论文信息: ¶
DeLong, K.A., Urbach, T.P., & Kutas, M. (2005). Probabilistic word pre-activation during language comprehension inferred from electrical brain activity. Nature Neuroscience, 8, 1117-1121.
论文原文 ¶
摘要 ¶
尽管在许多动物物种中有大量微观或宏观水平的先知过程的事例,但对具体单词的预测在实时语言处理中起着不可或缺的作用仍有争议。本研究利用英语不定冠词的发音规则[不定冠词“an”位于以元音开头的名词前,而不定冠词“a”位于以辅音开头的名词前]并结合来自人脑事件相关脑电位的记录显示出大脑在一定程度上能以等级方式对个别单词提前激活,每个单词都可以用一个离线句子片段的延续的概率进行估计。这些结果就是读者可以利用一句话中的一些单词(作为对其世界知识的提示)去估计下面会用哪些单词的相对似然性。
一、引言 ¶
自 20 世纪 70 年代以来,人们普遍认为句子处理是连续的和递增的,临时的承诺会暂时解决语言的歧义,因为每个词的出现都经由其处理,并迅速融入到句子的表达中。 最近,一些研究人员提出了在句子处理过程中产生预期的预测能力,但事实证明很难将预测与整合区分开来。
N400 成分(探测点后 200-500 毫秒)是对有意义单位的自然反应,他的波幅对于词频、可接受度、和具体性等因素比较敏感。N400 的敏感性与离线语义预测有关,但是研究者很难决定N400 波幅的变化与在线加工所对应的名词,实时句子加工意味着理解则使用语境来预测接下来的词(预测的观点)或者是他们是否被单词强迫投入更多或更少的资源来将词语融入到句子的表达(整合的观点)。
最近的一些 ERP 和眼动的研究已经证明了由语境产生的对即将出现的单词的语义或句法特征的预期。然而暂时还没有能证明句法结构良好的句子中特殊的单词形式的语境整合。 最后,研究者设计了实验,利用英语中的发音规律,将语义为“某一……”的不定冠词从发音上认为是在元音开头的明天前的、“an”,或者是辅音开头的名词前的“a”(例如:‘an airplane’ 和 ‘a kite’)。为了探究在特殊的冠词与名词出现前是否大脑就进行了预测,研究者设定了一些限制,让被试对特定的元音或辅音起皱的名词有一定的期望。在实验语料中,目标名词的选择是给予离线完型可能性规范,范围从非常可能到不可能。例如:已知句子“The day was breezy so the boy went outside to fly…”最有可能,后面应该接“a kite”(填“a”概率=86%,“kite”=89%)。然而,句子后面也可以接似是而非的单词,例如“an airplane”。基于前人的研究,研究者知道 kite 诱发的 N400 波幅比 airplane 的要小,名词 N400 的波幅与万次那个可能性成反比。kite 和airplane 在语义上有差别,a 和 an 却没有只有从语音上才能去分出来。
如果预测是语言处理的一个组成部分,那么它应该反映在大脑活动中,或多或少被不定冠词所探测到。如果预测的数量是严格按照单词的长度或频率来驱动的,那么无论 ERP 效果如何,它都是语境无关的,所有的例子都是 a 的(相对于 an)模式。即使预测是与语境相关的,大脑可能会对预期的冠词作出反应,以二进制的方式,而不是以一种分级的方式对其他任何东西作出反应。最后,研究者假设语言处理器利用语境来预先激活可能的延续性,与基于约束的模型一致。如果是这样的话,N400 应该与能从冠词的离线完型可能性中预估出的某种程度相关。
二、材料和方法 ¶
2.1被试 ¶
23 名被试(女性)英语母语者;右利手;视力正常或矫正后正常;年龄在 18-37 岁(平均 21 岁)。其中有 7 名被试报告有家族左利手情况。
2.2材料及设计 ¶
