文献:Kulke, L., Wübker, M., & Rakoczy, H. (2019). Is implicit Theory of Mind real but hard to detect? Testing adults with different stimulus materials. Royal Society Open Science, 6(7), 190068. https://doi.org/10.1098/rsos.190068 论文原文
研究背景: ¶
心智理论(Theory of Mind, ToM),将心理状态归因于他人的能力,各种隐性测量表明,即使是婴儿也具有基本的ToM能力,并且这些能力的自动、自发和无意识的使用在整个生命周期中都保持着运作。这些措施包括违反期望观看时间范式、互动行为任务、启动和预期观看措施。后者在整个生命周期中使用最为广泛,跨物种,以及跨典型和非典型种群。这些发现极大地影响了该领域,并被视为深远的理论结论的证据基础。 先天论认为,这些新的隐性任务以最纯粹的形式挖掘了真实的、可能是模块化的、天生的核心ToM能力。而传统的言语研究低估并掩盖了由语言、工作记忆和任务的其他要求构成的外在表现因素所导致的早期概念能力。 ToM的两系统理论认为内隐任务利用了一个更基本的、进化上和本体上更古老的读心术系统Ⅰ,它在许多关键方面不同于后来发展的系统II,即完全成熟的,明确的和有意识的读心术。这两种理论都同意,新的隐性任务的发现证明了一些早期的读心能力,但也有人认为早期内隐ToM任务的发现可以更简洁地解释为“次心智化”的产物,即感觉和注意力过程。 在很大程度上,争论围绕着如何在内隐任务构成稳健效应的前提下解释其发现的问题。然而,这个前提本身最近受到了争议—内隐任务的结果难以复制。 复制研究失败的原因有几种可能: 首先,非复制可能反映了真正的否定,这表明不存在强大的内隐ToM。 其次,它们可能反映假阴性,即隐性ToM是真实的,但难以挖掘;而当前的范例可能不够敏感,无法测量隐含的ToM。 此外,原始研究和重复研究中高达30%失样率使得现有研究的结果难以解释。
因此,本研究的基本原理是对现有的预期性视觉任务进行概念性重复,重点关注刺激的潜在影响。因此,本研究所使用的任务在结构上类似于Southgate等人和Surian & Geraci使用的任务,但具有更吸引人的刺激。关键的问题是,这些经过修改的刺激是否能减少退出,并更敏感地揭示成年人的自动信念跟踪。研究试图通过消除潜在的混淆来增加先前范式的可靠性。 两项研究实施了位置变化错误信念(FB)场景,并在综合设计中结合了先前使用的两类任务的概念重复: 转移任务是显性标准 FB任务的隐式改编:一个行为人将一个物体放入盒子1,然后被转移到盒子2,由行为人见证(真实信念,TB条件)或未见证(FB条件),然后行为人开始行动以获得该物体。 