文献:Heilbron, M., Armeni, K., Schoffelen, J., Hagoort, P., & De Lange, F. P. (2022). A hierarchy of linguistic predictions during natural language comprehension. Proceedings of the National Academy of Sciences, 119(32). https://doi.org/10.1073/pnas.2201968119
研究背景: ¶
理解口语需要将音流转换成从音素到意义的层级表示。有人提出,大脑不断地产生预测,以指导信息处理。在语言理解过程中,确实观察到了这样的预测,但对于这些预测还存在一些问题:1,预测在语言处理中是普遍存在的吗?2,语言预测主要发生在句法层面,还是词汇层面、语义层面或音系层面? 预测是否局限于给定水平内的增量、预期处理,还是扩展到跨水平的自上而下的预测?
事件相关电位(ERP)研究描述了大脑对违反或偏离高、低预期的反应,表明预测可能同时发生在所有水平。但这些发现是否可以推广到自然语言中一直存在争议,因为在自然语言中很少或不存在违反规则的情况,而且几乎没有高度可预测的单词。在这些情况下,预测可能不太相关,或者可能仅限于最抽象的水平。另一方面,对自然理解的研究发现,神经对各种语言意外度量的敏感性表明,预测实际上可以推广到自然语言中。然而,这些研究通常只关注一个或两个层面的分析——如,语音、单词或语法。这就留下了一个悬而未决的问题,即不同层次的指标是否为单个潜在过程提供了不同的有利位置,或者预测是否同时发生在多个层次上——如果是这样,不同层次的预测是否会相互作用。此外,目前尚不清楚这种整体可预测性效应是否真的反映了连续预测,还是由自然刺激中的一部分(高度可预测的)事件驱动的。