实验语料是 80 个含有两种目标类型的语境:高预期的和低预期的冠词/名词组。每个冠词/名词组在不同的语境中都有高和低两种预期目标。目标句全是中立的(没有诸如“a airplane”这样的一致性违反)。这 160 个句子分为两组,每个被试只做一组材料。每个句子语境和冠词/名词在每组中只出现一次。每组中高预期和低预期目标(a; an)的数量是一致的。1/4 的句子后面出现是非问问题,被试回答的平均正确率为 94%(从 88-100%)。 实验被试不参与冠词和名词语料的判定,参与判定的志愿者和 ERP 被试均签订知情同意书。冠词的判定方法是 30 名志愿者对 80 个截断的句子语境进行完型评分。名词的判定方法是在目标冠词后句子被截断,进行完形填空。两种语境一共 160 个句子:一种是提供了高预期的冠词;一种是低预期的冠词。每个志愿者仅仅看一个类型,每组 30 名志愿者。
2.3程序及分析 ¶
被试一次完成实验,句子呈现在屏幕中央,逐词呈现(持续 200 毫秒,SOA 为 500 毫秒)实验指导语为让被试理解句子,然后回答是非问句问题,右手作答。 EEG 数据使用 Electro-cap 记录 26 个电极点,参考电极为左侧乳突。眨眼和眼球运动由置于眼睛上下和外侧的眼电记录。电极阻抗保持在 5Ω 以下。EEG 数据由 Grass 放大器采集,带通从 0.01-100Hz,采样率持续在 250Hz。
在平均之前,研究者将眼球运动,过度肌肉运动和放大器阻滞的试次删去,有 10.7%的冠词和 11.4%的名词被删掉。过度的眨眼使用空间滤波法进行校正。在所有数据中都使用了从0.2 到 15hz 的数字带通滤波器,以减少高频噪声。在离线情况下,每种条件下的数据重新用左右乳突重新参考和平均,时间锁定在目标冠词和名词触发时。
三、结果 ¶
3.1行为结果 ¶
我对所有的冠词和目标名词进行了离线可能性调查,要求参与者在冠词或名词前提供最好的连续句子。冠词完型从 0-96%,名词的完型从 0-100%。这些广泛的预期范围可以分析ERP 效应与相关延续的离线概率之间的相关性。在 ERP 实验中,不同的被试阅读不同语境约束的其中包括完型中的目标冠词和名词的句子。在不同的被试中,相同的句子语境同时出现了高低两种概率的冠词和名词。虽然一些延续性比其他的更有可能,但没有一种是荒谬的,除非被试发展出一种策略(有意识或无意识),从而将布套可能的冠词当作一种即将到来的语义异常。
3.2ERP记录与分析 ¶
为了考察大脑预测效应的活动,研究者记录了 32 位被试头皮上 26 个电极点的脑电数据,被试要求以 2 词/秒(呈现时间 200 毫秒)的速度,逐字阅读显示器上出现的句子。研究者队160 个句子中的目标冠词和名词进行分析,160 个冠词和名词分成了 10 个等宽的 bin,作为每个项目的完型可能性,从高(90-100%)到低(0-10%)。每个 10%的 ERP 显示组内分析,然后组件分析。然后分别计算出每个 bin 的平均数值完型概率,并与 N400 时间窗口(200-500ms)中的平均 ERP 波幅分别对应。分别计算出 26 个电极点的相关系数(r-values)和由离线可能性解释的方差百分比(r²)。
3.3N400效应和相关性 ¶
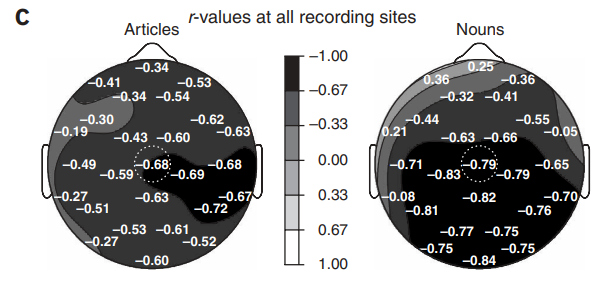
正如研究者预期的一样,N400 的波幅降低(变得不那么负),因为名词化的可能性增加了 (图a)。实验结果复制了众所周知的目标名词的 N400 幅值与离线完型之间的相关性(图b)。在不同的电极点上,相关度系数为范围从 r=0.36(没有差异)到 r=-0.84(P<0.001)(图c)。在名词出现后,在 200 - 500 毫秒之间的大脑活动中,名词完型概率达到了 71%。相关性在后置位点上达到峰值,振幅通常是最大的,而前部(视觉 N400s 通常不那么普遍)显示了几乎没有任何证据表明相关的大脑活动(图 c)。这些结果是对冠词进行分析的重要前提,因为它们证明了这些材料中不同程度的约束反映在离线预期和 N400 波幅模型中。然而,如前所述,名词相关模式并不能解决预测的问题,因为高相关性可以反映出该名词的前激活程度或其可积性的方差。