移除任务是将目标物体从场景中移除从而抑制寻找物体的真实位置:智能体将物体放入盒子1。然后物体被转移到盒子2,最后从场景中移除。在这两种情况下,agent见证了步骤1和步骤2,因此相信该物体在盒子2中(FB1条件),或只见证了步骤1,因此相信该对象在盒子1中(FB2条件)。除了最初的移除试验(FB1和FB2)之外,还引入了一个新的条件来控制参与者追踪最后的物体位置而非代理人信念。在新的真信念条件(TB1)中,agent观察了整个过程(物体的移动和移除),因此知道物体已经从场景中移除(图1)。如果参与者在这个条件下仍然以与FB1相同的方式看最后一个物体的位置,这将表明他们可能跟踪物体的最后位置定位,而不是预测在两种情况下agent将到达的物体。
Study1: ¶
被试: ¶
N=125(移除任务三种条件(fb1/fb2/tb1)和转移任务两种条件(fb/tb)下:n=25)。 为了达到所需的受试者数量,217名成年人接受了测试(年龄范围为18-34岁,男性22.9岁,S.D.。£2.9,127名女性),在戈廷根大学校园招聘。 其中一个纳入标准是在熟悉试验中被试有没有看正确的任何感兴趣区域(AOI)。所有参与者的视力正常或矫正到正常。试验记录被试的眼动情况,参与者被伪随机分配到其中一种条件(FB1、FB2、Tb1、Fb或Tb)。具体如图所示:

刺激: ¶
Study1的刺激尽可能接近于Southgate/Senju范式中使用的原始刺激。原始刺激包括熟悉性试验,然后是测试试验(FB1或FB2)。Southgate/Senju模式对所有试验都使用相同的基本设置——一个戴着面罩的女演员站在白色面板后面。面板上设置了两个窗户,每个窗户前面都有一个不透明的盒子。参与者会看到一只木偶熊在舞台上移动一个色彩鲜艳的球。特工目击了木偶熊的行为,直到她被电话铃声分散了注意力。电话停了之后,女演员转过身来。为了引起对行为人从其中一个盒子中取出球的预期反应,行为人转身后,两个窗户会亮一秒钟,并伴有钟声。在之前的实验中,参与者已经熟悉了这些线索,在750毫秒的延迟后,参与者会在视觉和听觉信号之后,穿过其中的一个窗口去抓玩具。为了增加视频中显示的动作的相关性,用巧克力代替球,并在一个简短的介绍性视频片段中向agent强调了它的重要性:当agent享受巧克力时,出现一只木偶熊。在发现巧克力没有了之后,agent把一个空袋子送给了木偶熊,并表达了她的不满。木偶熊似乎有了主意,离开了现场。

分析: ¶
对于移除条件(FB1、FB2、TB1),对两个AOI的预期注视反应进行了编码:“box1”AOI包括对应于box1的窗口,而“box2”AOI包括对应于box2的窗口。 在FB1中,box2对应于信念一致的位置和物体在移除之前的最后位置。 在FB2中,box1对应于信念一致的位置,而box2对应于最后的物体位置。 在TB1中没有信念一致的位置,box2对应于最后的物体位置。
