(分别是扬抑格和抑扬格)编码不同的语言意义,分别是“canon”和“cannon”。为了分离与感兴趣的ERP成分相关的活动,使用声学匹配的假词[′taːnɔn]vs [taː′nɔn]作为对照。 录音使用Audacity软件在配备声音验证室的房间中进行,速率为44.1 kHz,16 bits/per sample。每个刺激都是由一名母语为荷兰语的女性在语义中立的框架句子中重复产生的,以自然的节奏用中性的韵律说出每个句子。从声学分析的120个实例(60个单词和60个伪单词)中,选择每种刺激类型的最佳范例,从框架句子中提取,并在Praat中进行处理。
对刺激的最初听觉和视觉分析需要对音高和强度参数进行一些调整: 最小和最大f0值被调整为100 - 600hz,每个刺激平均强度调整为70 dB SPL。
为了消除虚假的点击clicks?在刺激的开始和结束时增加了5毫秒的斜坡。利用波形和宽频 带谱图的周期性,从每种刺激类型中提取音节。每个音节在最近的零交叉处(起始/偏移)被切断并单独保存。
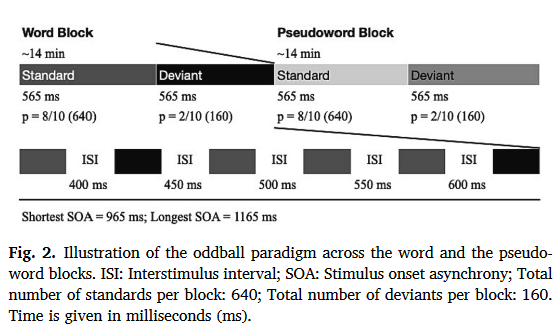
实验设计: ¶
实验范式为被动听觉oddball范式,将频繁(p = 8/10)的标准刺激随机替换为罕见(p = 2/10)的异常刺激(见图2)。
结果: ¶
图3显示了Word和Pseudoword块上Fz、FCz和Cz电极位置的标准和偏差引起的ERP总平均波形。
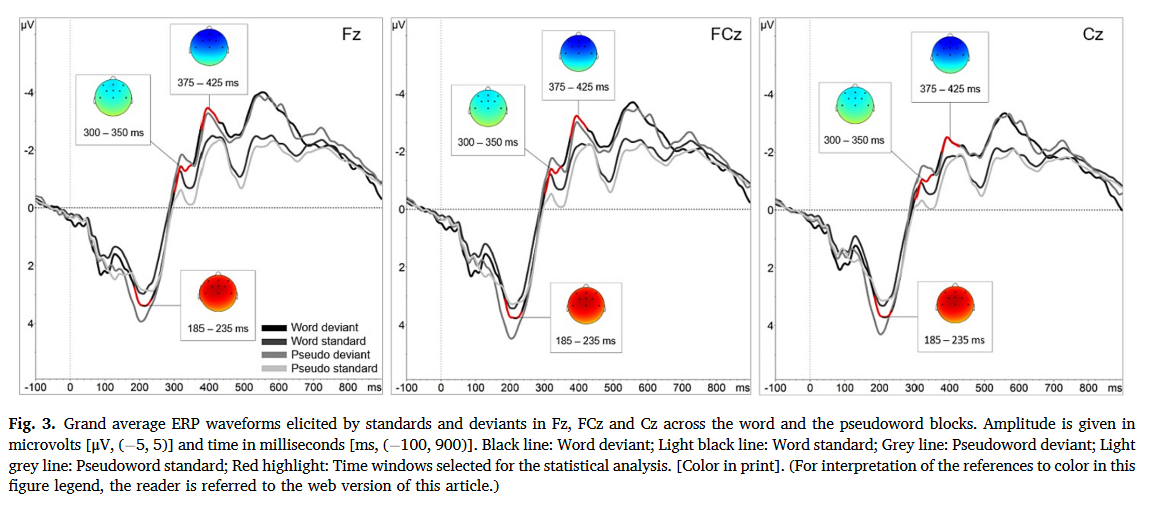
表1给出了统计结果的概述:
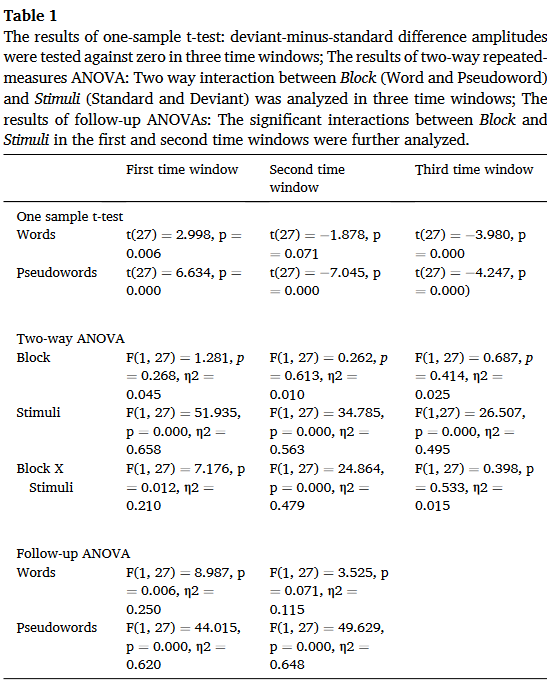
在第二个时间窗口中,假词的ERP反应不同于0(t(27) = 7.045, p = 0.000),真词的ERP反应和0无显著差异(t(27) = 1.878, p = 0.071)。ANOVA结果显示,Block与Stimuli在第一个时间窗和第二个时间窗存在显著的双向交互作用。在第三个时间窗口仅发现刺激主效应。