本文中研究者通过分析参与者听有声读物的大脑录音,并使用深度神经网络来量化故事引发的预测,来解决以上的问题。
材料和方法: ¶
两个实验的脑电和定位脑磁图数据
参与者: ¶
英语母语者;EEG实验,19名受试者(13名男性);MEG实验,3名受试者(2名男性)。
刺激和程序: ¶
在这两个实验中,参与者都被呈现了从有声读物中提取的连续的叙述性言语片段。EEG实验使用了海明威的《老人与海》的录音。MEG实验使用了亚瑟·柯南·道尔的《福尔摩斯历险记》中的10个故事。排除间歇,脑电受试者听1小时的讲话(约11,000个单词和35,000个音素);脑磁受试者听9小时(不包括间歇)的讲话(包含约85,000个单词和29,000个音素)。 在EEG实验中,每个参与者只进行一次单独的会话,其中包括20次180秒的运行。 参与者被要求保持固定并尽量减少运动,除此之外不参与任何任务。 在MEG实验中,每个参与者共进行10个会话,每个会话1小时。每个会话被细分为6或7次,每次10分钟左右。MEG数据集的参与者要认真倾听,并必须在中间回答问题:一个多项选择理解问题,一个关于故事欣赏的问题,以及一个关于信息量的问题。
结果: ¶
参考两个独立实验的数据,在这两个实验中,当参与者听有声读物中的自然语言时,记录了他们的大脑活动。第一个实验是公开可用数据集(36)的一部分,包含19名参与者1小时的脑电图(EEG)记录。第二个实验收集了三个个体9小时的脑磁图(MEG)数据,使用个性化的头部模型能够高精度地定位神经活动。如图1
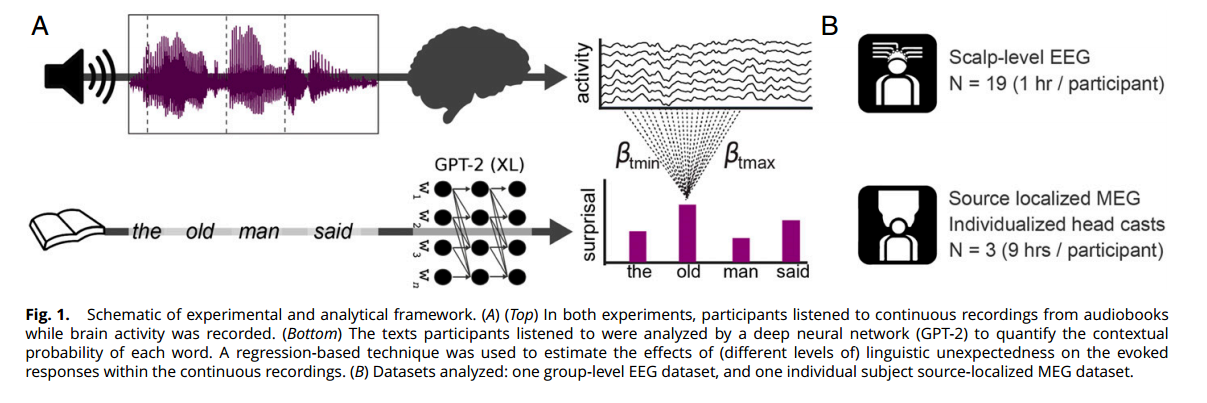
一,神经系统对言语的反应是由连续调节的语言的预测: ¶
