文献:Wulff, D. U., & Mata, R. (2022). On the semantic representation of risk. Science Advances, 8(27). https://doi.org/10.1126/sciadv.abm1883 论文原文
研究背景: ¶
关于个体如何看待风险不同学科有不完全兼容的概念,相对较少关注这样一个事实,即风险的含义可能因不同的目标和生活经历而因人而异。 过去有几种方法可以理解与风险和风险相关结构相关的主要心理维度。其中主要的是基于调查的方法使用降维方法,根据人们对不同活动和技术在几个方面的评分(如,感知风险、感知收益和可控性)来获取不同活动和技术的维度。研究发现不同的技术风险和活动可以映射到(至少)由两个维度(恐惧和不确定性)组成的心理空间。另一种方法是绘制文本语料库中风险的语义表示,具体是将词汇来源(如字典和辞典)中最常见的定义制成表格,或绘制其他文本来源(如维基百科)中单词关联的语义网络以获得多维空间。这些基于文本的方法通常揭示了更复杂的语义表示,可能涉及数十个不同的组件或“语义域”。 以上方法仍存在限制:首先,基于调查的方法依赖于实验者产生的方面或行为,不能保证可以详尽地捕获风险语义表示的所有方面或维度。其次,词汇方法虽然更有可能识别出全方位的方面或维度,但对汇总信息的依赖不允许调查个体和群体差异在风险语义表征中的作用(一些研究结果表明,风险的语义表征在群体和个人之间是不同的)。
