文献:Edwards, K., & Low, J. (2019). Level 2 perspective-taking distinguishes automatic and non-automatic belief-tracking. Cognition, 193, 104017. https://doi.org/10.1016/j.cognition.2019.104017
研究背景 ¶
信念推理与视觉观点采择也有逻辑上的相似之处,因为两者都涉及到如何表征和整合物体、场景或事态是如何被经历的,从而产生不同的印象。 了解信念和视觉视角支持我们对他人行为的推断,同时承认不同人对特定事物的不同模式,此特征使这种过程具有认知灵活性,也使得读心术缓慢而费力。 另一方面,人们也普遍认为,读心术必须具有认知效率,才能在快速变化的社会交往中发挥作用。考虑到这些紧张关系往往不会在认知系统中同时发生,如果对可以自动处理的输入类型有标志性限制,那么读心术过程在计算上是有效的。
关于信念推理的自动性,有一系列相互矛盾的发现: 一方面,测量偶然错误信念任务中不可预测的探测问题的反应时间的研究表明,成年人可以知道某人在想什么,但这不是自动执行的事情(Apperly, Riggs, Simpson, Chiavarino, & Samson, 2006;Back & appery, 2010)。 成年人对询问代理人对物体所在位置的信念的探针的反应时间比他们对有关物体实际位置的探针的反应时间要长(apely et al.2006)。当成年人被明确指示要跟踪特工对目标所在位置的信念时,他们回答信念问题的速度和回答现实问题的速度一样快。
也有一致的证据表明,成年人在对他人信念(Birch & Bloom, 2007; Keysar, Barr, Balin, & Brauner, 2000; Keysar, Lin, & Barr, 2003)做出判断时很难克服自我中心偏见,而认知负荷的增加或执行功能的降低会阻碍他们的推理(Apperly, Back, Samson, & France, 2008; Bull, Phillips, & Conway, 2008; McKinnon & Moscovitch, 2007; Rowe, Bullock, Polkey, & Morris, 2001)。 另一方面,也有证据表明信念推理可以自动进行(Schneider, Bayliss, Becker, & Dux, 2012; Schneider, Nott, & Dux, 2014; Schneider, Slaughter, & Dux, 2017),以至于人们自己的行动选择可能会受到他人信念的影响( van der Wel,Sebanz,& Knoblic)。研究还表明,计算他人的视觉观点有时是自动的,但并不总是自动的。