第一个时间窗口的后续方差分析表明,标准刺激和异常刺激在真词和假词上存在显著差异。使用偏差最小标准数据deviantminus-standard data进行配对样本t检验,发现真词和假词之间存在显著差异( t ( 27 ) = 2.679,p = 0.012 )。这种假词的正性增强对应于P50的反应,表明假词的韵律变化比单词的韵律变化更出乎意料。
第二个时间窗的随访方差分析显示,标准刺激和异常刺激在假词上存在显著差异,p = 0.000;在真词上的差异无统计学意义,p = 0.071。使用偏差最小标准数据deviantminus-standard data进行配对样本t检验,在第二个时间窗中,真词与假词之间存在显著差异(t(27) = 4.986, p = 0.000)。这种负性反应与N100反应一致,并且由于被还原为单词,它索引了已经被编码在单词中的韵律信息的抑制。
第三时间窗的主效应表明,无论在哪个时段,异常刺激都比标准刺激引起更大的负性反应。这种负反应在真词和假词中都存在,MMN反应最好地证明了这一点,并证明了与抽象韵律规律相关的长期记忆痕迹的激活。
结论: ¶
本研究表明,根据听觉输入是否映射到现有的词汇项目,无论是语言特征(和认知机制)还是声学参数(和感觉机制),都具有重要的相关性(参见博恩克塞尔- Schlesewsky和Schlesewsky , 2019)。大脑并不是简单地对声学环境的变化做出反应,如基频和强度偏差,而且在很大程度上根据先前建立的表征对其进行评估。这种过渡过程可以通过P50/N100和MMN组件成功验证。
认知神经科学关于文字处理的普遍观点认为,在感官输入后需要数百毫秒才能解释有意义的语言信息,这一观点似乎应该重新审视。本研究结果表明,语言韵律信息可以在50毫秒内按重要性进行加权(另见Shtyrov和Lenzen, 2017)。
与之前的研究结果一致,本研究表明,在词汇获取过程中,神经回路依赖于现在和过去的预测,并且预测和整合功能的结合是语音有意义表征所必需的。