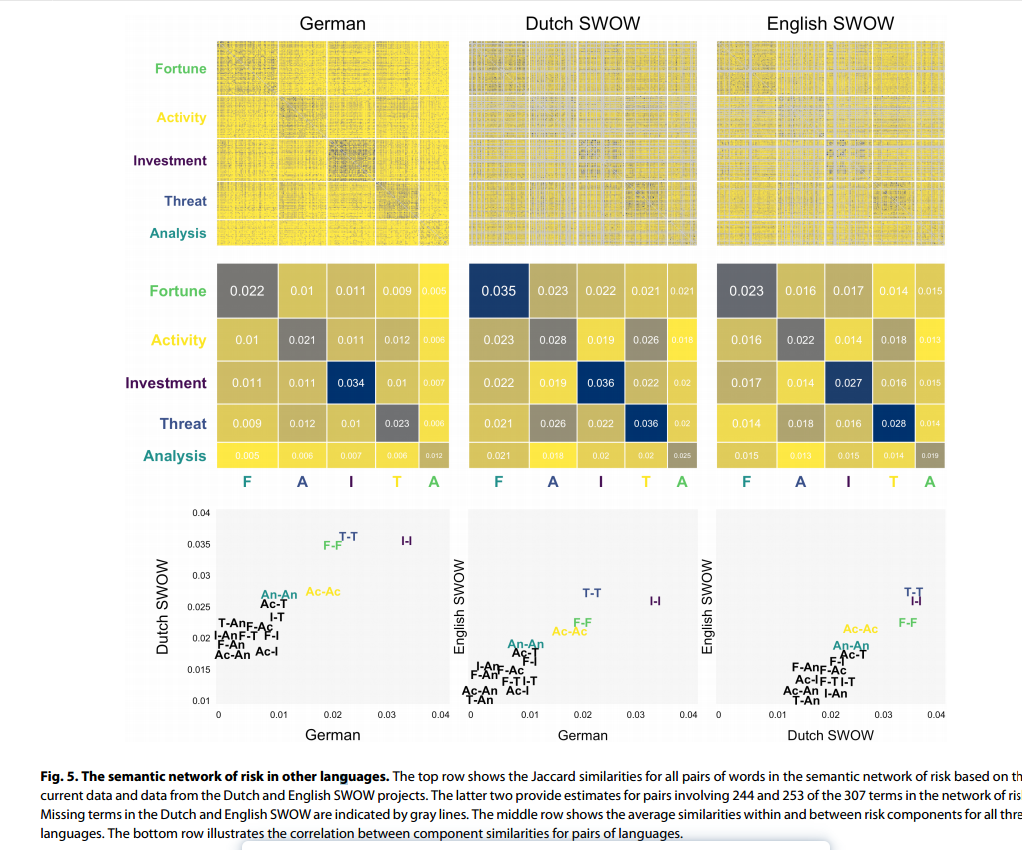
本研究回答了四个主要问题。第一个问题涉及本方法所产生的风险成分在多大程度上与过去研究中通常确定的不同维度和领域相匹配。其次,研究讨论了风险的语义表示在多大程度上跨语言一般化,因此具有一些普遍特征,可以捕捉人类思考风险的一般方式。第三,关于群体差异,本分析旨在描述风险表现的潜在年龄和性别差异,包括风险关联的类型或领域(例如,娱乐)和其他特征(例如,情绪)。过去的工作已经确定了风险相关构念中年龄和性别差异的清晰而稳健的模式,本研究通过考虑是否在风险的语义表征中直接发现类似的群体差异来扩展这一工作。第四,也是最后,研究者想知道风险语义表征的个体差异是否可以用来更好地理解和预测个体的风险承担,从而有助于评估语义表征在预测风险相关行为的个体和群体差异方面的能力。
材料和方法: ¶
受试者: ¶
共有1205名参与者(602名女性,占50%)完成了此项在线研究。参与者年龄在18 - 87岁之间,从六个年龄段(18至27岁、28至37岁、38至47岁、48至57岁、58至67岁和68岁以上)中均匀抽样,旨在代表德国人口,这项研究平均花费12分钟。
步骤: ¶