视觉空间视角加工存在不同的形式: 一级观点采择( Level 1 Perspective-take,L1PT )涉及计算某人注视时看到的内容,可以使用视线信息进行处理。 更高层次的二级观点采择( L2PT ),需要理解一个实体是如何被欣赏的,L2PT能力的特点是涉及到视角对抗,这需要在一个单一的表征中整合两个人如何从不同的角度看待同一物体,从而得出不同的和矛盾的描述。L2PT所涉及的不仅仅是跟踪其他人所看到的东西,而是在脑海中构建和保持一个元关系( meta-relation),这个元关系集成了两个不同的人同时在上级观点下对同一事物的不同表示。 L2PT涉及观点对抗,可能是有效读心过程自动性的核心标志限制,而L1PT (例如,在物体位置错误信念任务中追踪关系态度,或者在点数任务中追踪可见性)则是潜在的刺激驱动和目标独立。
几项研究表明,人类不会自动计算一个物体在不同视角下的不同表现(Hamilton & Ramsey, 2013;Surtees, Butterfill, & Apperly, 2012)。根据Apperly和Butterfill的双流程描述(Apperly & Butterfill, 2009;Butterfill & apely, 2013),这些明显矛盾的发现表明,在到达他人的心理状态时,涉及两个相对不同的过程:高效的读心过程和灵活的读心过程。高效的读心过程使用简单的相关态度如registration,而不是复杂的propositional命题态度如信念来预测他人的行为,这样做对中心资源的需求最小,是快速和自动的。
双过程解释的一个基础预测是,有效读心过程的标志性限制来自这样一个事实,即只有对象object及其与施动者agent的关系才能被自动计算以预测他人的行为,这反过来意味着涉及数字一致性的错误信念不能通过表征配准(representing registrations)来归因。有支持性证据表明,成年人会自动计算人们对物体位置的错误信念,但不会计算其数字一致性(Edwards & Low, 2017; Fizke, Butterfill, van de Loo, Reindl, & Rakoczy, 2017; Low, Drummond, Walmsley, & Wang, 2014; Low & Watts, 2013; Mozuraitis, Chambers, & Daneman, 2015; Oktay-Gür, Schulz, & Rakoczy, 2018)。但双过程解释尚未完全阐明区分自动但严格的有效读心过程的标志性限制的边界。在数字上表示对象的表征错误可能不是区分有效和灵活读心过程的主要标志。
本研究 ¶
本研究创造了一个新的范例,将信念-归因和视角化结合起来,描绘了自动读心操作的标志性限制的边界。研究使用物体检测范式来测量成年人在需要或不需要整合对比视角的任务中,在多大程度上受到被动旁观者信念的自动影响。
在L1PT任务中,作者预测旁观者对特定物体存在的信念将有助于调节成人在探测该物体存在时的反应时。 在L2PT任务中作者期望发现,当旁观者对特定物体存在的信念依赖于旁观者在空间中的位置时,成年人的反应时不会加快。如果旁观者信念的促进作用延伸到L2PT任务中,涉及观点对抗,那么双过程的解释可能是不准确的,人类反而有一个环境(context)敏感的单一读心过程。