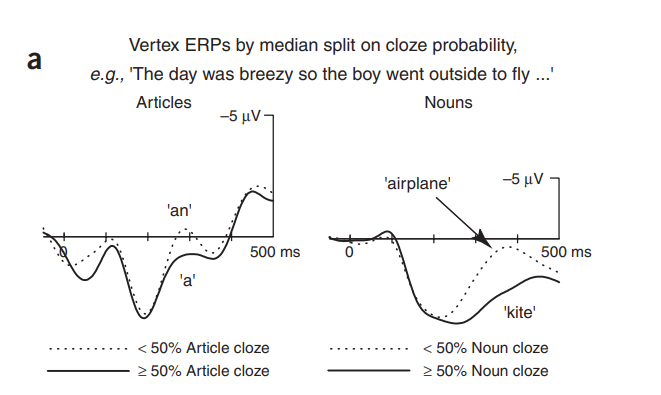
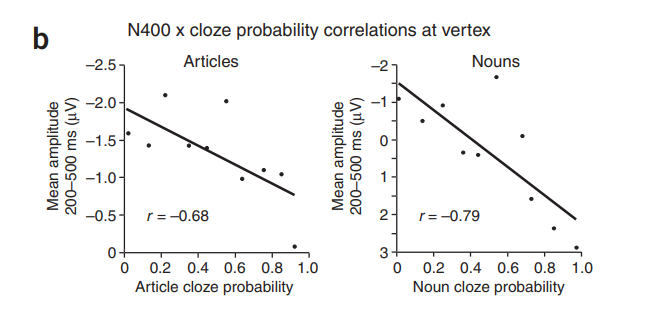
为了直接解决预测问题,研究者转向了目标冠词的相关模式。虽然冠词的 ERP 波可能明 显小于名词诱发的 ERP 波,但是 N400 时间窗口内的负性波幅确实随罐区预测的变化而变化(图 a)。就像名词一样,冠词的完型概率越高,200 到 500 毫秒之间的 ERP 的负面影响就越小(图 b),相关系数范围从 r =-0.19 (不显著) 到 r=-0.72 (P <0.05)(图 c)。此外,最大的相关性集中在中心顶叶的位置上,与名词类似,但是更偏向右边(图 c 和网上补充注释)。因此,至少在某些头皮区域,N400 幅值高达 52%的差异是由个体在离线状态下继续使用句子语境的平均概率来解释的。
四、讨论 ¶
那些以元音和辅音开头的名词通过构建语句的语句来进行各种离线预测,在名词之前加上语音适当的不定冠词或者加上其他在语义上一致、句式上合适但在语音上不适当的不定冠词,能够对这种预测联机形式的程度进行评估。与名词相似,一个不定冠间其语境不确定性越大,词开始后 200-500ms 之间(N400)的 ERP 平均幅值波形越倾向于负波。换句话说,大脑对冠词的反应不同于一个分级的方式,作为语境约束的功能。因此,研究者的研究结果不仅证明了读者可以快速地、渐进地将来词融入到不断变化的心理语句中,而且还可以通过利用各种约束力量来形成对特定词语下一个特定词语的概率预测。本研究对目标冠词和名词清楚地表明了这一点,尽管研究者没有理由假设在正常阅读率范围内,句子中的每一个单词都不会有相同的意思。值得注意的是,名词和冠词两者的最大相关性不会任意地分布在大脑皮层,而是集中在头顶中央头皮(centroparietal scalp)的位置,即以前的阅读研究已表明的 N400 效应最显著的部位(图 1c).
这一分布状况的模式指出这些估值不是 26 个电极位置多种试简单的伪结果。在进行相关性分析的过程中,研究者发现了在冠词开始后 200-500ms 之间由名词和动词有发的典型 N400 所建立的负性功能关系。研究者还证明了这一负极对于诱导性冠词(后续名词)的作用。假定所有的冠词在语法和语义上都和它们的语境相符,冠词“a”和“an”有相同的语义,这样就没有理由为集成到句子表示中选择哪一个冠词类型而有一定的困难。这样,与离线冠词完形概率相比,为 ERP 负振幅中系统变异(systematic variation)提供了强有力的证据。被试预测一个特殊名词的语音形式,因此对一种冠词相对于另一种冠词形成了预期,当更低预测的冠词出现时,就会有加工困难。冠词相对较短,出现频率高,在词类中有较高的可预测性;不像意义丰富的名词、动词、形容词或副词那样,平时阅读常常跳过冠词。除了为词汇特定的预测提供明确的证据外,冠词的相关性还能提供令人信服的证据,即冠词在质量上也能像名词一样被预测并与语境相结合。由于目前还尚不清楚的原因,与离线概率相关的冠词在平均程度上要比名词(尽管在某些电极位置上,这二者在统计学上是相似的)更低。虽然如此,冠词的相关性能够清楚地证明预测不限于高度约束的语境。研究者认为这种预测是实时语言处理构成整体所必需(也许是不可避免)的部分,并可能起到重要的作用,这一点还有待于证明。
