论文信息:Sun, Z., Shi, Y., Guo, P., Yang, Y., & Zhu, Z. (2021). Independent syntactic representation identified in left front-temporal cortex during Chinese sentence comprehension. Brain and language, 214, 104907. https://doi.org/10.1016/j.bandl.2021.104907 ¶
论文原文 ¶
关键词 ¶
句法启动范式;中文;句法表征;fMRI
摘要 ¶
在印欧语系中, 句法表征独立于语义表征已经得到了充分的证实,但中文的情况尚不清楚。本实验利用fMRI技术,采用句法启动范式来研究中文句法表征的神经基础。实验设计上根据句子结构构建了启动句对和非启动句对:被动句+被动句;被动句+主动句,均不存在动词及施-受事生命度模式的重复情况。fMRI实验收集了22名汉语母语者的句子阅读数据,在左侧颞极、左额下回以及左中央前回发现了启动相关的激活抑制。该神经影像学结果可作为汉语句法表征和语义表征互相独立的强有力证据。
一、引言 ¶
语言的句法表征是语言神经科学研究的一大焦点。已存在大量证据表明印欧语中句法和语义的表征是互相独立的 (e.g., MacDonald, Pearlmutter, & Seidenberg,1994)。但是汉语既没有明确的句法范畴及特征标记,也没有严格的词序,因而句法语义之间的表征情况存在争议。有必要对“独立性”的神经证据进行深入研究。
前人的句法加工研究多利用违反范式,但他们无法推断汉语的句法表征是否独立。主要存在以下三点原因:①句法违反但语义合理的句子很难找到;②对错误句子的可接受度判断会导致违规检测和自动修复情况的发生;③前人研究集中于语言加工,不等同于语言表征。 基于此,研究者选用了句法启动范式。即每个连续句对中包括启动句和目标句,该范式的优点在于能够检测对句法特性敏感的神经元群体,而非语义、词汇等信息。且已被用于汉语句法独立表征的研究(Cai, Pickering, & Branigan, 2012; Cai, Pickering, Yan, & Branigan, 2011),只是是否有特定脑区的参与,这点尚不清楚。
二、实验材料及方法 ¶
2.1被试 ¶
汉语母语者22人 (10男,18-25岁),一切正常。
2.2设计 ¶
被动句作为实验材料的原因;①汉语被动句与印欧语的被动句类似;②该句型使用较少,可以更可靠地对句法启动范式进行检测。
具体设计:2*2 2(句⼦类型:Prime vs. Target)×2(结构:相同结构 vs. 不同结构) 详见table 1
启动句在经过语义可接受性调查后,无显著差异。
2.3程序 ¶
90对实验句,90个填充句,60个测试句。 4run 单次试验;400ms注视点+100msblank +2000ms句子(按键判断)为保证启动效应的纯度,启动句和目标句之间的ISI 随机抖动0.5s/2s/2.5s.其他句⼦之间的随机ISI抖动0.5 s⾄3.5 秒,步⻓为 0.5 秒,总平均 ISI 为 2 s.
2.4fMRI数据收集及预处理 ¶
使⽤T2加权回波平⾯成像序列,重复时间 2 秒,回波时间 35 毫秒,翻转 90 °⻆度。获得了35个切⽚,体素⼤⼩为 3.5 × 3.5 × 3.5 mm。每个切⽚的视野为 224 × 224 mm。切⽚以交错⽅式按升序获取。使⽤头部和前额带周围的枕头和垫⼦可最⼤程度地减少头部运动。
依次对数据进⾏采集时间校正、头部运动校正、⾼通滤波⾄128 Hz和空间平滑(FWHM = 8mm)。
2.5全脑分析 ¶