实验2中是L1PT任务的单球版本,以确定本研究的设计修改仍然会产生在对象检测任务的典型版本中看到的关键发现:当只有代理相信物体会出现时,对物体出现的反应速度加快。
实验一: ¶
被试: ¶
使用G * Power 确定需要至少33名参与者的样本量来检测标准化效应量。共有54名成年参与者,由威灵顿维多利亚大学的心理学研究计划( IPRP )提供,并签署了参加这项研究的协议。
刺激: ¶
所有刺激和指示均通过prime 2.0呈现。每个人在对象检测范式中总共观看了80个视频:L1PT任务有40个视频,L2PT任务有40个视频。为控制总实验长度,使用Adobe Premiere Pro加速120%来减少每个视频的持续时间:每个L1PT视频的长度缩短到13.2秒,每个L2PT视频的长度缩短到17.8秒。
L1PT视频: ¶
视频开始时,agent坐在桌子前,面对参与者。在桌子上,agent和参与者都能看到两个固定的同质球(一红色一蓝)和两个木制屏幕。
在第一个动作中,两个球同时在两个屏幕之间移动,参与者和agent都看不到。在这一运动之后,视频中的事件发生了变化,形成了四种信念诱导条件。具体通过操纵球的运动和改变agent离开场景的时间来诱发预期。agent返回场景标志着最后一个阶段的开始,在此阶段有两种可能的结果:当屏幕迅速脱落时,出现蓝色球或红色球。为了清晰和高效,本研究的四个条件( P + A + , P-A- , P + A- , P-A +)仅与蓝色结果比较(表1a中试验1、3、5和7),具体如下:
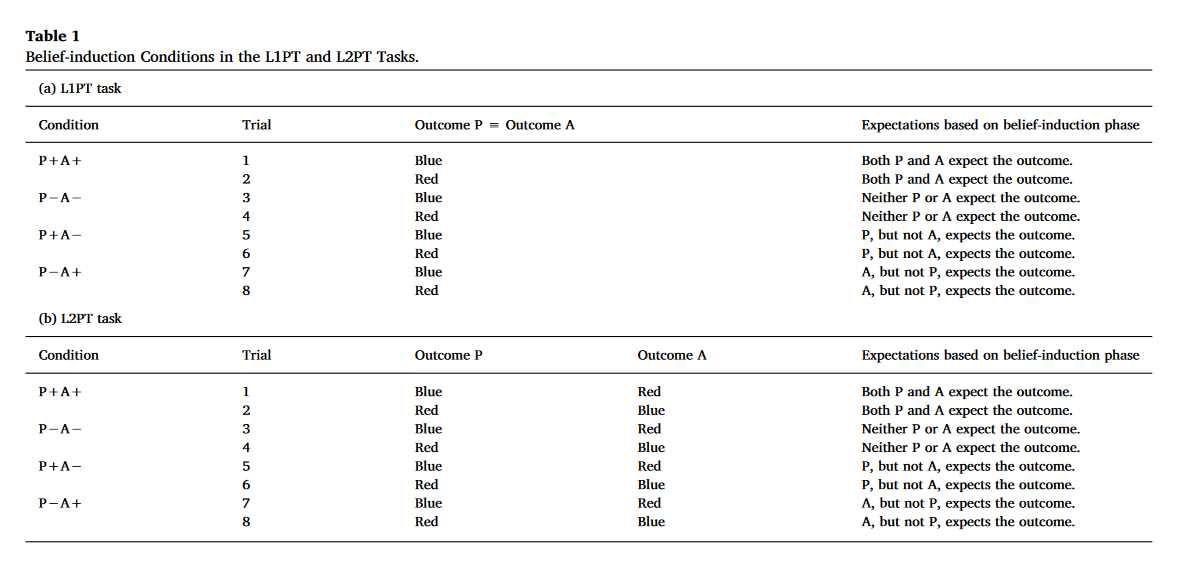

P+A−:参与者和agent都看到蓝色球离开现场。但当红球离开,蓝球再回到屏幕之间休息时,agent不在场。在这种情况下,参与者预期蓝色球留在屏幕之间,而agent预期红色球留在屏幕之间
P−A+:当红球离开现场时,agent在场,但agent没有目睹蓝色球离开和红球返回。在这种情况下,参与者预期红色球留在屏幕之间,而agent预期蓝色球留在屏幕之间。
L2PT视频: ¶
L2PT视频尽可能与L1PT视频匹配。每个视频开始时,视频开始时,agent坐在桌子前,面对参与者。但桌子上不是两个球,而是一个机器狗,一面是蓝色,另一面是红色(见图2)。机器狗的这个双重性质在每个视频开始时向参与者和agent揭示:逆时针转了两次180度,然后在屏幕后面进行了最初的移动。
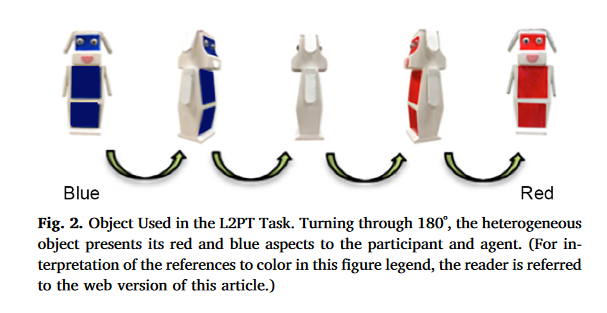
图4展示了狗-机器人的初始旋转运动和它在屏幕(对所有条件都是共同的)之间的第一次运动之后的关键信念诱导事件。由于客体的双重性,参与者和代理者在结果阶段期待不同颜色时的信念是一致的。如,在P + A +条件下,参与者和智能体都期望最终结果(蓝色面向参与者,红色面向agent),在最后一次运动中,机器狗的蓝色面被呈现给参与者,从而使参与者相信蓝色面会在结果中显示出来。在agent看来,机器狗的红色面会在结果中显示出来。