1,本研究使用迷你滚雪球-单词联想的方法来直接从个体的联想映射风险的语义表示,并评估相关的个体和群体差异。具体地说,本研究的单词联想任务要求参与者说出单词“Risk”的五个关联词,以及每个初始生成的Risk关联词的五个关联词(每个参与者总共有30个关联词)。参与者要说出在单独思考相关线索时脑海中出现的前五个单词。参与者尽可能自发地回答,以避免在回应相同的线索时重复联想,并避免用完整的句子回答。 2,情感推断是根据SentiWS词典来确定的。在一般风险网络中的307个单词中,只有115个被收录在SentiWS词典中。为了能够对最大数量的单词进行情感分析,使用第2级响应的平均情感来推断不可用的第1级情感。具体地说,当第一波词本身的情绪不可用时,情绪被定义为这个词的情绪和它的关联词的平均情绪之间的平均值,或只有后者。 3,冒险倾向使用德国社会经济小组(SOEP)的七个自我报告的风险项目来衡量。第一个问题要求参与者判断 “Are you in general a risk-seeking person or do you seek to avoid risks?” 从0分(完全不冒险)到10分(非常冒险)。之后提出了六个相同的问题并提供了相同的量表,但用六个不同的冒险领域的文本取代了“ in general”,具体包括驾驶、金融投资、休闲和体育、职业生涯、健康和信任陌生人。
结果: ¶