研究者的结果显示,被试能够利用语言输人对即将输入的单词在其出现之前进行预激活。确切地说,这些预测以及预测语言处理的神经机制,都是经验和计算研究的重要内容。例如,一个众所周知的问题就是人的语句理解系统是如何控制语言输人速率的变化(例如,2-3.5 词/秒)。尤其这两者是否有同样的(或不同的)机制在起作用。与大多数的理解研究结论相同,在系统输人速率没有变化的情况下,研究者假定基本的语言处理机制在正常输人速率的范围内不会有根本的改变。这一假设得到了 N400 研究结论的支持。这项研究中,速率的变化没有性质上不同的神经机制的参与。尽管目前的研究证明分等级的预测只发生在自然输入速率更慢的末期,但是研究者认为这个结论可以推广到更快的速度上,并且对于自然语音中的二预测(期望的与不期望的)提出上述论点和 ERP 方面的证据。随后的实验无疑将进一步揭示些问题。
研究者认为,一句话中单个词和词组会通过语义记忆来选择和使用不同的激活信息,超出了直接的物理输入(immediate physical input)。假定语义记忆包括个体词汇的信息以及从人物、地点、物和事件经验中建立的世界知识。研究者认为,特定单词形式的概率预激活是由于语言输入所导致的经验知识的获取。而对冠词 ERP 预测效应的观察研究者得出结论:预测可以是针对特定语音形式的——以元音或辅音开头的单词。从这个意义上说,研究者认为预测可以是非常特殊的,至少在某些情况下是如此。
大脑语言的句法分析程序能对即时句子理解任务中的语言处理各个方面进行概率预测, 而这一结论符合日益增多的、以实验为根据的研究。一些研究认为,当一个句子要逐词进行分析时,句法分析程序利用了自然增加的约束因素:(i) 计算语言指示物和视觉的语境中很可能性关系(例如:当一个人听到“eat”这个词时,他会浏览一下周围适宜食用的环境);(ii) 对类别范畴的语义特征进行预先激活(例如,预测一种特殊类型的树要预先激活树的特征,尤其不是在所有的树在句子语境中似乎都正确时);(iii)在逐词阅读和自然语音中预测所呈现素材的各种句法特征(例如:在以词性为特征的语言如西班牙语或荷兰语中预测即将来输入单词的语法上的性)。
尤其,研究者的研究详述了上述语法中的性别,即名词要位于那些语法中的性别标记与“期望的”名词不一致的词的前面。尽管语法中的性别的研究和研究者的研究都用到了同样的普通逻辑,但在实验操作、设计和分析上的差异会导致合理结论的实质差异。然而对西班牙语和荷兰语的研究则分别利用了关于限定词和形容词置于名词之前的(语法)性标记,研究者对探测的冠词和即将出现的名词之间的纯语音(声音呈现)关系进行了研究。对于冠词 ERP 的观察,有力地检验了语言系统是否预测具有特定的音位内容(词位)的词形,而不是简单地表示单词词义和句法特性(小标题,评注)。此外,研究者检验了语义上相同的不定冠词 “a’’/“an”(功能词)的预期,而不是词义更丰富的词(实义词)如形容词。有效地反击了这个论点:在更多与更少可预测的冠词之间所观察的差异反映了对它们解释的困难。最值得注意的是,只有研究者的研究比较了多-或少-可预测的冠词引起的脑活动,而不是简单地对最高与最低期望进行对比。这样对冠词相关性的发现,首次表明了当一个孤立词的表示超出了给定的高约束语境的阈值时,语言系统不会简单地预激活这个单独的词。相反,预激活的梯度表明系统做出了分等级的预测。
研究者的电生理结果在其他几个值得注意的方面扩展了先前的预测结果。首先,他们证明一个候选实体(或其᧿述)不必是实际存在的,以使大脑来缩小可延续的可能性,而预测则是依据句子中的累积形式在联想的基础上出现;其次,研究者的结论表明,至少有一种功能词的子类(通常提供更多的语法结构而不是词汇含义),不定冠词在构建语境和简化语言处理中起着重要的作用。这一发现与语言理解文献中出现的那些关于语义语境对功能词影响的极少量的证据尤其相关。最后,研究者发现清晰地表明预测处理不仅存在于概念特征或意义特征中,而且存在于特殊的语音词形中。总之,尽管自然语言的理解必须通过大量的信息输人和无限数量的可能词的结合才能完成,但这些因素似乎不能阻止大脑对超过实际输人句子最可能延续的预测。在这方面,语言理解似乎涉及在其他生物系统中观察到的预期行为的特殊情况。