如果大脑不断预测即将到来的语言,那么对单词的神经反应应该对违反上下文预测的行为敏感,从而产生“预测错误”信号,这是预测处理的标志。为此使用了反卷积技术(回归ERP)来估计预测误差对连续记录中诱发反应的影响,并专注于低频诱发反应(它与早期关于语言预测的神经特征的研究最直接相关)。为了量化语言预测,研究使用深度神经语言模型GPT-2分析参与者所听的书籍。(GPT-2是一个基于转换器的大型模型,可以根据前面的单词预测下一个单词,目前是同类中最好的公开模型之一。GPT-2只纯粹作为量化每个单词在上下文中的预期程度的工具。)
为了测试对单词的神经反应是否受到上下文预测的调节,研究者比较了三种回归模型。1,基线模型假设:自然的、被动的语言理解不需要预测。该模型不包括与上下文预测相关的回归变量,但确实包括潜在的混淆变量(如频率、语义整合难度和声学)。 2,约束猜测模型假设:在理解过程中,预测不是不断生成的,而是在约束上下文中对单词的子集生成的;这些预测要么全有,要么没有。(使用来自基线模型的所有回归量,加上一个意外回归量,将它们实现为回归模型。这个意外回归因子只包含在最具限制性的上下文中的单词子集;使用了单词非概率性的线性度量,因为全或无的预测结果是单词概率和大脑反应之间的线性关系。) 3,连续预测模型假设:大脑不断产生概率预测,对刺激的反应与它的负对数概率成正比。该模型包括基线模型中的所有回归量,以及有声书中每个单词的单词不可能性(surprisal)的对数度量。
使用交叉验证比较以上模型预测大脑活动的能力,发现连续预测模型比其他两个模型都更好(图2a)。
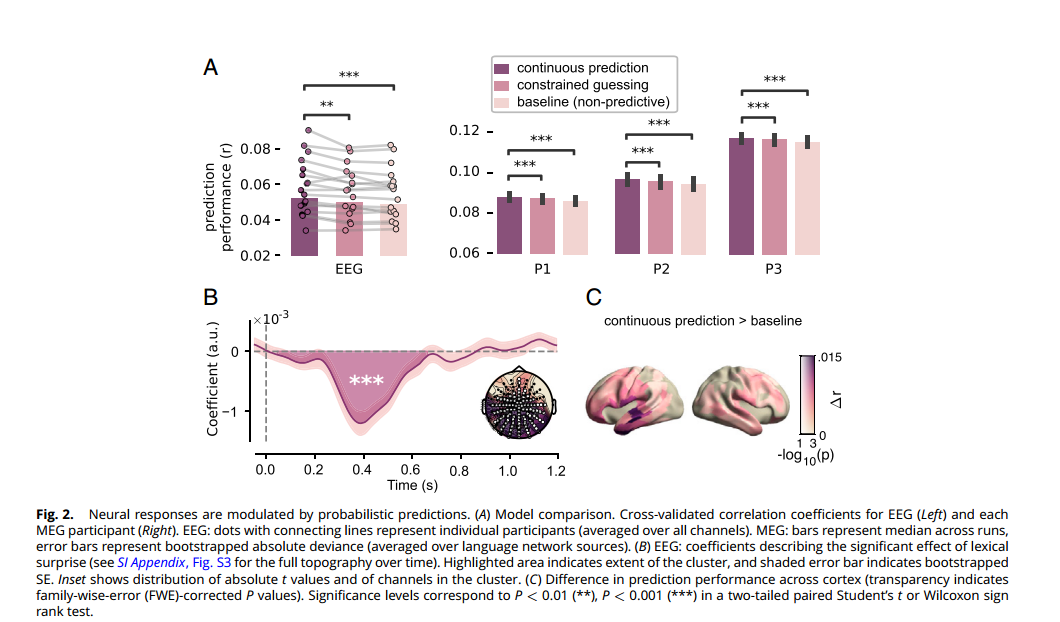
这些结果证实了大脑对单词的反应受到预测的影响,从而为预测处理提供了明确的证据。这些调整并不局限于受限的语境,发生在整个语言网络中,唤起一种让人想起N400的效果。
二,语言预测是特定于特征的: ¶
研究者将人工神经网络中汇总的词级语言预测分解为不同的语言维度(图3)。