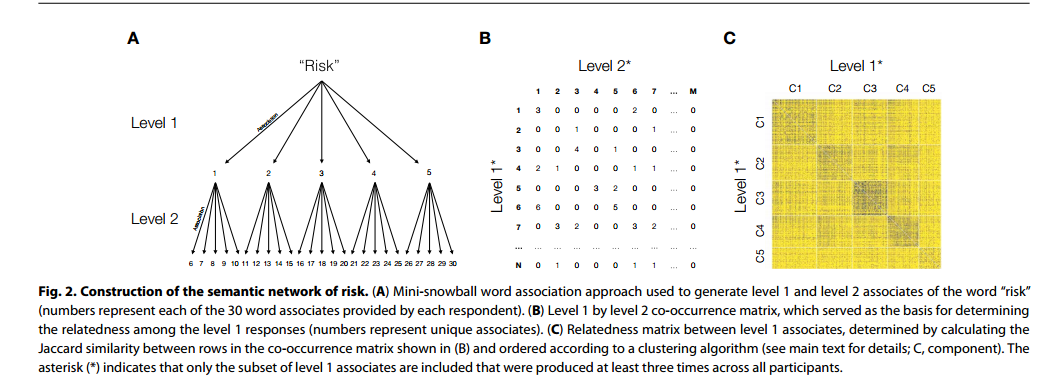
一,风险的语义网络: 研究使用参与者的数据构建一个一级关联的语义网络,并通过频率分布来表征每个一级回应所引发的二级回应。然后,通过计算一级回应之间的加权Jaccard相似度,确定一级回应之间的相关性。接下来,将一级回应的相似性矩阵表示为加权网络,并使用Louvain模块性算法提取了风险的组成成分。
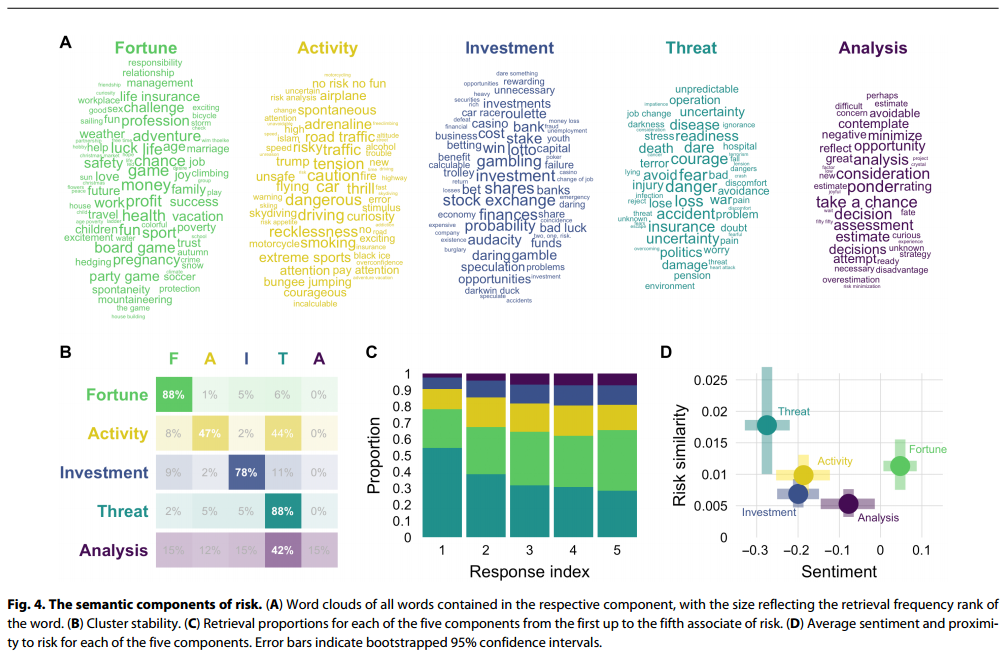
三:风险语义表征的群体差异:年龄和性别 年龄和性别对风险认知的组成部分有影响:年长者和女性相对于年轻者和男性更倾向于产生与负向风险相关的联想。在年龄方面,随着年龄增长,对Threat的关注增加,对Activity的关注减少,而对活动的关注略有增加。在性别方面,女性更关注Threat,而男性更关注Activity。而对于风险的常见关键词,如危险和恐惧,年龄和性别影响较小,表明风险的基本概念相对稳定。
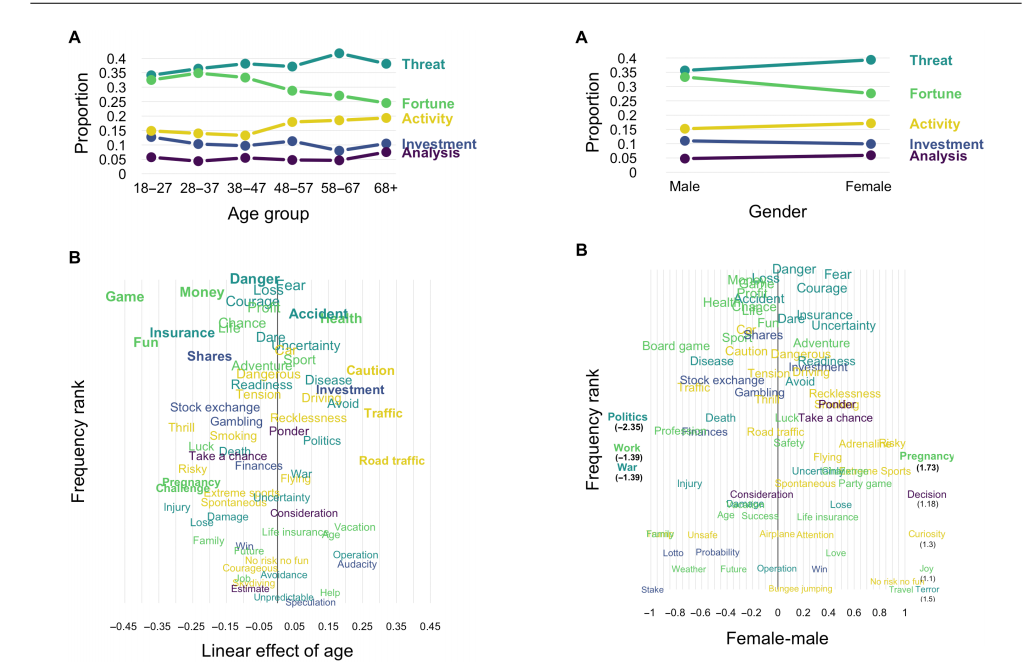
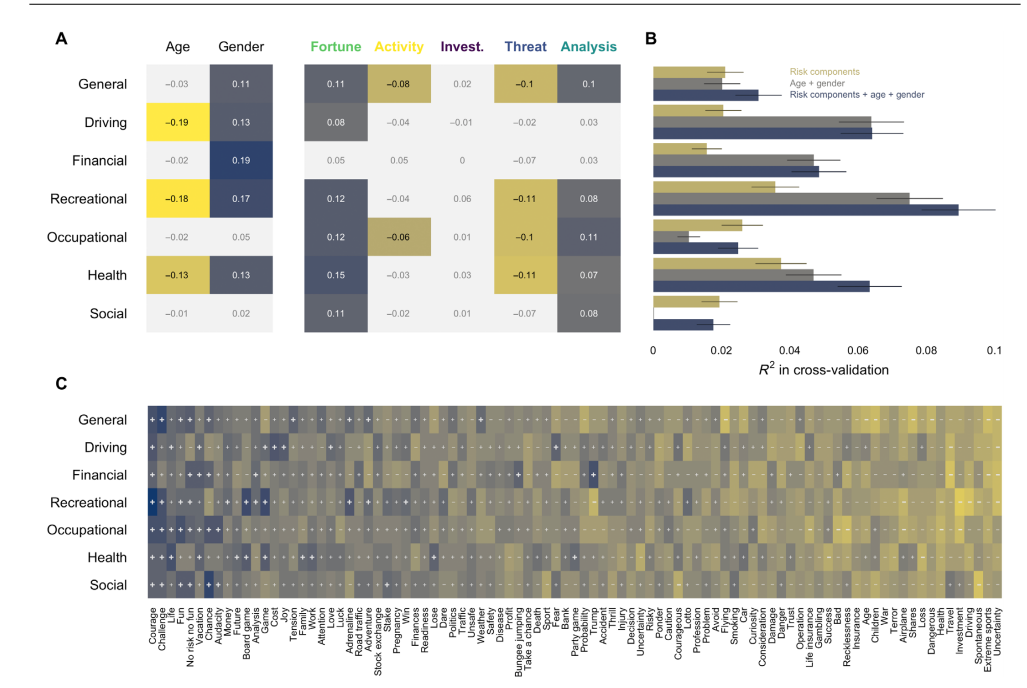
总的来说,这项研究发现风险的语义表示具有普遍特征,但在不同年龄和性别之间存在一些系统性差异。此外,风险的语义表示与个体的风险承担倾向之间存在关联。