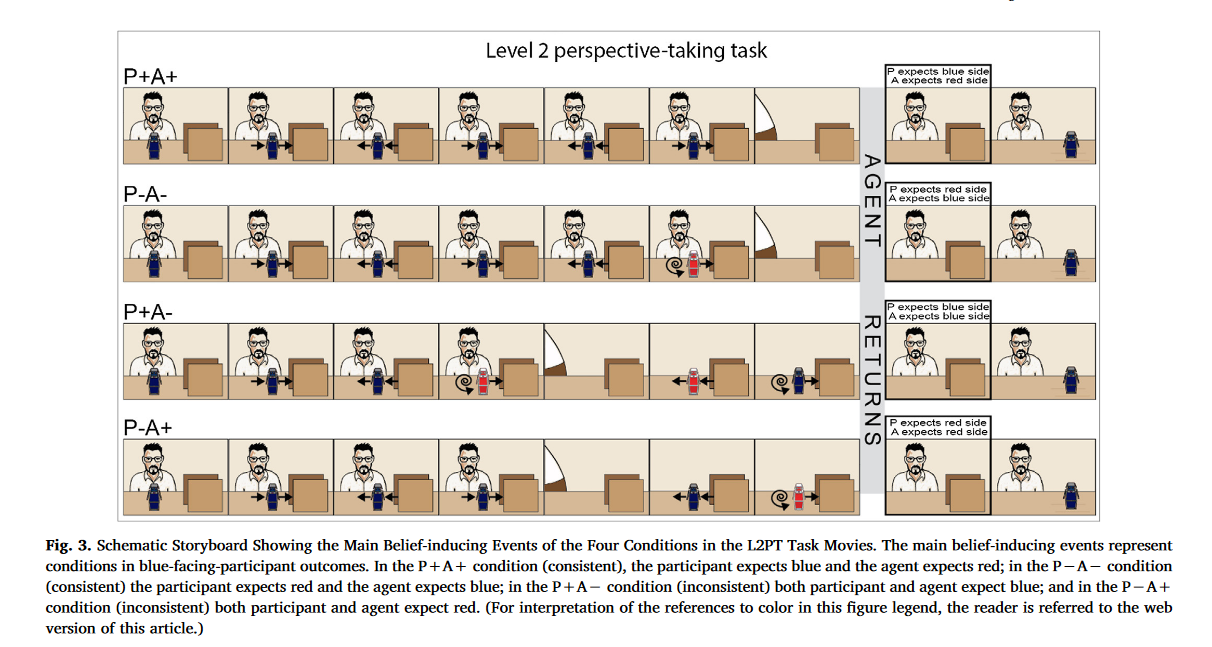
最后,在P−A+条件下,agent预期的最终结果是蓝色面向参与者,因为他最后看到机器狗的红色面进入屏幕。但参与者在agent不在的情况下看到机器狗又出现了,转向向参与者展示它的红色面,然后回到屏幕后面。
P-A +条件的事件诱导了agent而非参与者对结果的预期。
程序: ¶
参与者都坐在一台戴尔Optiplex 9020台式机前,屏幕为23英寸(16:9宽高比)。参与者通过屏幕上的指示来完成每个任务。初始屏幕显示,“这是一个目标检测任务。你的任务就是当你看到挡板后出现物体时,尽快按下一个键。”
L1PT的任务说明如下(除了括号中的信息外,L2PT的任务说明是相同的):“在实验的前半部分,你将看到40个视频,总共持续约10(15)分钟。它们看起来是这样的(提供相关的视频帧)。在每个视频中,这个人都会离开现场,然后再回来。当对方完全离开现场后,用左手按“Q”键。当挡板消失时,用右手做以下操作之一:如果显示蓝色,按“N”键;如果显示红色,请按“M”键。
每个试次包括一个初始注视点交叉( 1000 ms ),然后是视频。
对于每个任务,40个测试试验以伪随机顺序在两个块中呈现。第一个区块包含24个试验,包括四个不同条件的三个周期,结果为红色或蓝色。在休息之后,参与者经历了另一组16次试验(两个循环,有四种不同的情况,结果有红色或蓝色)。
在训练阶段,参与者要进行4次有反馈的练习试验。在测试阶段没有给出表现反馈,以尽量减少试验时间和分散注意力。
整个实验总共耗时约30分钟。实验结束后,参与者被要求填写一份表格,回答相关问题(如,“你觉得找到合适的时间段容易吗?……“实验者在测试什么?”)
结果: ¶
所有统计分析均使用IBM SPSS Statistics 23 (SPSS Inc., Chicago, IL, USA)进行。对正确的回答进行分析,定义为参与者检测到与所显示的物体相匹配的颜色。
删除了每个任务中高于或低于参与者总体平均值大于3个标准差的所有数据点。对反应时间数据进行了对数变换,以符合方差分析的假设。正文中报告的所有均值和标准差都描述了对数转换后的数据。
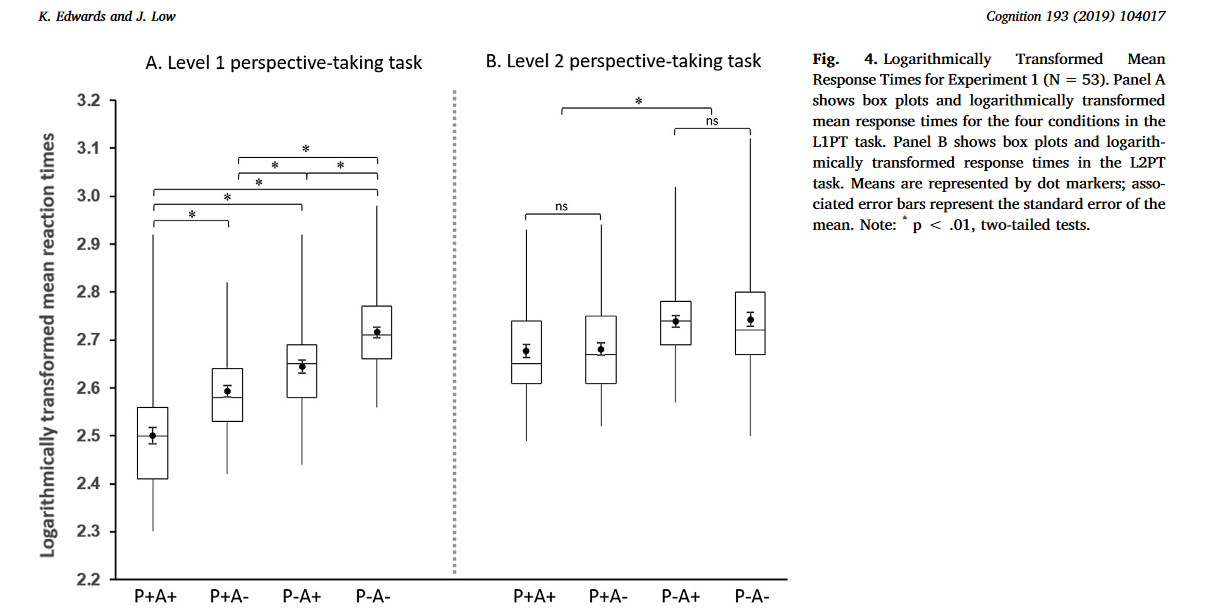
根据Kovács等人(2010)的分析,作者最初比较了不同条件下的反应。没有理论依据表明结果阶段中目标的颜色(蓝色或红色)会影响反应,因此执行了2(任务:L1PT, L2PT) x2(顺序:L1PT优先,L2PT优先)× 4(条件:P+ a +, P+ a−,P−a−)混合模型方差分析。发现了Task的主要效应:L1PT任务的反应时间(m= 2.61, sd = 0.13)显著快于L2PT任务的反应时间(m=2.71, sd = 0.10)。
L1PT任务:
单因素方差分析显示,不同条件下的反应时间差异显著。P−A+条件下的反应时间明显快于P−A−条件,t (52) = 11.60,p < .001;措施。反应模式如图4A所示:被试在P+A+条件下反应最快,在P−A−条件下反应最慢;P+A−组的反应速度明显快于P−A+组。这些发现表明,在L1PT任务中,反应速度受到参与者和旁观者的信念的调节。
L2PT任务:
单因素方差分析显示,每个条件下参与者的反应时间不同。经bonferroni校正的两两比较表明,在P−A+和P−A−条件下,反应时间没有差异(P = .689),这支持了本研究对这项任务的主要假设。如图4B所示,反应模式与L1PT任务不同。在L2PT任务中,P+A+和P+A -条件之间没有差异,P−A -和P−A+条件之间没有差异,这表明参与者不受旁观者信念的影响。
此外还发现,参与者在P+情境下比P-情境下反应更快,这通常被称为现实偏差,这表明参与者参与了每个试验的事件,并利用它们来预测结果,而不是只是等待挡板落下来做出颜色选择。(在两个任务中都观察到现实偏差)
实验二: ¶
被试: ¶
60名右利手成人,其中39名为学生,21名为成人志愿者。其中女性38例,男性22例,平均年龄21.88岁。
刺激: ¶
采用与实验1相同的显示参数,使用E - Prime 2.0呈现刺激和指令。每个个体观看40个短视频作为目标检测任务的一部分。每个视频长度为10 s,(在Adobe Premiere Pro中将原始图像加速120 %后)。
与实验1一样,视频开始时,agent坐在一张桌子旁(桌子上有两个挡板),面对参与者。与实验1中显示的视频不同的是待检测的物体是一个黑球。在第一个动作中,球在两个屏幕之间移动,这样参与者和agent都看不到它。在这一运动之后,视频中的事件发生了变化,形成了四种信念诱导条件。
预期是通过操纵球的运动和改变agent离开场景(在关键事件发生前或发生后)的时间来诱导的。agent返回场景标志着最后一个阶段的开始。在最后阶段有两种可能的结果:当挡板迅速脱落时,球要么存在,要么不存在。因此,参与者经历了8种试验类型,包括四种信念诱导条件和两种可能的结果之一。
程序: ¶
和实验一相同,但当挡板消失时,用右手做以下操作之一:如果球出现,按“N”键;如果球不在,按“M”键。
结果: ¶
在每个任务中,删除了高于或低于参与者总体平均值大于3个标准差的所有数据点。
我们进行了2(结果:有球,无球)× 4(条件:P+ a +, P+ a−,P−a +, P−a−)重复测量方差分析。结果与条件之间存在显著的相互作用。事后测试表明,关键预测得到了支持:与agent和参与者都不预期球出现(P−A−)相比,只有agent期望球出现时(P−A+)的反应时间明显更快,t (59) = 7.83, p < .001。
当期望球出现时,当参与者和agent的信念都与结果相符时,反应最快,而当双方都没有被诱导期望结果时,反应最慢。与该研究的理论基础一致,不仅当只有参与者期望结果时,他们检测球的速度比基线条件(P−A−)快,而且当只有agent期望球存在时,他们的速度也比基线条件快。