使用了两种预期性注视的测量方法,即窗户照射后第一次扫视的方向和从窗户照射开始的6-S时间段内的注视持续时间。 为了分析对两个aoi的观察时间是否存在随机差异,以及不同条件下的差异,计算了差别注视分数(DLS):对于FB1和FB2, DLS的计算方法是将对信念不一致窗口的观察时间减去对信念一致窗口的观察时间除以对两个窗口的观察时间之和:
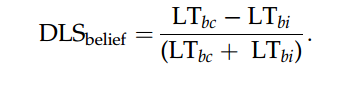
为了控制仅仅看最后一个物体位置的低级解释,比较了FB1和TB1。为此,计算了查找与最后一个对象位置(box2)对应的AOI的DLS,以及查找两个位置的总体DLS:
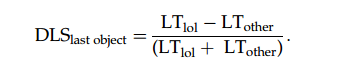
结果: ¶
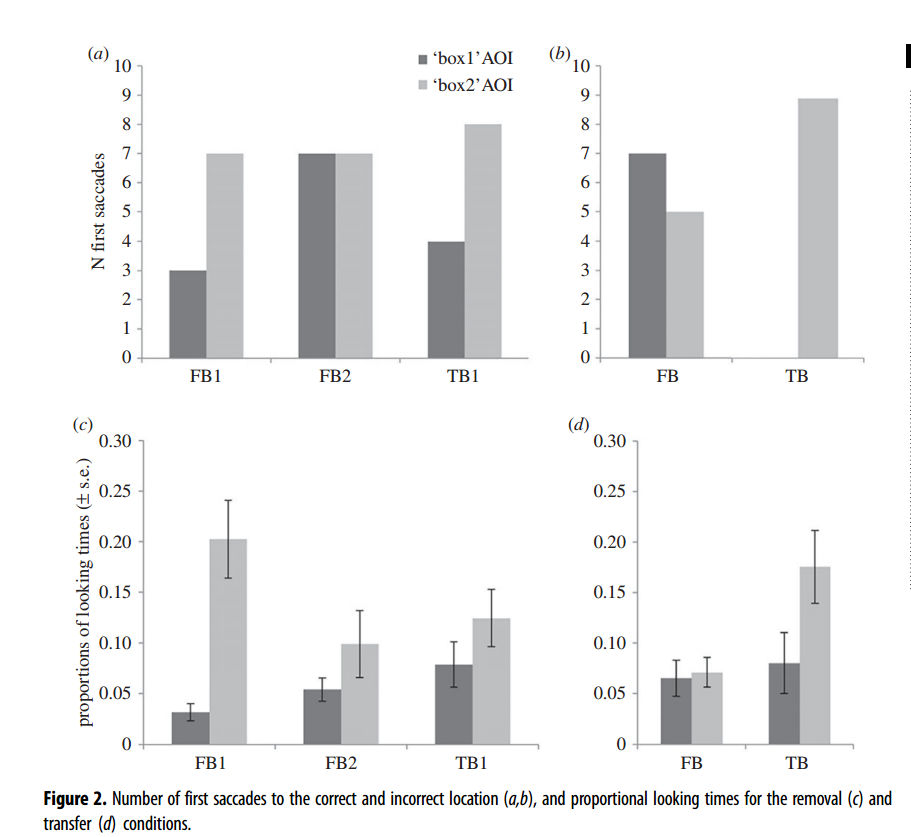
移除任务: ¶
第一次扫视:在所有移除条件(FB1、FB2和Tb1)中,参与者随机地将他们的第一次扫视指向两个窗口,它们的对比没有显著差别。
Dls: fb1与fb2:在移除条件下,受试者对FB1中的信念一致窗口的注视时间明显更长。在FB2中,参与者注视窗口的持续时间在信念一致窗口和不一致窗口之间没有差异。与FB2相比,在FB1条件下,参与者花在寻找信念一致窗口上的时间比例明显更高。
FB1与TB1:在Tb1中,参与者的注视持续时间在两个窗口之间没有差异。Fb1和Tb1的比较显示,在FB1条件下,参与者看向与最后一个物体位置相对应的窗口的时间比例明显高于TB1条件下。
转移任务: ¶
为了对转移条件Tb和Fb进行探索性分析,计算了重复测量的一般线性模型,以考察条件(Fb或Tb)、AOI(box1与box2)和交互作用项对观看时间比例的影响(非预先登记)。AOI有显著的影响。 第一次扫视: 在TB条件下,所有进行扫视的参与者都将他们的第一次扫视指向信念一致窗口(p=0.004)。在TB条件下,参与者将第一跳指向信念一致窗口的比例显著高于FB条件(p=0.007)。
讨论: ¶
在移除任务中,结果混合且不确定的。FB1被部分复制,但FB2没有。在FB1中的发现不能简化为单纯的球追踪,因为受试者在TB1中并没有像在FB1中一样关注最后一个球的位置。在转移任务中,参与者只在TB中表现出更明显的寻找信念一致的位置,而在FB中则没有。但在FB和TB条件之间,寻找物体和空位置没有显着的相互作用,这表明没有证据表明TB的模式与FB的模式不同。此外,在最后一次熟悉试验中,由于参与者没有表现出目标跟踪而导致的失样率很高,即该任务可能没有充分吸引参与者。
Study2 ¶