在个体分析中,研究者执⾏了⼀个⼀般线性模型,包括四种类型的句⼦(SP、ST、DP、DT)、三种类型的填充词(正确填充词、错误主动句和错误被动句)、错误反应和六个头部运动参数通过头部运动校正获得。开始时间是每个句⼦的开始时间,持续时间是 RT。执⾏典型的⾎液动⼒学响应函数 (HRF) 以拟合模型。将个体数据归⼀化到MNI空间后,采⽤混合效应模型进⾏分组分析,以被试为随机效应变量,条件为固定效应变量。根据之前的研究(Kim, Johnson, Cilles, & Gold, 2011; Zhu et al., 2012),我们通过对⽐句⼦与固定来定义每个句⼦的激活。我们在组⽔平上进⾏了体素⽅⾯的 2(结构:相同结构,不同结构)×2(句⼦类型:素数,⽬标)⽅差多变量分析(ANOVA)。基于低于 0.001 的未校正p值和no<60体素的簇⼤⼩,使⽤ AlphaSim 模拟确定了 0.05 的校正p 。
2.6兴趣区(ROI)分析 ¶
在检测句法重复抑制效果时被认为具有最⾼的统计敏感性(Weber & Indefrey,2009)。选择由 SP 和 DP 激活的共同⼤脑区域作为 ROI,即 LIFG、左中央前回 (LpreCG)、左颞极 (LTP) 和左后颞上回 (LpSTG),这些区域在多个校正中幸存下来根据 AlphaSim 模拟, p = 0.05的⽐较是与先前评论中的句法相关的区(Friederici,2011 年;Hagoort,2013 年)。通过绘制⼀个以峰值体素为中⼼的 6 mm 球体来提取所有 ROI 的信号。
三、实验结果 ¶
行为实验:平均准确率(M = 92%, SD = 2)和 RT (M = 1621 ms, SD = 363)
对于全脑分析中的每种情况,在前颞叶语⾔⽹络中发现了显着的激活(图1),包括 LIFG、双侧前颞回、后中回和颞上回、中央前回和中央后回以及枕颞回回旋。对于全脑分析,在校正p = 0.05 ⽔平的 2 × 2 检查中未发现主要影响或交互作⽤的显著结果。
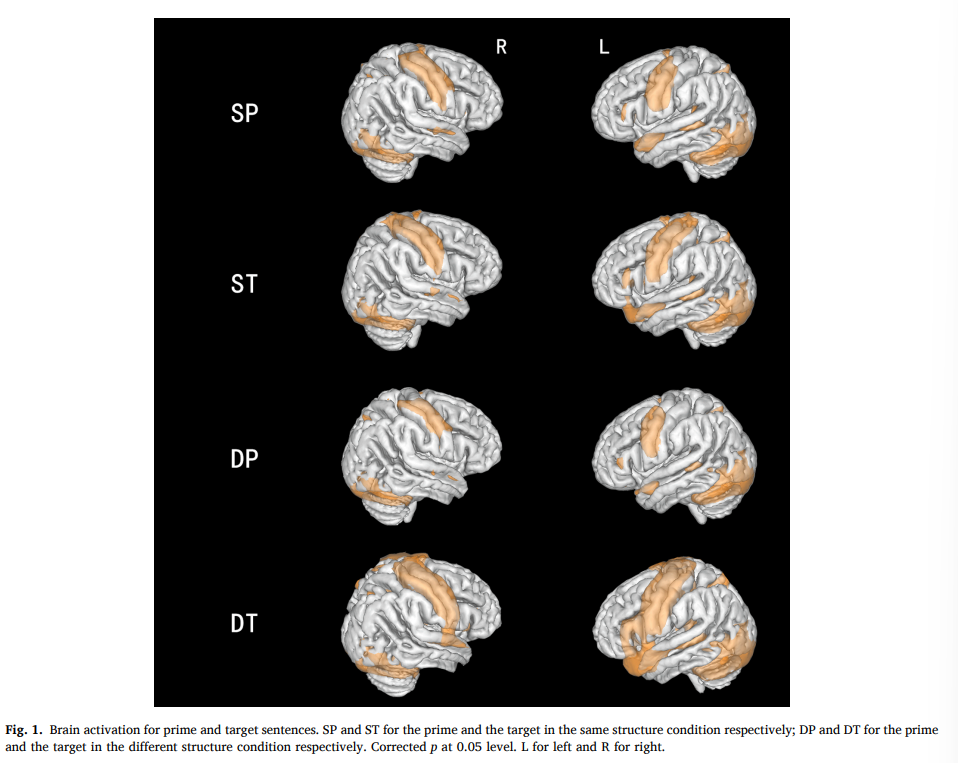
ROI 分析结果(图2)显⽰ST的激活强度低于LIFG中的DT(图2B; t (21) = − 2.31, p < 0.05),LpreCG (图2C; t (21) = − 3.32, p < 0.01) 和 LTP (图2D; t (21) = − 3.19, p < 0.01),但不是 LpSTG (图2E; t (21) = − 1.44, p = 0.17)。
四、结论 ¶
该实验的核心是提供了独⽴的汉语句法表征的神经证据,从⽽扩展了之前关于句法启动的⾏为和 ERP 研究(Cai 等⼈,2012 年;Cai 等⼈,2011 年;Chen 等⼈,2013 年;Huang 等⼈,2013 年)到⼤脑⽪层的定位。 LTP、LIFG 和 LpreCG 区域的重复抑制效应表明,这⾥的神经元群体⽀持句法表征。
本 fMRI 研究采⽤句法启动范式来揭⽰汉语句法表征的神经关联。 ROI 分析在前时态语⾔⽹络中检测到显着的重复抑制效应,特别是 LTP、LIFG 和 LpreCG。结果提供了迄今为⽌最有⼒的神经影像学证据,证明同印欧语系一样,汉语的句法表征——独⽴于语义表征。
五、个人收获 ¶
该fMRI实验设计清晰明了,对本人的主要启示在于实验程序中句子的呈现注意到了ISI的随机性,这有利于保证启动效应的纯度,同样,在EEG/ERP实验中,刺激间隔仍有随机化的必要性,即添加随机(一定范围)时长抖动。这可以避免α振荡与刺激发生锁相的可能,也有助于滤除来自前一个试次的重叠活动(被试对下一个事件的预期会在脑电信号中诱发预期慢波,包括SPN和CNV,这些会污染后一个事件的基线时间窗)。