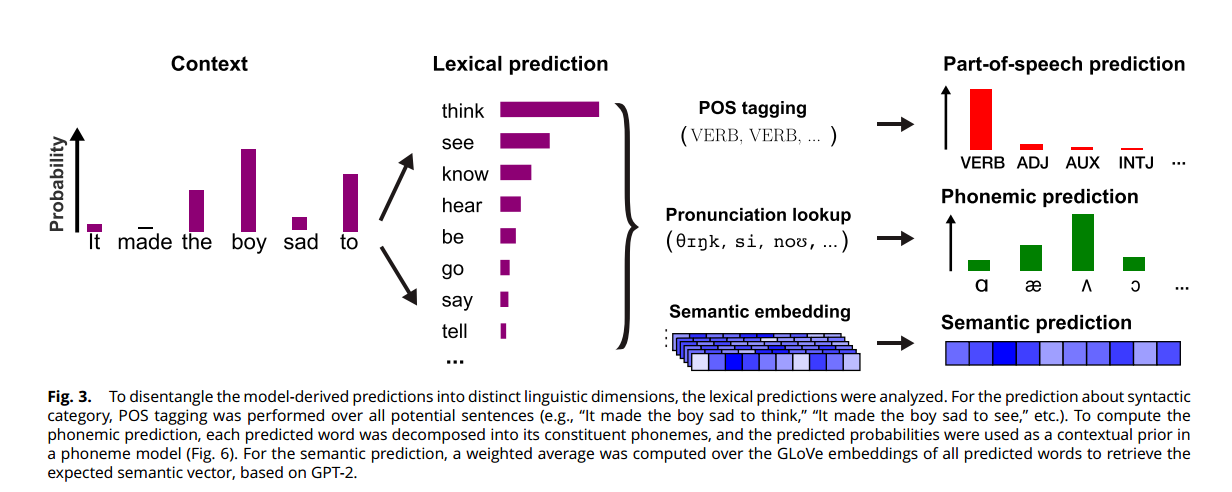
研究者首先询问每个预测错误回归模型是否解释了其他回归模型无法解释的独特方差,并利用MEG数据确定其在哪个脑区。作为对照,首先对一组有已知源的回归模型(声学特征)进行了分析。结果显示在听觉皮层周围存在一个峰值,与早期研究一致,证实了该方法可以定位对给定回归器敏感的区域。然后测试了三个预测错误的回归模型,发现每个回归模型在每个个体中解释了显著的额外方差(图4)。
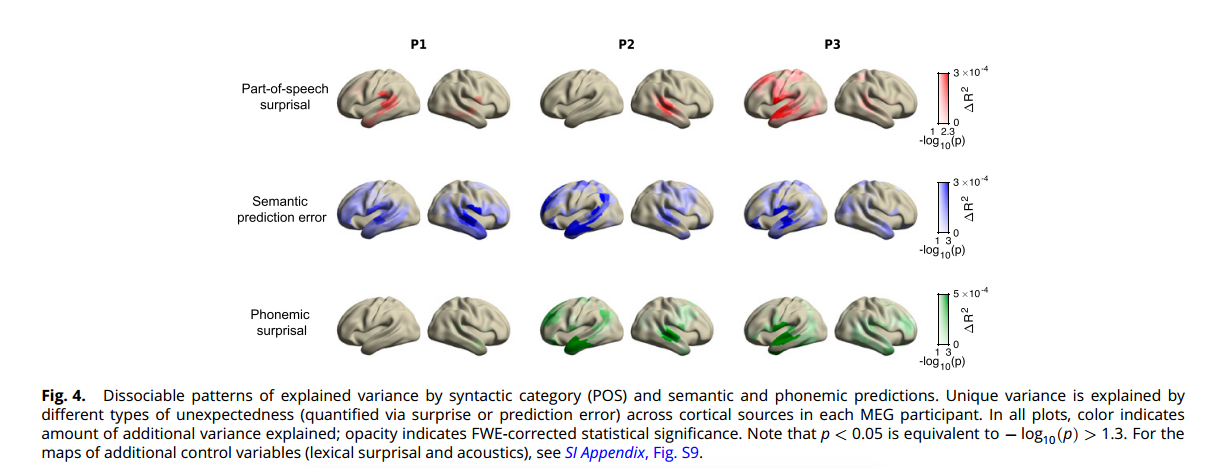
虽然不同个体之间的侧化和确切空间位置存在差异,但总体的源模式与先前关于每个层次的神经回路的研究结果相符。研究观察到对语义预测错误响应的广泛区域与语义系统广泛分布的观察结果一致,而对于音素和词性意外性则发现了更具局部性和时间性的区域,这些区域已知是句法处理的关键区域以及语音感知和听觉词认知的关键区域 。
综上所述,大脑对不同类型的语言意外有不同的反应,表明语言预测可能是特征特异性的,并且在多个层次上发生。
三,不同级别的预测的可分离的时空特征: ¶
为进一步探究不同类型的预测错误对神经响应的影响,研究使用了脑电图(EEG)和脑磁图(MEG)数据,并观察到以下结果(如图5):
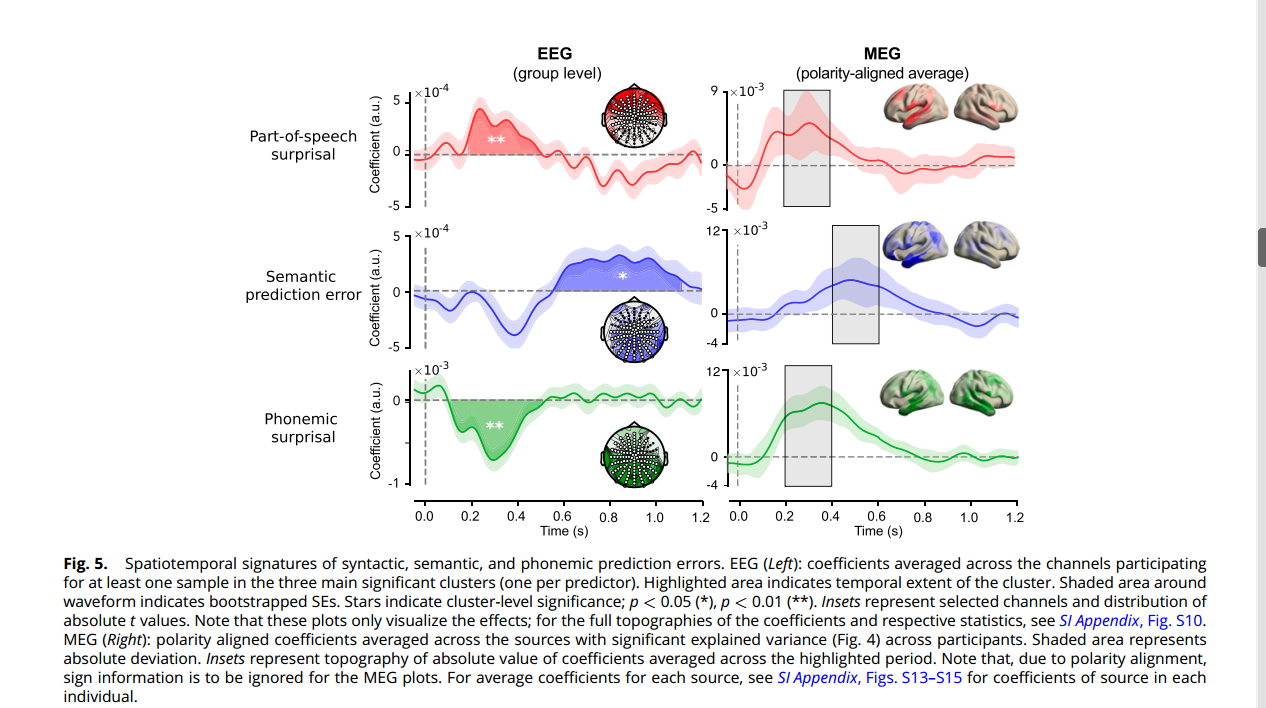
2,语义预测错误引发了较晚的正向反应,出现在600毫秒到1,100毫秒之间,并在大范围的脑区分布。这种效应类似于语义异常情况下观察到的后N400正性反应(PNP),但具体效应并不显著。
3,音素预测错误引发了较早的负向反应,出现在100毫秒到500毫秒之间,并在分布广泛的脑区形成。这种效应类似于音素不匹配负性成分(PMN)的观察结果。
4, MEG数据分析结果与EEG结果相似,尽管在个体之间存在一定的时间和形状的变异。