研究2的目的是创造更真实的刺激,使用与Krupenye等人使用的类似的逼真和情绪化的追逐场景。
被试: ¶
N=125(移除任务三种条件(fb1/fb2/tb1)和转移任务两种条件(fb/tb)下:n=25)。 为了达到所需的受试者数量,345名成年人接受了测试(年龄范围为18-34岁,男性22.9岁,S.D.。£2.9,127名女性),在戈廷根大学校园招聘。 其中一个纳入标准是在熟悉试验中被试有没有看正确的任何感兴趣区域(AOI)。所有参与者的视力正常或矫正到正常。试验记录被试的眼动情况,参与者被伪随机分配到其中一种条件(FB1、FB2、Tb1、Fb或Tb)。具体如图所示。

刺激: ¶
与研究1类似,用巧克力棒代替简单的球。agent没有戴遮阳帽,她的眼睛是完全可见的,与清晰的面部表情一起增强她作为agent的功能。引入第二个女演员代替木偶熊使刺激更真实。在原始刺激条件下,在信念诱导阶段,agent转过身去听电话铃声。但转头和电话铃声可能会分散参与者的注意力,并可能为所谓的自动信念处理的发现描述另一种解释,代理的缺席和在场被用作信念诱导变量。与研究1一样,纳入了TB1、TB和FB三种附加条件。 所有视频的一般刺激设置都是一样的: agent(一个女演员)站在两个不透明盒子之间的灰色窗帘前。在每次试验开始时,第二个女演员从前景出现,并将巧克力棒放在其中一个盒子里(见图5)。

分析: ¶
与研究1一样,第一次扫视和DLS被用来衡量参与者的预期注视,进一步分析了转移条件(Tb和Fb)与观看时间的比例(探索性分析)。参与者对外显控制问题的回答被编码为与代理人的信念不一致或一致。
结果: ¶
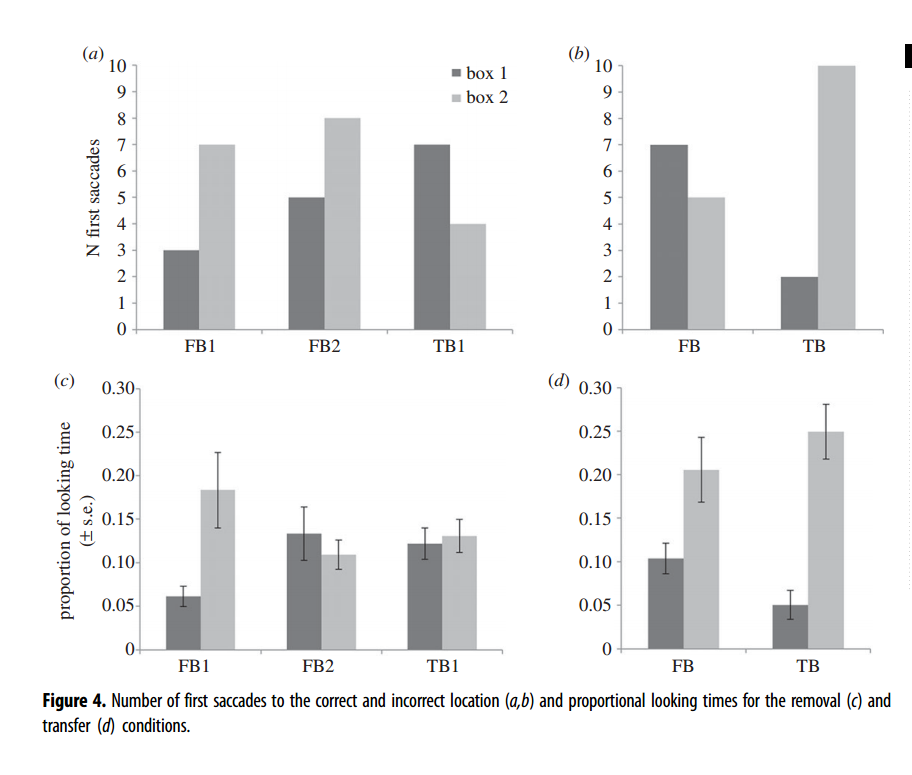
移除任务: ¶
第一次扫视: 在所有移除任务(FB1、FB2、Tb1)中,不同条件之间没有显著差异。 DLS: 在所有移除任务下,参与者通过DLS测量的注视盒子的持续时间在不同的盒子之间没有差异,参与者的表现在移除任务的条件之间没有显著差异。
失样率: 为了分析失样率,只考虑了在上次熟悉试验中因未通过 Southgate/Senju最初的正确预期标准而被排除在外的参与者人数和纳入的参与者人数。目前的辍学率与以前的研究报告有很大不同。虽然未通过纳入标准的参与者的百分比低于 Southgate等人的范例,但与Senju等人报告的辍学率相比,这一百分比有所增加。
转移任务: ¶
观看时间的比例:计算AOI(box1或box2)、条件(TB或FB)及其交互作用对观看时间比例的影响的混合ANOVA(重复测量一般线性模型)显示显著的AOI,但没有显著的交互作用,条件无主效应。 第一次扫视:在TB条件下,参与者对信念一致框的第一次扫视显著多于对另一个框的扫视(p=0.039)。 两项研究中的DLS分析: 在研究1和研究2中,DLS在TB条件下显著为正,但在FB2条件和FB条件下与零没有显著差异。在FB1条件下,结合DLS现在显著为正,这在之前的研究1中有发现,但在研究2中并未发现。此外,在TB1条件下,现在有一个边缘显著的效应,而在之前的任何一项研究中都没有显著效应。
讨论: ¶
该研究的主要目的是采用更具吸引力的刺激,通过更好的控制程序来概念性地复制预期性注视ToM测量,并排除先前的混淆因素和排除替代解释。
总的来说,只有那些信念一致的位置与(最后的)物体位置相同的条件才能被复制。而这些条件最容易受到替代解释的影响。当前的部分/非复制结果与越来越多的内隐ToM任务的非复制结果一致。特别是,它与其他最近的结果一致,这些结果只在那些容易受到替代解释影响的条件中发现了与信念处理一致的注视行为。但与以前的复制失败相比,当前的复制结果略有改善,即在FB2条件下预期性注视处于随机状态,而不是显著更频繁地指向与信念不一致(即物体)的位置。这与研究1中的新控制条件TB1的结果一起表明,参与者并不是简单而不加区分地看最后的物体位置。 因此,当前的结果可能是首次表明,对于人类来说,更具吸引力的刺激可能更敏感地揭示自动信念跟踪。然而,潜在的效应明显非常小,需要进行更系统的未来研究。在研究2中,当agent在信念诱导期间消失时,实际上可能会使追踪她的视角更加困难。 还应指出,最近的研究证实,成年人能够正确地解释FB情景,例如,在违反期望任务中,这表明缺乏信念跟踪行为与缺乏技能无关,而是与任务不适合有关。具体而言,Clements和Perner的第一个预期性注视FB任务被发现是可靠的可复制的,可能是因为参与者更容易跟随。因此,任务的设计可能对于预期性注视测量起着至关重要的作用。
虽然样本量较大,但是这些研究并不能提供令人信服的证据来支持信念归因。一方面,最明确和严格的条件(FB2和FB)没有产生任何令人信服的信念归因证据。另一方面,较不严格的条件(FB1和TB)产生了一些正面的预期性注视证据,与信念跟踪一致。这些预期性注视模式本身仍然很难解释,因为条件的模糊性质,它们似乎并不仅仅反映了最后物体位置的跟踪,如新的TB1控制条件所示。参与者可能只是简单地追踪了agent知道与不知道的状态,而不是真正的信念追踪,这种过程可能比信念追踪更为简单。此外,退出率仍然很高,这可能与任务本身的不适合有关。此外,对任务的测量方式(预期性注视)的可靠性也存在问题。本研究尝试通过改进刺激材料来提高任务的吸引力,但并没有带来任何可靠的改进。总的来说,这些研究暂时无法确定人类是否具有自动的信念追踪能力,而任务本身可能存在固有的问题。
现有研究对于人类是否具有自动的信念追踪能力的结论并不确定,需要进行更多系统性的未来研究。未来的研究应该更细致地量化预期性注视行为中潜在的不同因素(信念追踪与物体追踪),并在系统的因子设计中进行研究。