研究结果表明,不同类型的语言预测错误引发了具有时间和空间差异的大脑响应。词性和音素预测错误调节了较早的神经响应,而语义预测错误调节了较晚的神经响应。这表明语言预测不仅存在于单一的系统中,而是涉及整个言语和语言网络,并形成了一个层次结构,跨越各个分析层次。研究还通过简化回归分析确认了这些结果是独立的效应。
四,音素预测揭示了等级推理: ¶
关于不同层次的预测是否会相互作用,一种假设是它们彼此独立,独立系统中的预测可能使用不同的信息。或者不同层次的预测可能会相互通知和约束,有效地汇聚成一个多层次的预测。对此,可通过评估不同的音素预测方案来探究。
预测方案一:预测仅基于在短时间尺度上展开的信息。在这种方案中,下一个音素的预测概率是从与迄今为止的音素兼容的词集中推导出来的,每个候选词根据其出现频率加权(图6A)。因此,这种方案涉及一个单层模型:预测仅基于一个层次的信息,即短序列的词内音素序列,再加上一个固定的先验(语言中的词频)。 预测方案二:音素预测不仅基于词内音素序列,还基于更长的语言上下文。在这种情况下,下一个音素的概率仍然是从与迄今为止呈现的音素兼容的词集中推导出来的,但现在每个候选词根据其语境概率加权(图6A)。这种模型具有层次结构,即预测既基于第一层的短音素序列(即几百毫秒长),又基于上一层的语境先验,该语境先验本身基于长时间的词序列(即几十秒到几分钟长)。
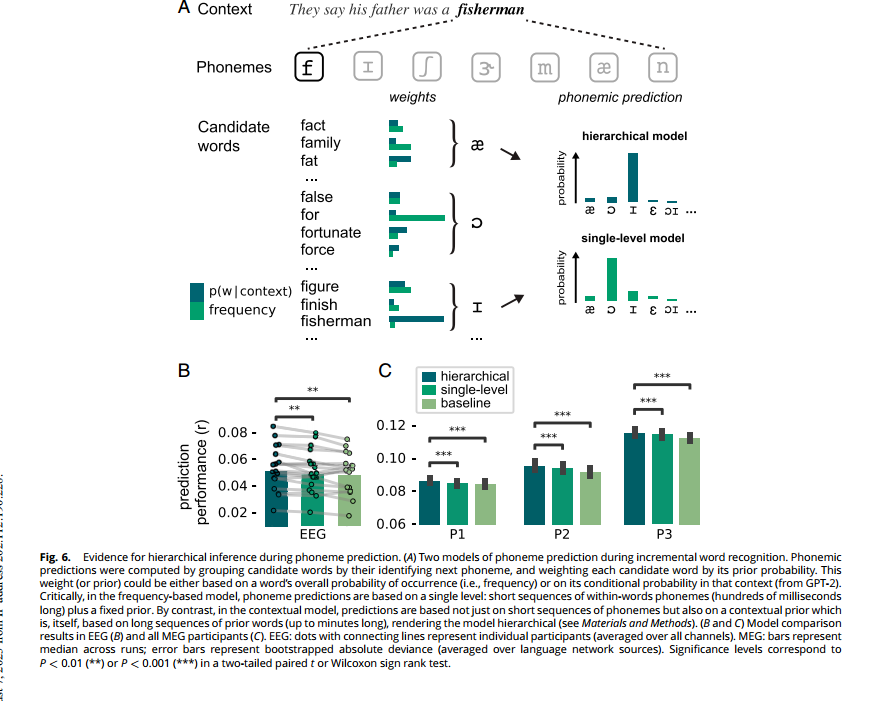
当我们比较交叉验证的预测性能时,首先发现在两个数据集中,预测模型的表现显著优于非预测性基线模型(图6B和C)。当比较这两个预测模型时,发现层次模型的表现显著更好,无论是在EEG还是MEG。这表明,基于短音素序列的神经预测受到词汇预测的影响,有效地将先前的长序列词作为上下文加以整合。这是层次预测的特征,支持层次预测处理的理论。